Einführung in Design Patterns
-
Einführung in Design Patterns
Inhaltsverzeichnis
- Vorwort
- Einleitung
- Was sind Design Patterns ?
- Ausgesuchte Design Patterns erklärt
4.1 Das Adapter Pattern
4.2 Das Singleton Pattern
4.3 Das Observer Pattern
4.4 Das Strategy Pattern - Zusammenfassung
- Literatur
1 Vorwort
Dieser Artikel wendet sich hauptsächlich an die Leute, welche noch nie bzw. so gut wie nie mit Design Patterns (deutsch: Entwurfsmustern) zu tun hatten. Wer schon mit Design Patterns gearbeitet hat, wird hier wohl nichts Neues finden. Der Artikel richtet sich also vornehmlich an Anfänger. Allerdings sollten gewisse Grundkenntnisse gegeben sein, die da wären:
- Grundlagenkenntnisse in C++
- Basiswissen über OOP-Techniken wie z.B. abstrakte Klassen und Polymorphie
Das war es dann auch schon, was benötigt wird. Ich werde bei den gegebenen Beispielen zwar noch kurz etwas zur Polymorphie erwähnen. Wer allerdings noch nie etwas von diesen Begriffen gehört hat, sollte sich erst einmal darüber informieren.
Noch etwas zum Schluss:
Zu Design Patterns gibt es zahlreiche Bücher und Tutorials, die sich ausschließlich mit diesem Thema befassen. Ein einzelner Artikel kann und soll auch dieses große Gebiet nicht komplett abdecken. Ziel dieses Artikels ist es, den Leser in das Thema einzuführen und vielleicht auch die Lust nach mehr zu wecken. Daher sei hier schon mal auf die Literaturliste am Ende des Artikels verwiesen.Die gezeigten Implementierungen sind keineswegs optimal und auch der C++-Code ist nicht ideal. Es ging mir darum, die grundlegenden Prinzipien so einfach wie möglich darzustellen - ohne großes Drumherum und spezifischeren C++ Code. Auch die gezeigten UML-Diagramme sind so einfach wie möglich gehalten und deshalb nicht immer zu 100% konform zur UML-Spezifikation.
2 Einleitung
Vor der Ära der objektorientierten Programmierung wurden Programme fast ausschließlich prozedural entwickelt. Eine herausragende Eigenschaft, die durch die Einführung des objektorientierten Ansatzes geschaffen wurde, war die, dass komplexer Programmcode nun viel besser und übersichtlicher gegliedert werden konnte. Die Komplexität der zu entwickelnden Programme stieg jedoch an und es mussten neue Techniken her, um im Code die Übersicht zu behalten. Ein Beispiel dafür ist die STL (Standard Template Library). Diese soll den Programmierer entlasten, indem sie ihm Komponenten für sich ständig wiederholende Aufgaben, wie z.B. die Verwaltung von Daten in Listen, abnimmt. Dadurch kann sich der Entwickler auf die tatsächliche Funktionalität seiner Anwendung konzentrieren.
Ähnlich zu diesem Ansatz hat sich in den letzten Jahren eine weitere Technik etabliert, die es einem erlaubt, vordefinierte und bewährte Muster zu verwenden. Jedoch ist der Scope ein ganz anderer. Man kann komplette Programmteile mit diesen Mustern substituieren, was dem Programmierer eine enorme Zeitersparnis und eine geringere Fehleranfälligkeit einbringt. Diese Muster nennt man Design Patterns oder auch Entwurfsmuster.3 Was sind Design Patterns ?
Kurz und bündig: Design Patterns sind bewährte Lösungen zu bekannten, häufiger auftretenden Problemen in der Softwareentwicklung.
In der Vergangenheit kristallisierten sich einige Probleme heraus, die häufig und vor allem auch in verschiedenen Zusammenhängen auftraten. Zu diesen Problemen wurden viele Lösungen entwickelt; es wurden aber nur die besten Lösungen angenommen. Eine solche bewährte Lösung ist ein Design Pattern. Ein Entwurfsmuster ist immer kontextunabhängig, d. h., man kann ein und dasselbe Design Pattern z. B. sowohl in einem Computerspiel als auch in einer Tabellenkalkulationsapplikation verwenden.
Hier zur Motivation ein paar Vorteile von Design Patterns:- Zeitersparnis: Durch die Wiederverwendung von bewährten Mustern spart man enorm viel Zeit, da man das Rad nicht jedes Mal neu erfinden muss
- Fehlerfreiheit: Man kann sich sicher sein, dass ein Design Pattern frei von Fehlern ist
- Gemeinsame Kommunikationsgrundlage: Auch andere Entwickler kennen Design Patterns, was zu einem gemeinsamen Verständnis und zu einer besseren Kommunikation, insbesondere in größeren Projekten, führt
- Sauberes OO-Design: Durch das Erlernen von Design Patterns wird man mit der Zeit auch ein besseres Verständnis für objektorientierte Designs erlangen
4 Ausgesuchte Design Patterns erklärt
4.1 Das Adapter Pattern
Bei dem ersten Pattern, das wir betrachten wollen, handelt es sich um das Adapter Pattern. Dieses Muster ist weit verbreitet und es kann gut sein, dass einige Leser es schon angewendet haben, ohne dies genau zu wissen.
Es kommt oft vor, dass ein Client (z. B. eine Klasse) auf eine andere Klasse zugreift und von dieser Klasse eine bestimmte Schnittstelle nach außen hin erwartet. Jetzt kann es aber vorkommen, dass diese Klasse zwar die vom Client benötigte Funktionalität anbietet, aber nicht die erwartete Schnittstelle besitzt, sondern eine andere. Das ist der Punkt, in dem das Adapter Pattern ins Spiel kommt. Das Adapter Pattern erlaubt es, verschiedenen Klassen trotz "inkompatibler" Schnittstellen zusammenzuarbeiten. Ein vielleicht geläufigerer Begriff für dieses Entwurfsmuster ist der des Wrappers. Am einfachsten lässt sich dies an einem Beispiel nachvollziehen.
Nehmen wir an, dass wir in einer Firma an einem Projekt arbeiten und die Funktionalität benötigen, verschiedene geometrische Figuren zu zeichnen (ja ja, sehr realitätsbezogen, ich weiß). Wie gehen wir nun vor? Als brave Entwickler definieren wir erst einmal eine abstrakte Basisklasse Shape und von dieser leiten wir dann die konkreten Klassen ab. Das sähe dann so aus (UML):
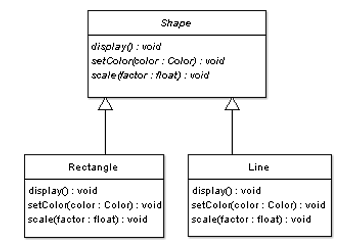
Auch ohne UML-Kenntnisse sollte man dieses einfache Diagramm verstehen. In unserem Programm werden wir ausschließlich mit dem von Shape bereitgestellten Interface (display, scale, setColor) arbeiten und trotzdem die konkreten Methoden von den jeweiligen Objekten (Rectangle, Line) aufrufen können - Polymorphie macht es möglich. Wie das funktioniert, sollte dem Leser klar sein.
Ein möglicher Programmausschnitt könnte folgendermaßen aussehen:... list<Shape*> shapes; Shape* rect = new Rectangle(); Shape* line = new Line(); ... shapes.push_back(rect); shapes.push_back(line); ... //alle gemoetrischen Figuren anzeigen list<Shape*>::iterator iter = shapes.begin(); for ( ; iter != shapes.end; shapes++ ) (*iter)->display(); ....Nun wollen wir als weitere Anforderung auch Kreise in unserem Programm zeichnen können. Glücklicherweise stellt sich heraus, dass schon einmal jemand in der Firma eine Kreis-Klasse geschrieben hat, die uns auf jeden Fall die Funktionalität bietet, die wir benötigen. Wir brauchen also keine neue Kreis-Klasse implementieren. Jedoch sieht die bereits vorhandene Kreis-Klasse so aus:

Die benötigte Funktionalität haben wir also. Da wir aber das bisherige polymorphe Verhalten beibehalten wollen, stehen wir vor folgenden Problemen:
- Unterschiedliche Namen und Parameter: Die Methodennamen variieren mit denen unserer Schnittstelle von Shape. Außerdem gibt es unterschiedliche Parameter (-> scale)
- Vererbung: Diese Klasse ist nicht von unserer abstrakten Basis-Klasse Shape abgeleitet. Damit wäre unser polymorphes Verhalten zunichtegemacht.
Natürlich könnten wir jetzt einfach die breits implementierte Kreis-Klasse umändern, so dass sie in unser Design passt. Das wäre aber ziemlich unschön und fehleranfällig; zudem sollte nur der Autor selbst seine Klassen ändern. Stattdessen wenden wir das Adapter-Pattern an:
Wir erstellen eine neue Klasse namens Circle und lassen diese von unserer abstrakten Basisklasse Shape erben. Die Klasse Circle hat ein Objekt der Klasse AlreadyImplementedCircle als Membervariable. Methodenaufrufe von Circle leiten wir weiter an die Methoden von AlreadyImplementedCircle:class Circle : public Shape { private: AlreadyImplementedCircle* c; public: Circle() { c = new AlreadyImplementedCircle(); } void display() { c->showCircle(); } void setColor(Color color) { c->changeColor(color); } void scale(float factor) { c->scale(factor,factor); } ~Circle() { delete c; } };So können wir einerseits die Funktionalität von AlreadyImplementedCircle nutzen und behalten aber andererseits unsere Vererbungsstruktur mit ihrem polymorphen Verhalten bei.
Das Adapter-Pattern ist trotz seiner Einfachheit ein sehr mächtiges Pattern und kann konsequent angewandt zu flexiblen Klassendesigns führen. Vererbung ist zwar eine sehr mächtige Technik, gleichzeitig aber wohl auch eine der am gefährlichsten. Es ist oft besser eine Klasse durch die Anwendung des Adapter-Patterns in eine Vererbungslinie zu bringen, anstatt die Klasse direkt erben zu lassen
4.2 Das Singleton Pattern
Da das Singleton Pattern relativ häufig in diversen Foren und Büchern genannt wird, wird an dieser Stelle kurz auf das Pattern eingegangen.
Das Prinzip, das dahinter steht, ist eigentlich relativ einfach: Man will erreichen, dass es maximal eine Instanz einer Klasse gibt und dass man auf diese von überall her einfach zugreifen kann. Das sieht dann z. B. so aus:// singleton.h class Singleton { public: static Singleton& Instance() { //das einzige Objekt dieser Klasse erzeugen und als Referenz zurückgeben static Singleton instance; return instance; } void doSomething() { } protected: Singleton() { } //Copy-Konstruktor: Hierdurch werden Kopien dieses Objektes verhindert (da protected) Singleton(const Singleton& other) { } }; //so kann man komfortabler auf das Singleton zugreifen inline Singleton& getSingletonInstance() { return Singleton::Instance(); }Ein paar Dinge, die einem hier auffallen sollten:
- Es ist ein Standard-Konstruktor definiert und dieser ist protected, d. h., man wird diese Klasse weder durch Singleton a; noch durch Singleton* a = new Singleton(); instanziieren können. Zudem wurde explizit ein leere Copy-Konstruktor definiert, welcher ebenfalls protected ist, so dass man auch keine Kopien dieses Objektes anlegen kann
- Die Methode "Instance" gibt eine Referenz auf ein Singleton-Objekt zurück. Über diese Methode kommen wir also an unser Singleton-Objekt. Und da die Methode statisch deklariert ist, gehört sie zur Klasse selbst und kann somit auch über den Klassenbezeichner aufgerufen werden
- Wie man sieht, wird in der Methode "Instance" ein neues Objekt ("instance") dieser Klasse erzeugt. Normalerweise würde dieses Objekt nach dem Verlassen dieser Methode automatisch vom Stack gelöscht werden. Da es aber mit static erzeugt wurde, überlebt dieses Objekt die Zeitspanne des Methodenaufrufs. Genauso wichtig ist es zu wissen, dass dieses Objekt genau einmal erzeugt wird, nämlich beim ersten Methodenaufruf. Bei nachfolgenden Methodenaufrufen wird das Objekt nicht jedes Mal neu erzeugt. Es handelt sich hier also immer um dasselbe eine Objekt, welches dann an den Aufrufer zurückgegeben wird.
Benutzen könnte man diese Klasse dann z. B. so:
#include <iostream> #include "singleton.h" // Die Singleton-Klasse von oben using namespace std; int main() { // Hier wird tatsächlich das Singleton-Objekt in der Instance-Methode instanziiert und zurückgegeben Singleton::Instance().doSomething(); // Hier wird nun einfach das bereits weiter oben instanziierte Objekt zurückgegeben getSingletonInstance().doSomething(); // Adressen des Objektes ausgeben: Diese sind immer gleich, d. h., es handelt sich immer um dasselbe Objekt cout << hex << &getSingletonInstance() << endl; cout << hex << &getSingletonInstance() << endl; return 0; }Welchen Nutzen haben Singletons eigentlich? Es kann vorkommen, dass man globale Objekte benötigt, die überall in jeder anderen Klasse sichtbar sind. Um dies zu verwirklichen, gibt es mehrere Möglichkeiten. Eine Möglichkeit wäre, das gewünschte Objekt zu instanziieren und es dann jeder Methode, die es benötigt, als Parameter zu übergeben. Das wäre aber relativ ineffizient und würde auch nicht unbedingt die Lesbarkeit des Codes erhöhen. Eine weitere Möglichkeit wäre, ein Objekt in einer Quellcode-Datei zu instanziieren und anschließend in den anderen Dateien mithilfe des "extern"-Schlüsselworts darauf zuzugreifen. Aber auch das ist eine unelegante Lösung. Das Singleton Pattern bietet eben genau hierfür die Lösung. Jedoch sollte man sehr vorsichtig mit diesem Pattern umgehen, denn es kann schnell dazu verleiten, die ein oder andere Klasse leichtfertig als Singleton zu definieren (globale Dinge verführen immer ;)), was dann wiederum zu sehr inflexiblen Designs führen kann. Durch seine statische Natur hat das Singleton einige Unzulänglichkeiten:
- Es gibt immer nur eine Instanz. Was aber wenn plötzlich Anforderungen kommen, wonach man verschiedene Zustände in verschiedenen Instanzen unterscheiden muss? Man müsste sein ganzes Design, das bisher auf das Singleton-Pattern fixiert war, umändern
- Was passiert wenn sich mehrere Singletons gegenseitig referenzieren müssen? Dies zu lösen ist nicht gerade trivial
- In puncto Vererbung ist man auch sehr eingeschränkt. Man kann eine Singleton-Klasse zwar vererben, jedoch wird man z. B. kein polymorphes Verhalten erreichen können (statische Methoden können nicht virtuell sein)
- Beim Multi-Threading können ebenfalls Probleme auftreten, was hier aber nicht näher erläutert werden soll, da es sich auch nicht unbedingt um ein singletonspezifisches Problem, sondern um ein allgemeineres Synchronisationsproblem handelt. Dennoch ist es wichtig, dies zu wissen
Man sollte es sich also *sehr* gründlich überlegen, bevor man sich für eine Singleton-Variante einer Klasse entscheidet. Es gibt jedoch sinnvolle Fälle für Singletons. Oft wird eine Klasse als Singleton realisiert, wenn es darum geht, bestimmte vorhandene (Hardware-)Ressourcen zu modellieren. Man könnte z. B. den direkten Zugriff auf die Grafikkarte als Singleton modellieren. Für ein Computerspiel wäre dies durchaus sinnvoll, da man den Zugriff auf die Grafikkarte an sehr vielen Stellen benötigt und es ja auch genau eine Grafikkarte gibt.
Abschließend sei noch angemerkt, dass hier nur eine mögliche (die einfachste) von mehreren möglichen Singleton-Implementierungen gezeigt wurde. Viele Implementierungen benutzen auch Pointer als Member-Variablen, um das Singleton-Verhalten zu erreichen. Damit sind auch weitaus flexiblere Implementierungen möglich, sofern sie denn gebraucht werden.
In Alexandrescus Buch [3] wird auf die oben genannten Unzulänglichkeiten eingegangen und mögliche Lösungen aufgezeigt.4.3 Das Observer Pattern
Das Observer Pattern ist vom Prinzip her relativ leicht zu verstehen, jedoch gibt es auch hier verschiedene Implementierungen, die unterschiedliche spezielle Probleme adressieren. In diesem Artikel wird nur eine einfache Implementierung gezeigt, ohne auf Besonderheiten einzugehen.
Worum geht es beim Observer Pattern? Jedes Objekt hat einen Zustand, in dem es sich aktuell befindet. Bei Änderungen an diesem Zustand kann es vorkommen, dass es andere Objekte gibt, die von diesem einen Objekt abhängig sind und von solchen Zustandsänderungen benachrichtigt werden müssen. Man bezeichnet diese abhängigen Objekte als Observer und das zu beobachtende Objekt als Subject.Ein prominentes Beispiel hierfür ist das MVC-Prinzip (Model-View-Controller). Dabei will man die GUI (den View) von den Daten (dem Model) trennen, wodurch eine hohe Flexibilität entsteht. Dadurch kann man z. B. zu ein und denselben Daten (= Model = Subject) verschiedene Ansichten(= View = Observer) haben. Sobald sich etwas am Model ändert, benachrichtigt dieses die Observer (also die Ansichten), woraufhin diese ihre GUI-Komponenten aktualisieren.
Der Controller hält dabei sowohl das Model als auch die Views und meistens auch zusätzliche GUI-Komponenten, um Eingaben entgegenzunehmen, aber das spielt jetzt für uns und das Observer Pattern keine Rolle.
Ein anderes Beispiel ist das aus Java wohlbekannte Event/Listener-Modell.Das gewünschte Verhalten des Observer Pattern kann man folgendermaßen erreichen:
- Man kann Observer bei einem Subject "anmelden"
- Jeder Observer hat eine update-Methode, in der der eigene Zustand aktualisiert wird. Das bedeutet auch, dass man den Zustand des zu beobachtenden Subjekts braucht, um den eigenen Zustand mit diesem zu synchronisieren
- Ändert sich der Zustand eines Subjekts werden die Observer benachrichtigt (englisch: to notify), indem deren update-Methode aufgerufen wird
Klingt kompliziert? Ist es aber eigentlich nicht. Am besten sieht man dies anhand eines Code-Beispiels.
// Subject.h // #include <list> #include "ObserverInterface.h" using namespace std; class Subject { public: void attach(ObserverInterface* observer); void detach(ObserverInterface* observer); void notify(); private: list<ObserverInterface*> observers; protected: // Durch protected-Konstruktor wird diese Klasse abstrakt Subject() {}; };Mit der abstrakten Basisklasse Subject vereinbaren wir eine gemeinsame Schnittstelle für unsere späteren konkreten Subjekte.
Mit attach kann man einen Observer hinzufügen, mit detach kann man einen Observer wieder entfernen. Essenziell ist hier die notify-Methode. Diese ist dafür zuständig, unsere Observer zu benachrichtigen. Um unsere registrierten Observer zu verwalten, packen wir sie in eine STL-Liste. Wichtig ist hierbei zu beachten, dass wir nur Zeiger auf ObserverInterfaces abspeichern. Dies erlaubt uns später die Methoden von konkreten Observern polymorph aufzurufen.Wie sieht jetzt ein ObserverInterface aus? Nun, ganz einfach: Alles, was wir benötigen, ist eine update-Methode:
// ObserverInterface.h // class ObserverInterface { public: virtual void update() = 0; };Als Nächstes betrachten wir die Implementierung von Subject:
// SubjectImpl.cpp // #include "Subject.h" #include "ObserverInterface.h" void Subject::attach(ObserverInterface* observer) { observers.push_back(observer); } void Subject::detach(ObserverInterface *observer) { observers.remove(observer); } void Subject::notify() { list<ObserverInterface*>::iterator iter = observers.begin(); for ( ; iter != observers.end(); iter++ ) { (*iter)->update(); } }Wichtig ist hier, wie schon gesagt, die notify-Methode. Hier wird die ganze Liste an Observern durchgegangen und von jedem einzelnen die update-Methode aufgerufen.
Was wir jetzt brauchen, ist ein konkretes Subject, welches tatsächliche Daten repräsentiert:
// ConcreteSubject.h // #include <string> #include "Subject.h" using namespace std; class ConcrecteSubject : public Subject { private: string data; public: void setData(string _data) { data = _data; } string getData() { return data; } ConcreteSubject() : Subject() {} };Gut, extrem simpel, aber für unsere Zwecke ausreichend.
Man hätte in diesem Beispiel jetzt natürlich auch auf die Vererbungslinie von Subject und ConcreteSubject verzichten und stattdessen die Methoden aus Subject in ConcreteSubject reinpacken können. Aber durch diese Vererbung hat man eine schöne Trennung für den Code, der das Observer Pattern betrifft, und für den Code, der die eigentlichen (Anwendungs-)Daten dieser Klasse betrifft.Nun definieren wir einen konkreten Observer:
// ConcreteObserver.h // #include <string> #include "ObserverInterface.h" #include "ConcreteSubject.h" using namespace std; class ConcreteObserver : public ObserverInterface { private: string name; string observerState; ConcreteSubject* subject; // Dieses Objekt hält die Daten (=notifier) public: void update(); void setSubject(ConcreteSubject* subj); ConcreteSubject* getSubject(); ConcreteObserver(ConcreteSubject* subj, string name); };Um einen Observer zu identifizieren, verpassen wir ihm einen Namen. Die observerState-Variable ist dafür da, um den Zustand des Observers mit dem Zustand des Subjekts konsistent zu halten. Wichtig ist hierbei, dass dem Observer-Konstruktor auch gleichzeitig das zu beobachtende Subjekt mit übergeben werden muss. Nun zur Implementierung:
// ConcreteObserverImpl.cpp // #include <iostream> #include "ConcreteObserver.h" using namespace std; // Daten anzeigen void ConcreteObserver::update() { observerState = subject->getData(); cout << "Observer " << name << " hat neuen Zustand: " << observerState << endl; } void ConcreteObserver::setSubject(ConcreteSubject* obj) { subject = obj; } ConcreteSubject* ConcreteObserver::getSubject() { return subject; } ConcreteObserver::ConcreteObserver(ConcreteSubject* subj, string n) { name = n; subject = subj; }In der update-Methode holen wir den aktuellen Status des Subjekts und geben ihn aus.
Zusammenfassend lässt sich hier sagen: Wir haben eine Schnittstelle für Subjekte, welche es uns erlaubt, Observer hinzuzufügen und zu entfernen. Parallel haben wir eine Schnittstelle für Observer, welche es uns erlaubt, für jeden konkreten Observer die update-Methode aufzurufen. Zudem haben wir konkrete Observer und Subjekte definiert.Hier ein Beispiel für die Benutzung der erstellten Klassen:
// Main.cpp // #include "ObserverInterface.h" #include "ConcreteSubject.h" #include "ConcreteObserver.h" int main() { // Das Objekt hält alle Daten (=notfier = subject) ConcreteSubject* subj = new ConcretSubject(); ObserverInterface* obs1 = new ConcreteObserver(subj,"A"); ObserverInterface* obs2 = new ConcreteObserver(subj,"B"); // Observer(=views) an Subjekt anhängen (attachen) subj->attach(obs1); subj->attach(obs2); // Daten ändern und Observer informieren (notify) subj->setData("TestData"); subj->notify(); /* Ausgabe: Observer A hat neuen Zustand: TestData Observer B hat neuen Zustand: TestData */ return 0; }Es ist nun ein Leichtes, ohne Änderung des bestehenden Codes weitere Observer hinzuzufügen, welche die Daten z. B. auch in veränderter Form ausgeben.
Dies ist wie gesagt ein einfaches Beispiel, was aber die Funktionsweise von Observern gut veranschaulichen sollte. Es gibt unterschiedliche Implementierungen von Observen; so wird z. B. auch oft das Subjekt selbst als Parameter der notify-Methode übergeben, so dass ein Observer weiß, welches konkrete Subjekt ihn jetzt benachrichtigt hat (es kommt durchaus vor, dass ein Observer mehrere Subjekte beobachtet).Auf eine Begebenheit soll hier am Ende noch eingegangen werden:
Was macht man eigentlich, wenn z. B. eine Klasse, die als Observer fungieren soll, schon in einer Vererbungslinie steht? Also was wäre, am obigen Beispiel erklärt, wenn ConcreteObserver schon von einer ganz anderen Klasse (z. B. einer GUI-Komponentenklasse) erben würde und man aber trotzdem auch von ObserverInterface erben muss? Dafür gibt es mehrere Lösungswege; ein sehr eleganter ist das bereits beschriebene Adapter Pattern. Das könnte dann z. B. so aussehen: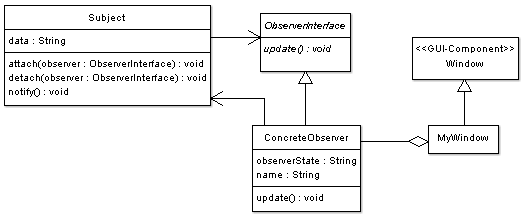
Wichtig sind hier eigentlich nur die beiden Klassen rechts (Window und MyWindow), das andere entspricht im Prinzip dem Code von vorhin.
Die Klasse "Window" soll hier aus einer GUI-Bibliothek entstammen und dient zur Darstellung von Fenstern. Will man etwas in ein solches Fenster zeichnen, dann muss man eine eigene Klasse erstellen, welche von "Window" erbt, und muss gewisse Methoden überschreiben, so dass man auch wirklich zeichnen kann (z. B. so etwas wie "paintEvent()", was es ja in einigen GUI-Bibliotheken gibt). Zu diesem Zweck gibt es hier die Klasse "MyWindow".
Genau hier liegt jetzt aber das Problem: Die Klasse "MyWindow" sollte hier ja eigentlich der Observer sein, welcher die vom Subject übermittelten Daten darstellen soll. D. h., MyWindow müsste sowohl von "ObserverInterface" als auch von "Window" erben.
Hier wurde aber stattdessen die Klasse ConcreteObserver beibehalten und die Klasse "MyWindow" adaptiert. Wird jetzt dieser Observer vom Subject benachrichtigt, so wird dieser Aufruf weiter an "MyWindow" delegiert, wo man dann z. B. zeichnen kann.4.4 Das Strategy Pattern
Zu diesem Pattern sei folgendes (eher realitätsfernes, dafür aber verständliches) Beispiel gegeben:
Wir haben eine Klasse, welche einen großen Datenbestand enthält:
class UserClass { private: int* data; public: const int* getData() { return data; } void insertValueAt(int pos, int value) { if (pos < 10000 && pos >= 0) data[pos] = value; } UserClass() { data = new int[10000]; } ~UserClass() { delete[] data; } };Ja, diese Klasse ist nicht gerade sehr schön, aber darauf kommt es auch nicht an. Jedenfalls wäre es jetzt toll, wenn man diese große Menge an Daten auch sortieren könnte, so dass man beim Aufruf von getData() das sortierte Array zurückgeliefert bekommt. Wie wir ja alle wissen, gibt es verschiedene Sortieralgorithmen, z.B. QuickSort, ShellSort, SelectionSort, usw. Das heißt, wir könnten in unsere Klasse jetzt eine Methode sort() aufnehmen, welche unsere Daten dann mit einem dieser Algorithmen sortiert. Wir wollen uns jedoch nicht auf einen bestimmten Algorithmus festlegen, sondern wollen diesen vom Benutzer der Klasse vorgeben lassen, was dann z. B. so aussehen könnte:
#define QUICKSORT 0 #define SHELLSORT 1 #define SELECTIONSORT 2 class MyClass { private: int* data; public: const int* getData() { return data; } void insertValueAt(int pos, int value) { if (pos < 10000 && pos >= 0) data[pos] = value; } MyClass() { data = new int[10000]; } ~MyClass() { delete[] data; } void sort(int algorithmToUse) { switch (algorithmToUse) { case QUICKSORT: sortWithQuickSort(); break; case SHELLSORT: sortWithShellSort(); break; case SELECTIONSORT: sortWithSelectionSort(); break; default: break; } } void sortWithQuickSort() { //Implementierung von QuickSort } void sortWithShellSort() { //Implementierung von ShellSort } void sortWithSelectionSort() { //Implementierung von SelectionSort } };Das ist natürlich eine äußerst unelegante Lösung. Jedes Mal, wenn ein neuer Algorithmus hinzukommt, müssen wir die Klasse bearbeiten und die switch-Struktur anpassen. Zudem ist hier die Laufzeitfehlerquote erhöht, da der Benutzer der Klasse ja auch falsche Werte übergeben kann.
Die Klasse selbst kann immer nur einen dieser Algorithmen zum Sortieren benutzen, d. h., sie braucht nicht all diese Algorithmen zu kennen. Wichtig ist nur, dass sie ihren Datenbestand sortieren kann. WIE (d. h. mit welchem Algorithmus) sie das tut, ist für die Klasse selbst eigentlich ziemlich egal.
Eine bessere Lösung ist es also, die jeweiligen Algorithmen in eigenen Klassen zu kapseln, was auch einem der Grundprinzipien von vielen Design Patterns entspricht: Beim Design einer Klasse schaut man, was sich immer mal wieder ändern kann (hier also z. B. die verschiedenen Sortieralgorithmen), und kapselt diese in neuen Klassen. Dadurch wird diese Klasse flexibler und man kann besser auf neue, sich ändernde Anforderungen reagieren.
Bei diesem Beispiel mit dem Strategy-Pattern sähe das dann so aus: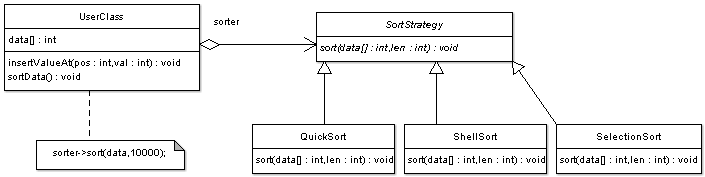
Natürlich ist es hier ein bisschen "Overkill", das Strategy Pattern anzuwenden, und es gäbe auch andere Möglichkeiten, dies elegant zu lösen, aber wie gesagt, daran sieht man gut, worauf es beim Strategy Pattern ankommt. Zur besseren Verständlichkeit hier noch der C++-Code:
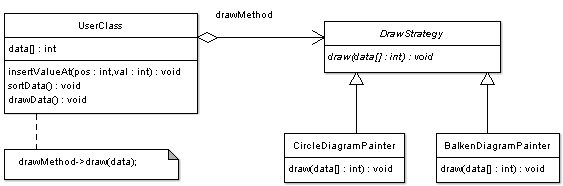
class UserClass { private: int* data; SortStrategy* sorter; // Die zu verwendende "Strategie" public: const int* getData() { return data; } void insertValueAt(int pos, int value) { if (pos < 10000 && pos >= 0) data[pos] = value; } // Hier müssen wir jetzt der Klasse auch eine Sortierstrategie übergeben UserClass(SortStrategy* s) { data = new int[10000]; sorter = s; } ~UserClass() { delete[] data; } void sort() { sorter->sort(data,10000); } // Hier kann man jetzt eine neue "Strategie" angeben, mit der sortiert werden soll void changeStrategy(SortStrategy* s) { sorter = s; } };// Die abstrakte Basis-Klasse für alle Sortier-Implementierungen class SortStrategy { public: virtual void sort(int* data, int len) = 0; protected: SortStrategy() {} };#include "SortStrategy.h" class QuickSort : public SortStrategy { public: QuickSort() {} void sort(int* data, int len) { // Hier steht dann die Implementierung des Quicksort-Algorithmus } };#include "SortStrategy.h" class ShellSort : public SortStrategy { public: ShellSort() {} void sort(int* data, int len) { // Hier steht dann die Implementierung des Shellsort-Algorithmus } };#include "UserClass.h" #include "SortStrategy.h" #include "QuickSort.h" #include "ShellSort.h" int main() { SortStrategy* s = new ShellSort(); UserClass* c = new UserClass(s); c->sort(); // mit Shellsort sortieren //Algorithmus wechseln c->changeStrategy(new QuickSort()); c->sort(); // jetzt wird mit Quicksort sortiert // in C++ müssen wir selbst allozierte Speicherbereiche auch wieder freigeben: delete s; delete c; // ACHTUNG: Beim Aufruf von "c->changeStrategy(new QuickSort());" haben wir uns jedoch nicht die Speicheradresse des neuen QuickSort-Objekt gemerkt und // können es somit auch nicht selbst wieder freigeben. D. h., hier würde ein Memory Leak entstehen, wenn das Programm noch länger laufen würde. return 0; }Ein häufig auftretender Fehler ist, dass in Fällen wie diesen Vererbung eingesetzt wird, um die verschiedenen Verhaltensweisen einer Klasse zu modellieren. Das ist jedoch falsch. Eine Vererbung ist immer eine Ist-ein-Beziehung, nicht mehr und nicht weniger. Durch das Kennen des Strategy-Patterns lassen sich solche Fehler eventuell vermeiden. Nehmen wir z. B. noch mal obiges Beispiel: Nehmen wir an, dass wir dieser Klasse noch eine Zeichenfunktion hinzufügen wollen, welche wahlweise die Häufigkeit des Auftretens der verschiedenen Zahlen im Datenbestand entweder als Balken- oder Kreisdiagramm zeichnet. Es gibt mitunter Leute, die hier auf die Idee kommen könnten, dies als Vererbung zu realisieren, was z. B. so aussehen könnte:
(Vererbung)
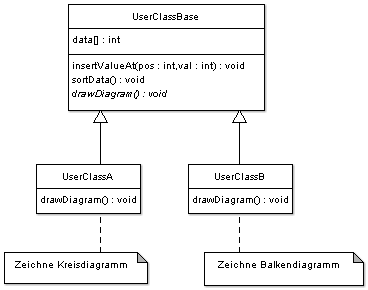
Viel besser wäre hier aber wieder die Anwendung des Strategy-Patterns. Auf welche Art und Weise (also wie) die Klasse so ein Diagramm zeichnet, ist egal, Hauptsache sie zeichnet es. So lassen sich auch bequem neue Zeichenimplementierungen hinzufügen bzw. bestehende verändern und das ohne unsere Ausgangsklasse zu modifizieren, was insbesondere in größeren Projekten wichtig ist. Ein weiterer Vorteil ist, dass die mithilfe des Strategy-Patterns gekapselten Algorithmen auch von anderen Klassen problemlos benutzt werden können.
(Strategy-Pattern)
5 Zusammenfassung
Gerade beim letzten Pattern, dem Strategy Pattern, kann man sehen, worauf es bei vielen Patterns ankommt. Man hat ein größeres Problem, das man mit einer oder mehreren Klassen zu lösen versucht. Dieses große Problem lässt sich in mehrere kleinere Teilprobleme unterteilen, von denen nicht alle anwendungsspezifisch, sondern allgemeiner sind, wie z.B . das Benachrichtigen von Objekten bei Zustandsänderungen (vgl. Observer Pattern). Diese kleineren Teilprobleme versucht man dann in eigene Klassen zu kapseln, was oft durch gemeinsame Schnittstellen und Polymorphie erreicht wird. Dadurch werden die Klassen, die man schreibt, um einiges flexibler und man wird besser auf sich ändernde Anforderungen reagieren können, was gerade heute ungemein wichtig ist.
Es ist allerdings nicht wichtig, jedes einzelne Design Pattern zu kennen. Viel wichtiger ist es, das prinzipielle Vorgehen bei Design Patterns zu verstehen und dieses auch im Alltag anwenden zu können. Man sollte also beim Entwickeln von Klassen ein großes Problem in kleinere "zerlegen" können, um dann zu schauen, ob es für so ein Teilproblem nicht vielleicht schon ein bewährtes Entwurfsmuster gibt.
Bei relationalen Datenbanken hat einer meiner Professoren einmal gesagt, dass die Antwort auf viele Probleme einfach im Erzeugen neuer Tabellen liegt. Genauso kann man beim objektorientierten Programmieren meiner Meinung nach behaupten, dass die Antwort auf viele Probleme im Erstellen neuer Klassen liegt, in welche man Teilprobleme auslagert. Klingt vielleicht ein bisschen dumm, aber da steckt schon ein bisschen Wahrheit drin.
6 Literatur
[1] Design Patterns - Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides
DAS Buch zu Design Patterns schlechthin. Jedes einzelne Design Pattern wird anhand von UML-Diagrammen, Code-Beispielen (C++; Smalltalk) und Problemstellungen durchgegangen. Für absolute Anfänger vielleicht eher weniger tauglich, ansonsten aber sehr gut. Gibts auch auf Deutsch.[2] Design Patterns Explained - A New Perspective on Object Oriented Design - Allan Shalloway, James R. Trott
Meiner Meinung nach ein sehr schönes Buch, welches nicht nur einfach eine Auflistung aller Design Patterns von A-Z bringt, sondern vielmehr versucht, dem Leser anhand einiger ausgewählter Design Patterns einen guten OO-Stil beizubringen. Zudem ist das Buch sehr kurzweilig geschrieben. Alle Code-Beispiele gibts in Java und C++.[3] Modern C++ Design: Generic Programming and Design Patterns applied - Andrei Alexandrescu
Dreht sich nicht ausschließlich um Design Patterns, sondern insbesondere auch um generische Programmierung mit Templates. Sollte hier aber dennoch nicht fehlen, da es bei den behandelten Design Patterns nicht nur einfach eine einfache Implementierung zeigt, sondern v. a. auch auf verschiedene Problemstellungen eingeht und dafür C++-bezogene Lösungswege zeigt. Ziemlich anspruchsvoll; ohne vorherige Erfahrung mit Templates und Design Patterns sehr schwer zu verstehen.[4] Head first Design Patterns - Elisabeth Freeman, Eric Freeman, Bert Bates, Kathy Sierra
Das Buch soll wohl sehr gut und vor allem auch angenehm zum Lesen sein (ich kenne es nicht).
-
Klasse Artikel
 Hat mir sehr gut gefallen, habe schon immer auf sonen Artikel gewartet, obwohl nicht alles neu war
Hat mir sehr gut gefallen, habe schon immer auf sonen Artikel gewartet, obwohl nicht alles neu war 
Werden auch weiter Teile hinzukommen oder wars das erstmal mit den Patterns ?
-
Absolut gelungener Artikel, sehr sehr gut
gruss
v R
-
Top, super Artikel
Sowas hatte ich auch noch vermisst.Kann man sich auf die Fortsetzung freuen?
Wunschliste:Factory Method
Abstract Factory
Visitor
-
#include <iostream> #include "singleton.h" // Die Singleton-Klasse von oben using namespace std; int main() { // Hier wird tatsächlich das Singleton-Objekt in der Instance-Methode instanziiert und zurückgegeben Singleton s1 = Singleton::Instance(); // Hier wird nun einfach das bereits weiter oben instanziierte Objekt zurückgegeben Singleton s2 = getSingletonInstance(); // ! s1.doSomething(); // Adressen des Objektes ausgeben: Diese sind immer gleich, d. h., es handelt sich immer um dasselbe Objekt cout << hex << &getSingletonInstance() << endl; // ! cout << hex << &getSingletonInstance() << endl; // ! return 0; }// ! fehlt da nicht ein Singleton::?
-
Das freut mich, dass der Artikel gut ankommt
")
Also prinzipiell spricht nichts gegen ein Fortsetzung, wobei ich demnächst aber einen anderen Artikel anfange. Aber danach, warum nichthemem schrieb:
#include <iostream> #include "singleton.h" // Die Singleton-Klasse von oben using namespace std; int main() { // Hier wird tatsächlich das Singleton-Objekt in der Instance-Methode instanziiert und zurückgegeben Singleton s1 = Singleton::Instance(); // Hier wird nun einfach das bereits weiter oben instanziierte Objekt zurückgegeben Singleton s2 = getSingletonInstance(); // ! s1.doSomething(); // Adressen des Objektes ausgeben: Diese sind immer gleich, d. h., es handelt sich immer um dasselbe Objekt cout << hex << &getSingletonInstance() << endl; // ! cout << hex << &getSingletonInstance() << endl; // ! return 0; }// ! fehlt da nicht ein Singleton::?
Wenn du dir den Quellcode anschaust, dann siehst du, dass getSingletonInstance eine normale Funktion außerhalb der Singleton-Klasse ist (welche eben dazu dient, dass man nicht ständig über Singleton::Instance drauf zugreifen muss). D.h. da fehlt nichts
-
hi zu Observer Pattern hab ich gerade was gefunden:
http://www.ddj.com/dept/cpp/184403873
viel spaß;)
-
aber müsste ein singleton nicht auch den zuweisungsoperator protected oder private machen? Denn sonst kann man ja doch meherere Instnazen erstelln, wie man sieht:
Singleton s1 = getSIngletonInstance();
Singleton s2 = getSinbgleTonInstnace();s1 und s2 sind verschiedene Insstanzen, weil die rüberkopiert worden sind. Da muss doch eigentlich ne Referenz hin, oder?
also Singleton& s1=getSingletonInsance();oder?
-
Maxi schrieb:
s1 und s2 sind verschiedene Insstanzen, weil die rüberkopiert worden sind. Da muss doch eigentlich ne Referenz hin, oder?
also Singleton& s1=getSingletonInsance();Ganz genau, weil der Copy Constructor nicht beachtet wurde: http://msdn.microsoft.com/msdnmag/issues/03/02/CQA/
-
Mit welchem Programm hast du diese schönen Diagramme gemacht?
-
dia schrieb:
Mit welchem Programm hast du diese schönen Diagramme gemacht?
Die sehen aus als wären die mit dem Program gemacht worden das du als Nick trägst
")
BR
Vinzenz
-
Oh ja das stimmt, den Copy-Konstruktor hab ich vergessen

Den sollte man besser protected machen, hier in dem Beispiel spielts aber keine Rolle (zudem ist das C++-spezifisch, in andern Sprachen braucht man das nicht)@dia
Die Diagramme hab ich mit ArgoUML erzeugt. Gibt aber schöneres
-
nep schrieb:
Oh ja das stimmt, den Copy-Konstruktor hab ich vergessen
Den sollte man besser protected machen, hier in dem Beispiel spielts aber keine Rolle (zudem ist das C++-spezifisch, in andern Sprachen braucht man das nicht)@dia
Die Diagramme hab ich mit ArgoUML erzeugt. Gibt aber schöneresAch echt?
 Die von DIA sehen auch so aus :p
Die von DIA sehen auch so aus :p
BR
Vinzenz
-
Sehr schöner Artikel, könntest du eventuell auch noch ein paar exoten erläutern?
-
Warum machst du die doSomeThing Funktion static? Wenn das Singleton static ist, dann muss doch die Funktion nicht mehr static sein.
-
Gute Frage
Ist natürlich unnötig, auch wenn sich nichts dran ändert
-
Ich hab paar Fragen zu dem Observer-Pattern.
Es ist ja für mich eigentlich schon verwirrend genug, dass nicht das Subject der eigentliche Observer ist, weil er reagiert ja eigentlich auf die Zustandsänderung, indem er die Observer benachrichtigt. Die Observer beobachten für mich also eigentlich gar nichts, sondern warten eher, bis sie mal von der Seite angestubst werden.
Aber ok, was ich eigentlich wissen wollte, warum bekommen die Observer einen Zeiger des Subjects, das sie benachrichtigt? Warum müssen die den haben?
-
Naja da hast du programmiertechnisch gesehen auch nicht unrecht. Das Subjekt muss die Observer natürlich benachrichtigen (also wie du es nennst "von der Seite anstubsen"). Aber genau das ist es ja was die Observer "beobachten", sie sind abhängig vom Subject und beobachten Zustandsänderungen. Wenn sich aber etwas am Zustand geändert hat, dann muss das Subjekt dieses den Observern auch irgendwie mitteilen; die können das ja nicht riechen
Und genau deswegen bekommen auch die Observer einen Zeiger des Subjects. Sobald sie benachrichtigt wurden, wissen sie ja, dass sich etwas am Zustand des Subjektes geändert hat. Und nun will ein Observer normalerweise natürlich auch wissen was sich am Zustand geändert hat (also z.B. neue Daten usw...), und diese Änderungen muss man beim Subject abfragen, und das geht eben über diesen Zeiger
-
Zu Observer:
http://www.henkessoft.de/C++/C++ Fortgeschrittene/C++_Fortgeschrittene.htm#3.1._Observer
-
Gibt es das Programm (bei den Strategy Mustern) auch komplett (also lauffähig) zum ausprobieren irgendwo, ohne das ich noch die Sortieralgorythmen einfügen muss und so, weil ich damit irgendwie probleme habe...