Intel Software Conference 2010 (Teil II)
-
Intel ISTEP 2010 Software Conference: Barcelona April 13th

Wie jedes Jahr lud Intel auch in 2010 zur Software Conference ein, die diesmal in Barcelona stattfand. Wie bereits 2009 stand alles im Zeichen der Parallelisierung.In dieser kleinen Artikelserie fasse ich einige Vorträge zusammen, soweit die Themen für die Programmierung mit C++ von Relevanz sein könnten.
Performance Tools for Technical Computing
 Dipl.-Inform. Christian Terboven, Deputy HPC Team Lead, RWTH, Aachen University
Dipl.-Inform. Christian Terboven, Deputy HPC Team Lead, RWTH, Aachen UniversityTraditionally, performance analysis tools in high-performance computing focus on the scalability of MPI applications written in Fortran or C/C++. With a growing number of cores per compute node, and an increasing diversity of parallel applications and programming languages, there is a need to address additional aspects. This talk discusses the role of tools for users from computational engineering and science and how the tool ecosystem is evolving on today’s dominating platforms, Linux and Windows.
In diesem Erfahrungsbericht beschreibt Christian Terboven den Ablauf bei der Optimierung von Programmen durch den Einsatz paralleler Bearbeitung.
Die große Frage zu Beginn ist, worauf man bei der Optimierung der parallelen Entwicklung abzielt. Setzt man an bei MPI oder OpenMP, tunt man die Architektur, oder setzt man auf parametrische Arrays.
Beim Einsatz von Highperformancecomputern (HPC) ändert sich das Umfeld, die Jobs auf den Systemen werden immer heterogener, von hoch-parallel bis hin zu hoher Last, und die Applikationen bestehen aus diversen Sprachen, von Matlab bis hin zu den üblichen Programmiersprachen.
Das Tuning eines Programms besteht nach Terboven aus folgenden Schritten:
- Laufzeitanalyse des Programms
- Identifikation der so genannten Hotspots, die die Last im Programm bearbeiten. Dieser Teil sollte zunächst seriell optimiert werden, bevor man neu mit 1) startet.
- Erst jetzt erfolgt die Parallelisierung der Hotspots.
- Nun beginnt die Laufzeitanalyse mit paralleler Laufzeitanalyse
Dafür sind Profiler notwendig, die auch parallele Programmierung unterstützen.
Für eine Analyse wurde eine "2-Fluid-Durchmischung" in C++ programmiert ("DROPS") und untersucht. Sie ist objektorientiert, STL-basiert und benutzt compile-time Polymorphismus.
Folgende Tools wurden untersucht:
- Visual Studio 2008 Profiler
- Intel Parallel Studio: Amplifier
- Intel VTune
Im ersten Schritt soll verstanden werden, was im Programm der kritische Pfad ist, wo also Rechenzeit verbraucht wird und auf welche Jobs gewartet wird. Der Profiler liefert Zeiten für "inclusive samples", also Zeiten, die komplett in einer Funktion verbracht werden einschließlich der Unteraufrufe, und "exclusive samples", also die Zeiten die nur tatsächlich innerhalb der Funktionsaufrufe verbracht werden.
Die Identifikation von Hotspots ist damit aber nicht einfach möglich, mit diesen Tools können viele User Hotspots noch nicht wirklich erkennen.
Bei Intel Parallel Studio existiert eine zusätzliche Hotspot-Analyse, das Tool ist direkt in Visual Studio integriert. Die grafische Auswertung erlaubt einen Einblick in den Bereich des Codes, wo wirklich Laufzeit verbraucht wird.
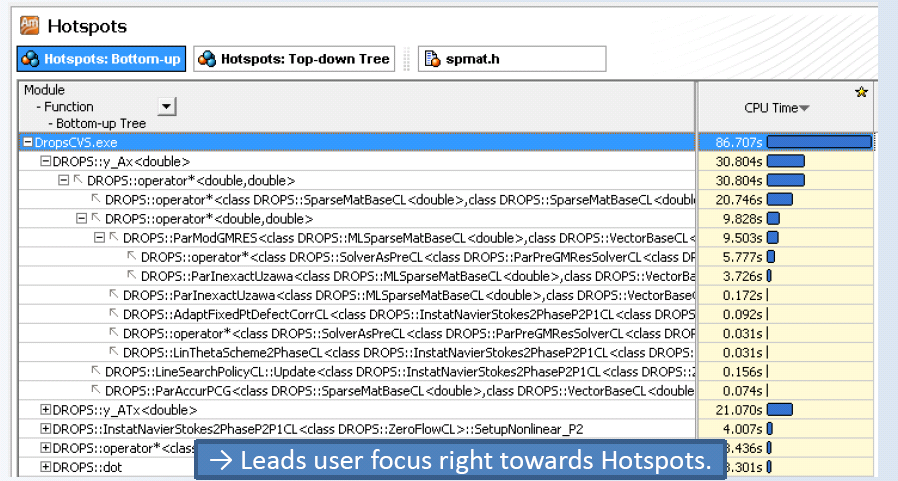
Das Problem ist zu entscheiden, ab welchem Punkt man die Optimierung abbricht – man kann beliebig in die Tiefe gehen, wenn man sich auch um die CPU, die Speicherbandbreite, die Cachelines, etc, kümmert und darauf eingeht.
Solche Optimierungen sind mit Intel VTune möglich, wo man auf CPU-Ebene Laufzeiten messen kann, einschließlich einer grafischen Darstellung der Aufrufe, diese CPU-Informationen werden direkt in den Code zurückgespiegelt und dort dargestellt.
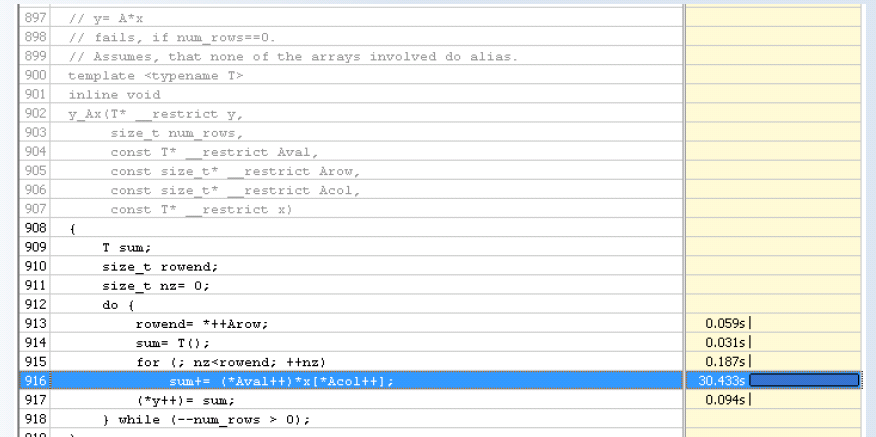
Nach diesem Schritt kann man nun durch Parallelisierung Optimierungen einführen, aber man muß im Auge behalten, welchen Overhead man dadurch erzeugt hat, auch welche Wartezeiten Threads unter Umständen nun haben – vielleicht warten manche Threads ständig auf andere? In diesen Fälllen ist die Parallelisierung nicht ausreichend ausbalanciert.
Mit dem Intel Parallel Studio: Amplifier bekommt man grafisch eine Ausnutzung der Cores durch die verschiedenen Funktionen dargestellt. Weiterhin ist eine Anzeige möglich, welche Threads arbeiten, warten oder sogar frei sind. Auch sind Auflösungen nach der OpenMP-Region innerhalb eines Programms möglich, also wie verhalten sich die parallelen Programmteile.
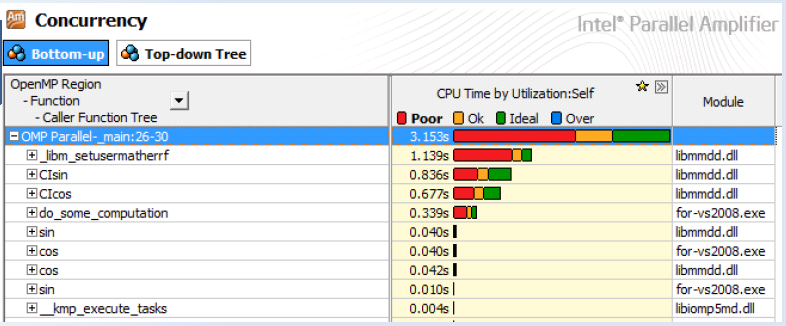
Als weitere Ebene wäre nun zu untersuchen, ob durch die Parallelisierung das Cache-Verhalten negativ beeinflusst wird, oder ob generell der Speicherzugriff ein weiteres Bottleneck darstellt. Dazu muss man aber auf die Ebene der Hardwarecounter zurückgreifen, um dies zu erkennen, was ebenfalls mit VTune möglich ist. In diesem Zusammenhang macht Terboven die schöne Aussage "Parallelisierung ist mehr als nur Tuning von for-Schleifen".
Parallelisierung fügt den potentiellen Fehlermöglichkeiten allerdings noch eine neue und zusätzliche Dimension hinzu – alles was man normalerweise hintereinander richtig macht, kann nun durch fehlerhaftes Warten, gegenseitiges Verriegeln, Data Races und Lastprobleme des Systems plötzlich fehlerhaft werden.
Für Debugging bringt das Visual Studio 2010 bereits gute Unterstützung für Multithreading mit. Für das Visual Studio gibt es DDTlite, das zusätzlich noch die Debugging-Informationen nach Threads gruppiert.
Um einen typischen OpenMP-Programmierfehler aufzuspüren, das Data Race (zwei oder mehr Threads eines Prozesses greifen auf den gleichen Speicher zu und einer der Zugriffe schreibt dabei die Daten), sind komplexere Fehlersuchen notwendig, da der Fehler stochastisch auftritt.
In Parallel Studio gibt es dazu eine spezielle Detektion von Data-Races beim Einsatz von OpenMP.

Mit dem Intel Parallel Studio Composer wird zusätzlich die Möglichkeit eingeführt, Tasks zu debuggen. Dies ist damit der erste Debugger, der OpenMP 3.0 wirklich unterstützt.
Als ganz wesentlich wird dabei nach Terboven die Analyse der Aufrufketten und Zustände der Threads innerhalb des Debuggers betrachtet, da man andernfalls zum Zeitpunkt des Debuggens den Zustand aller Threads nicht mehr im Auge behalten kann. Dabei ist auch erkennbar, was der kritische Pfad beim Aufruf der Funktionen ist, also auf welchem Aufrufweg über die Threads hinweg sich die minimal erreichbare Programmlaufzeit einstellt.
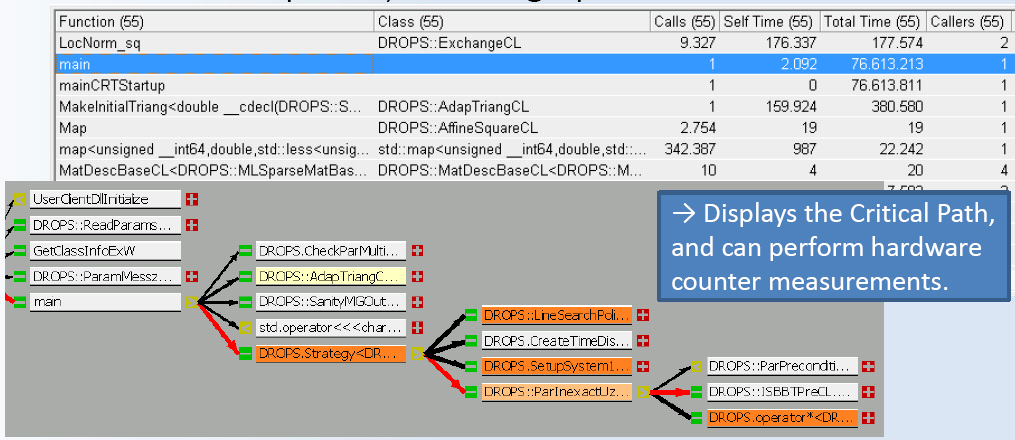
Als Schlusssatz dazu fiel die wunderschöne Aussage "if you have to deal with parallelization you better forget about printf-debugging".
Die vollständige Präsentation: http://softwareproductconference.com/presentations/presentation-barcelona-terboven.pdf