Modernes Exception-Handling Teil 2 - Hinter den Kulissen
-
Modernes Exception-Handling Teil 2 - Hinter den Kulissen
Betrachten wir einmal, was hinter den Kulissen vor sich geht. Wie implementieren Compiler diesen Exception-Mechanismus? Als Beispiel nehmen wir den VC++ 2005 heran. Mit VC++ 2008 hat sich in Bezug auf Exceptionhandling nichts Grundlegendes verändert, es wurden nur ein paar kleine Optimierungen eingebaut - die Struktur blieb aber gleich.
Sehen wir uns folgenden einfachen Code an:
class Class {}; void do_nothing() { } void might_throw() { if(rand() % 2) { throw SomeException(); } } void two_objects() { Class objA; might_throw(); Class objB; might_throw(); Class objC; } void pass_through() { two_objects(); } void foo() { try { pass_through(); } catch(SomeException& e) { do_nothing(); throw; } } int main() { foo(); }Der Compiler muss im Falle einer Exception genau wissen, was er zu tun hat - er muss deshalb irgendwo Informationen haben, wo das Programm steht und was es zu tun gibt. Unter Windows 32 Bit ist das ganze per einfach verketteter Liste gelöst, in der alle Funktionen stehen, die im Falle einer Exception etwas tun müssen. Sehen wir uns diese Liste einmal an:
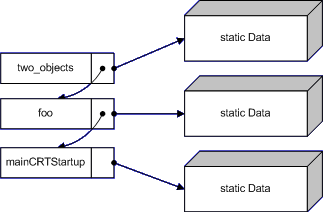
might_throwwirft eine Exception, aber es gibt nichts zu tun. Keine Objekte, die zerstört werden müssen und keine catch-Blöcke.two_objectsbraucht dagegen einen Eintrag in der Unwind-Liste. Denntwo_objectserstellt Objekte, die zerstört werden müssen, wenn eine Exception fliegt.pass_throughhat keinen Eintrag in der Liste, denn egal was passiert,pass_throughleitet die Exception nur weiter, ohne selbst zu reagieren.foodagegen hat einen catch-Block und muss somit Code ausführen, wenn eine Exception fliegt. Der catch-Block enthält Code, um zu überprüfen, ob die Exception hier gefangen wird oder durchgelassen wird. Selbst wennfoodie Exception nicht fangen würde, müsste dieser Code dennoch ausgeführt werden.mainist wiepass_throughrecht langweilig.mainCRTStartupist eine magische Funktion der C/C++-Runtime. Hier werden globale Variablen wieerrnoinitialisiert, der Heap angelegt,argc/argvgefüllt, etc. und ebenfalls ein try-catch-Block ummaingelegt.Jedes Mal, wenn eine Funktion betreten wird, wird ein Eintrag in der Unwind-Liste gemacht. Da aber einige Funktionen keinen Code haben, der abhängig von Exceptions ist, werden diese Funktionen nicht in der Liste eingetragen. Dieser Eintrag kostet natürlich Zeit und Speicher, deshalb optimiert der Compiler wo er nur kann. "Static Data" enthält Daten zu den jeweiligen Funktionen, die den aktuellen Status angeben.
Die interessante Funktion ist
two_objects. Sehen wir unstwo_objectseinmal so an, wie ein sehr naiver Compiler sie implementieren könnte:void two_objects() { //Metadaten //Eintrag in Unwind Liste Function this = new Function(); unwindList.add(&this); this.status=0; //Objekte anlegen: Class* objA; Class* objB; Class* objC; //Class objA; - objekt initialisieren objA=new Class(); this.status=1; might_throw(); if(exception) goto cleanup; //Class objB; - objekt initialisieren objB=new Class(); this.status=2; might_throw(); if(exception) goto cleanup; //Class objC; - objekt initialisieren objC=new Class(); this.status=3; //aufräumen cleanup: if(this.status==3) { delete objC; this.status=2; } if(this.status==2) { delete objB; this.status=1; } if(this.status==1) { delete objA; this.status=0; } if(this.status==0) { unwindList.remove(&this); delete this; } }Der Cleanup-Code wird aus dem "Static Data"-Block abgeleitet, auf den das aktuelle Unwind-Element zeigt. Diese Statusvariable immer auf dem Laufenden zu halten, kostet ebenfalls Zeit und wird deshalb nur dann gemacht, wenn es wirklich notwendig ist.
this.status=3;wäre in dem obigen Code wegoptimierbar.Unter Windows 64 Bit sieht das ganze schon etwas besser aus. Statt einer Unwind-Liste haben wir eine Unwind-Map und als Schlüssel verwenden wir den Wert des Instruction Pointers, IP, zu dem Zeitpunkt, als die Exception geworfen wurde.
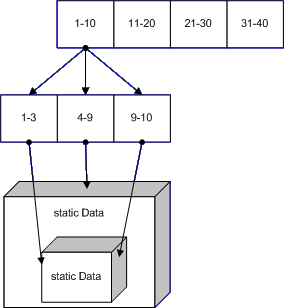
Der Vorteil hier liegt auf der Hand: wir haben keine teure Liste, die wir pro Funktionsaufruf ändern müssen, wir haben nur eine komplexe Map, die wir einmal erstellt haben. Über den IP kann man den aktuellen Status der Funktion (und vor allem auch die Funktion selbst, in der man sich gerade befindet) herausfinden. Der Nachteil liegt im höheren Aufwand, falls eine Exception geworfen wird. Da Exceptions aber nur fliegen, wenn sowieso etwas nicht mit rechten Dingen zugeht, ist es durchaus vertretbar - vor allem, wenn man dafür den Nicht-Exception-Pfad deutlich beschleunigen kann.
Das ganze soll nicht vor Exceptions abschrecken - sie sind zwar nicht gratis (aus Performance-Sicht), aber man darf nicht vergessen, dass ein
if()oder gar ganzeswitch()-Orgien bei der if-then-else-Fehlerbehandlung auch nicht gerade wenig Zeit kosten.Wenn nun eine Exception geworfen wird, kann die Funktion sich selbst dank der Statusinformationen unwinden - aber wie genau wird der passende catch-Handler gefunden? VC++ geht hier einen 2-Pass-Weg, es wird die Unwind-Liste also zweimal durchgegangen.
Beim 1. Pass wird ein passender Exceptionhandler gesucht. Wenn keiner gefunden wird, wird
terminate()aufgerufen, welchesabort()aufruft und das Programm beendet. Wenn aber einer gefunden wurde, dann wird der 2. Pass ausgeführt, in welchem das Unwinding beginnt.Exkurs: Exceptions in C
Im vorherigen Abschnitt haben wir einen Blick hinter die Kulissen des Exceptionhandlings geworfen. Doch C bzw. C++ wären nicht C bzw. C++ wenn man das ganze nicht auch händisch implementieren könnte. Einige Exceptionimplementierungen basieren auf genau dem Prinzip, das Sie gleich kennenlernen werden. Vor allem im Embedded Bereich, wo öfters C++-Exceptions nicht verwendet werden können, setzt man oft C-Exceptions ein.
Der Trick hinter Exceptions in C sind die beiden Funktionen
setjmp()undlongjmp(), deshalb wird diese Art der Implementierung auch gerne sjlj-Exceptions genannt.setjmpsichert den aktuellen Kontext in einen sogenannten jump-Buffer. Der Kontext enthält unter anderem die auto-Variablen am Stack und die Registerwerte.setjmpliefert immer 0 als Ergebnis. Nun verwendet manlongjmpum einen Kontext wiederherzustellen (einschließlich des Instruction Pointers), wir landen mit der Ausführung also wieder in der Zeile, in der wirsetjmp()aufgerufen haben.longjmpgeben wir aber einen bestimmten Integer-Wert mit und diesen liefertsetjmpuns jetzt - so können wir zwischen den einzelnen Fällen unterscheiden.Da das sehr theoretisch klingt, ein kleines Beispiel:
#include <stdio.h> #include <setjmp.h> #include <assert.h> jmp_buf jbuf; #define E_DIVBYZERO -1 #define E_NOCLEANDIV -2 int divide(int a, int b) { if(b==0) { longjmp(jbuf, E_DIVBYZERO); } if(a%b != 0) { longjmp(jbuf, E_NOCLEANDIV); } return a/b; } int main() { switch(setjmp(jbuf)) { case 0: { int a,b,c; puts("please input an integer"); scanf("%d", &a); puts("please input another integer"); scanf("%d", &b); c=divide(a, b); printf("%d divided by %d gives %d\n", a, b, c); return 0; } case E_DIVBYZERO: { fputs("The integers couldn't be divided, due to a division by zero error.\n", stderr); return -1; } case E_NOCLEANDIV: { fputs("The integers couldn't be divided without a remainder.\n", stderr); return -1; } default: assert(0); } assert(0); }divide()dividiert 2 Integer-Werte und liefert einen Fehler, wenn der Divisor 0 ist oder die Division einen Rest ergibt. Sobald wir eine Fehlersituation individehaben, springen wir mitlongjmpin das switch in main. Dort wird das Ergebnis ausgewertet und der passende Case-Zweig angesprungen.Ein Wort der Warnung ist hier aber angebracht: lesen Sie genau in ihrer Compilerdokumentation nach, wie sich sjlj in einem C++-Programm verhält. Denn in einem C++-Programm muss der Destruktor von Objekten am Stack ausgeführt werden (etwas das wir uns in C ja sparen können).
Einen etwas tieferen Einblick in sjlj-Exceptions bieten Ihnen Tom Schotland und Peter Petersen.
Exception-Safety testen
Wie können wir garantieren, dass unsere Klassen exceptionsicher sind? Wir können natürlich den Code stundenlang analysieren und irgendwann sagen: so, jetzt haben wir alle Situationen bedacht. Das ist aber unpraktisch und in der Software-Entwicklung lechzen wir nach Automatisierungen.
Unittest: eine komplette Automatisierung ist mir leider nicht bekannt, aber es gibt Techniken, die man in seine Unittests einbauen kann. Die Idee ist eine Funktion
mightThrow()in jede Funktion zu packen, die eine Exception werfen darf. Einfach ist das ganze, wenn wir z.B. einen Container oder ähnliches testen wollen:class ThrowTestClass { private: int value; public: TestClass(int value=0) : value(value) { mightThrow(); } TestClass(TestClass const& other) : value(other.value) { mightThrow(); } int operator=(TestClass const& other) { this->value = other.value; mightThrow(); } //... }; int main() { std::vector<ThrowTestClass> vec; test(vec); }Die ganze Magie befindet sich in der Funktion
mightThrow.void mightThrow() { if(!throwCounter--) { throw ExceptionSafetyTestException(); } }Wir nehmen eine globale Variable und reduzieren sie immer um 1, wenn
mighThrowaufgerufen wird. WennthrowCounter0 erreicht hat, dann wird eine Exception geworfen. Idealerweise iteriertmightThrowdann durch alle Exceptions, die die Funktion werfen darf, meistens ist das aber zu viel des Guten und es reicht eine Standard-Exception zu werfen. Sehen wir uns dazu jetzt die Testfunktion an:template<class Data, class Test> void basicGuaranteeCheck(Data& data, Test const& test) { bool finished=false; for(int nextThrowCounter=0; !finished; ++nextThrowCounter) { Data copy(data); throwCounter = nextThrowCounter; try { test.test(copy); finished=true; } catch(ExceptionSafetyTestException& e) { //nothing } invariants(copy); } } template<class Data, class Test> void strongGuaranteeCheck(Data& data, Test const& test) { bool finished=false; for(int nextThrowCounter=0; !finished; ++nextThrowCounter) { Data copy(data); throwCounter = nextThrowCounter; try { test.test(copy); finished=true; } catch(ExceptionSafetyTestException& e) { REQUIRE(copy == data); } invariants(copy); } }Mit Hilfe von Regular Expressions lässt sich die Dokumentation des Codes dazu nutzen, die notwendigen throws zu generieren. Dabei wird auf einer Kopie des originalen Source Codes gearbeitet und am Anfang jeder Funktion, die Exceptions werfen darf, ein
mightThrow()eingefügt.Leider kenne ich keine Unittest-Library, die das unterstützt - aber vielleicht regt dieser Artikel ja den einen oder anderen an, so etwas in bestehende Librarys reinzupatchen.
Der Code der Testfunktion sollte leicht verständlich sein, deshalb sehen wir ihn uns nur kurz näher an.
dataist ein Datenobjekt, z.B. ein Objekt einer Klasse, undtestist ein Objekt, das den Test ausführt. So könntedataz.B. einstd::vectorsein undtestkönnte den operator= testen. Der throwCounter ist eine globale Variable, die bestimmt, wann mightThrow eine Exception wirft und anhandfinishederkennen wir, wann keine Exception mehr geworfen wurde (und deshalb der Test beendet ist). Wir arbeiten dabei die ganze Zeit nur auf einer Kopie der echten Daten, da wir ja (zumindest bei der Strong-Garantie) testen wollen, ob der Zustand trotz Exception identisch geblieben ist. Mitinvariants()überprüfen wir zum Schluss, ob die Invarianten noch alle stimmen.Interoperability von Exceptions
In C++ leiden wir unter dem Fehlen eines ABI-Standards. Wir können leider nicht garantieren, dass eine Exception, die ein Binary (z.B. eine DLL oder SO) verlässt kompatibel mit den Exceptions in dem Binary ist, dass die Exception fängt. Natürlich ist es möglich, diese Kompatibilität zu erzwingen und in einigen Situationen macht das auch durchaus Sinn, aber wir sollten nicht davon ausgehen, dass dies immer zutrifft. Wir haben in C++ also das Problem, dass wir Exceptions nicht über Binary-Grenzen hinweg werfen dürfen. Wir müssen in solchen Situationen zu dem alten if-then-Error-Handling zurückkehren.
Java und .NET haben dieses Problem nicht, da sie jeweils ein standardisiertes ABI haben und daher das Werfen und Fangen von Exceptions über Binary-Grenzen hinweg kein Problem darstellt.
Exceptionsicheres Klassendesign
Nach welchen Richtlinien schreibt man denn nun exceptionsichere Klassen? Das Paradebeispiel dafür ist eine Stack-Klasse wie
std::stack- wobeistd::stackja eigentlich nur ein Container-Adapter ist. Eine naive Implementierung einer Stack-Klasse könnte so aussehen:template<typename T> class Stack { private: T* data; std::size_t used; std::size_t space; public: explicit Stack(std::size_t expectedElements = 100) : data(static_cast<T*>(operator new(expectedElements*sizeof T))) , used(0) , space(expectedElements) { } Stack(Stack const& other) : data(static_cast<T*>(operator new(other.used*sizeof T))) , used(other.used) , space(other.used) { std::uninitialized_copy(other.data, other.data+other.used, data); } ~Stack() { std::destroy(data, data+used); operator delete(data); } Stack& operator=(Stack& const other) { Stack temp(other); swap(temp); return *this; } void push(T const& obj) { if(space>used) { std::consruct(data+used, obj); ++used; return; } space*=2+1; T* temp=operator new(space*sizeof T); std::uninitialized_copy(data, data+used, temp); std::construct(temp+used, obj); std::swap(data, temp); std::destroy(temp, temp+used); operator delete(temp); ++used; } T pop() { if(empty()) throw StackEmptyException(); T temp(data[--used]); std::destroy(data+used); return temp; } bool empty() const { return used==0; } std::size_t size() const { return used; } void swap(Stack& other) { std::swap(data, other.data); std::swap(used, other.used); std::swap(space, other.space); } };Hier gibt es eine Menge Probleme. Gehen wir sie der Reihe nach an:
Stack(Stack const& other) : data(static_cast<T*>(operator new(other.used*sizeof T))) , used(other.used) , space(other.used) { std::uninitialized_copy(other.data, other.data+other.used, data); }Sollte eine Kopieroperation in
std::uninitialized_copyfehlschlagen, so wird der Speicher, auf den data zeigt, nicht aufgeräumt.void push(T const& obj) { if(space>used) { std::consruct(data+used, obj); ++used; return; } space*=2+1; T* temp=operator new(space*sizeof T); std::uninitialized_copy(data, data+used, temp); std::construct(temp+used, obj); std::swap(data, temp); std::destroy(temp, temp+used); operator delete(temp); ++used; }spacewird erhöht, bevor die Kopieroperationen beendet sind. Solltenewoderstd::copy()fehlschlagen, bleibtspaceauf dem erhöhten Wert, obwohl keine Erhöhung stattfand.T pop() { if(empty()) throw StackEmptyException(); T temp(data[--used]); std::destroy(data+used); return temp; }Sollte eine der beiden Kopieroperation fehlschlagen, geht das Objekt für immer verloren, da wir es bereits aus unserem Stack gelöscht haben - es aber nie beim Caller ankam.
Eine elegantere Variante diese Probleme zu umgehen, wäre folgende Implementierung:
template<typename T> class StackImpl { public: T* data; std::size_t used; std::size_t space; explicit StackImpl(std::size_t elements) : data(static_cast<T*>(operator new(elements*sizeof T))) , used(0) , space(elements) { } ~StackImpl() { std::destroy(data, data+used); operator delete(data); } void swap(StackImpl& other) { std::swap(data, other.data); std::swap(used, other.used); std::swap(space, other.space); } private: StackImpl(StackImpl const&); StackImpl& operator=(StackImpl& const); }; template<typename T> class Stack { private: StackImpl<T> impl; public: explicit Stack(std::size_t expectedElements = 100) : impl(expectedElements) { } Stack(Stack const& other) : impl(other.impl.used) { std::uninitialized_copy(other.impl.data, other.impl.data+other.impl.used, impl.data); impl.used=other.impl.used; } Stack& operator=(Stack& const other) { Stack temp(other); swap(temp); return *this; } void push(T const& obj) { if(impl.space == impl.used) { Stack temp(impl.space*2+1); std::unitialized_copy(impl.data, impl.data+impl.used, temp.impl.data); temp.impl.used=impl.used; swap(temp); } std::construct(impl.data+impl.used, obj); ++impl.used; } void pop() { if(empty()) throw StackEmptyException(); std::destroy(impl.data+impl.used-1); --impl.used; } T& top() { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } T const& top() const { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } bool empty() const { return impl.used==0; } std::size_t size() const { return impl.used; } void swap(Stack& other) { impl.swap(other.impl); } };Da wir eine Hilfsklasse verwenden, die das Speichermanagement übernimmt, entstehen im Konstruktor keine Speicherlecks mehr:
Stack(Stack const& other) : impl(other.impl.used) { std::uninitialized_copy(other.impl.data, other.impl.data+other.impl.used, impl.data); impl.used=other.impl.used; }Sollte
std::uninitialized_copyfehlschlagen, wird dennochimplzerstört und der Speicher korrekt freigegeben. Wichtig ist, dassusederst gesetzt wird, nachdem das Kopieren erfolgreich war.void push(T const& obj) { if(impl.space == impl.used) { Stack temp(impl.space*2+1); std::unitialized_copy(impl.data, impl.data+impl.used, temp.impl.data); temp.impl.used=impl.used; swap(temp); } std::construct(impl.data+impl.used, obj); ++impl.used; }Wir verwenden hier das bekannte Copy&Swap, um den Speicherbereich zu vergrößern. Wir reduzieren dadurch den nötigen Code und gewinnen Robustheit.
void pop() { if(empty()) throw StackEmptyException(); std::destroy(impl.data+impl.used-1); --impl.used; } T& top() { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } T const& top() const { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; }Ein
pop(), das den gepopten Wert by Value liefert, kann nie exceptionsicher sein. Wir brauchen daher einetop()-Methode, um an das oberste Element zu gelangen. Nebenbei gewinnen wir dadurch noch die Möglichkeit Stack als ein konstantes Objekt verwenden zu können, da wir nun mittop()an das oberste Element kommen, ohne den Stack ändern zu müssen.Design von Exceptionklassen
Je nachdem mit welcher Sprache man arbeitet, sehen Exceptions immer leicht anders aus. Exceptions können das Debuggen erleichtern, wenn sie wichtige Informationen wie Was ist passiert?, Wo ist es passiert? und u.U. auch ein Warum ist es passiert? mitteilen. Das essentiellste davon ist "Was ist passiert?". In der C++-Standard-Library über die virtuelle Funktion exception::what() gelöst. Java und C# bieten jeweils noch eine Antwort auf die Frage "wo ist es passiert?" anhand eines Stack Traces. C++ bietet so etwas nicht eingebaut, aber man kann dennoch an einen Stack Trace gelangen.
Die einfachste Möglichkeit einen Stack Trace zu bekommen ist, einen Debugger mitlaufen zu lassen - in der Debug-Version, während wir noch testen, werden wir das vermutlich sowieso immer machen. Aber wenn wir keinen Debugger mitlaufen lassen haben, können wir die System API verwenden (sofern wir mit Debug-Informationen kompiliert haben) oder aber eine fertige Lösung.
Das wichtigste Feature, das Exceptionklassen bieten müssen, ist eine durchdachte Hierachie. Denn wenn jeder Fehler, der erzeugt wird, lediglich vom Typ
StandardExceptionist, kann man nur sehr schwer darauf reagieren. Es ist wichtig, einen Mittelweg aus zu tiefer Hierachie und zu breiter Hierachie zu finden. Denn wenn wir eine Exception von einer anderen erben lassen, muss dies wirklich eine "A ist spezialfall von B"-Situation sein. Oft ist so eine Entscheidung nicht leicht zu treffen: wenn ich eine Datei nicht öffnen kann, weil mir die Rechte fehlen, ist das dann eineIOExceptionoder eineSecurityException?Der Konstruktor einer Exceptionklasse darf nie eine Exception erzeugen - denn wir wissen ja: sollte eine Exception auftreten, während eine Exception behandelt wird, wird das Programm beendet. Das bedeutet auch, dass man mit Speicherreservierungen vorsichtig sein muss.
Exceptionsicherheit ohne try/catch
Der große Vorteil von C++-Exceptions ist RAII. Anstatt überall try/catch schreiben zu müssen, können wir mit RAII die Fehlerfälle meistens sehr gut abfangen, ohne sie explizit zu behandeln.
Betrachten wir folgenden Code:
class Class { private: char* name; int* array; public: Class(char const* name) : name(new char[strlen(name)+1]), array(new int[100]) { strcpy(this->name, name); fill(array); } //... };Das Problem ist offensichtlich: wenn eine der beiden Allokationen fehlschlägt, wird die andere nicht mehr rückgängig gemacht. Wir könnten also mit try/catch versuchen, das Problem zu lösen:
class Class { private: char* name; int* array; public: Class(char const* name) : name(0), array(0) { try { this->name = new char[strlen(name)+1]; array = new int[100]; } catch(std::bad_alloc& e) { delete [] this->name; delete [] array; throw; } strcpy(this->name, name); fill(array); } //... };Das funktioniert zwar, aber es geht besser:
class Class { private: std::string name; std::vector<int> array; public: Class(char const* name) : name(name), array(100) { fill(array); } //... };Nicht nur, dass wir jetzt keine Memory-Leaks mehr haben, wir haben auch noch den Code reduziert und schlanker gemacht. Meistens ist es eine gute Idee, dynamische Allokationen in eine Ressourcen-Klasse zu stecken, da so nicht nur Fehler verhindert werden, sondern der Code auch deutlich einfacher gestaltet bleibt.
Besonders problematisch sind dynamische Allokationen in einem Funktionsaufruf:
foo(new Bar(), new Baz());Mit Smart Pointern wie z.B. scoped_ptr/auto_ptr oder shared_ptr kann man diese Probleme umgehen, indem die Smart Pointer die Ressource verwalten.
Die weite Welt
Exception Handling ist nur eine mögliche Lösung für das komplexe Problem der Fehlerbehandlung. Sie haben in diesem Artikel bereits ein paar Methoden kennengelernt, es gibt aber noch weit mehr. Jede dieser Methoden hat Vorteile und Nachteile, es gibt keine beste Lösung hier.
Error Stack
Jeder Fehler, der auftritt, wird auf einen bestimmten Stack gesetzt und die Funktion beendet sich selbst. An bestimmten Codestellen kann man dann auf Fehler testen, die ja alle auf diesem Error Stack liegen. Jeder Code kann einen behandelten Fehler vom Stack poppen - man hat somit ein feineres System was Fehlerbehandlung betrifft, als wir bei Exceptions haben (wo es nur den Zustand Fehler (Exception wurde geworfen) und nicht Fehler (keine Exception geworfen) gibt.
Deferred Error Handling
iostreammacht es vor: wenn ein Fehler auftritt, dann setzen wir ein internes error-flag und teilen so mit, dass etwas schiefgegangen ist.Callbacks
Unter Unix sind Signals recht bekannt, in der Windows-Welt eher nicht. Dennoch bieten Signale eine interessante Möglichkeit Fehler zu handhaben. Jedes Mal wenn ein Fehler auftritt, wird ein Signal generiert, auf das eine Anwendung (oder ein Teil einer Anwendung) per Callback reagieren kann, indem man das Callback für das entsprechende Signal registriert.
Zu diesen 3 Methoden gibt es unter C++ Exception Alternatives auch ein bisschen Lesestoff, wenn Sie mehr erfahren wollen.
Conditions
Nicht jeder Fehler ist ein fataler Fehler. Conditions ermöglichen es, an definierten Stellen von einem Fehler zu recovern.
Fehler passieren und egal, was wir für eine Methode verwenden, um sie zu handhaben, wir müssen achtgeben.
-
Hoho harter Tobak, gut geschrieben. Danke für die Infos!

-
Sehr schön. Gefällt mir.")
-
Ziemlich verständlich und verdammt interessant! Danke dir für den Blick hinter den Vorhang!
-
Ein paar kleine Anmerkungen:
Ich kenne kein std::construct oder std::destroy. Als Referenz könnte man diese Implementation zu benutzen:
template <typename T> void construct(T* where, const T& value) { new (static_cast<void*>(where)) T(value); } template <typename T> void destroy(T* where) { where->~T(); } template <typename BidirectionalIterator> void destroy(BidirectionalIterator first, BidirectionalIterator last) { typedef typename std::iterator_traits< BidirectionalIterator >::value_type value_type; for ( ; last != first; ) (--last)->~value_type(); }sizeof benötigt Klammern, wenn der Operand ein Typ ist. Fehlplatziertes const im Zuweisungsoperator.
Die Verteilung der Aufgaben auf Stack und StackImpl ist verwirrend, da Stack ist für die Erzeugung und StackImpl für die Zerstörung der Objekte zuständig ist. Sinnvoller und einfacher wäre die Verwendung einer einfachen RAII-Klasse, die nur den rohen Speicher als solchen verwaltet. Tatsächlich bietet sich hier ein Smartpointer an - wenn man will, z.B. auch shared_array mit custom-deleter. Dann muss man auch nicht in den Innereien anderer lassen herumpfuschen.
Ein pop(), das den gepopten Wert by Value liefert, kann nie exceptionsicher sein.
Hier wage ich zu widersprechen. Es ist lediglich nicht ganz trivial (und grundsätzlich bin ich auch für die AUfteilung in top und pop - denn je nachdem, wie man ein pop mit return implementiert, hat man nur zwei schlechte Alternativen:
1. wenn das Element trotz Exception entfernt wird, verliert man unwiederbringlich DatenT pop() { if(empty()) throw StackEmptyException(); struct on_exit { stack& s; on_exit(stack& s) : s(s) {} ~on_exit() { destroy(s.impl.data+--s.impl.used); } } on_exit_guard( *this ); return impl.data[impl.used-1]; }2. wenn der Stack bei Exception unverändert bleibt, kann man ihn ggf. überhaupt nicht mehr löschen.
T pop() { if(empty()) throw StackEmptyException(); struct on_exit { stack& s; bool do_pop; on_exit(stack& s) : s(s), do_pop(true) {} ~on_exit() { if (do_pop) destroy(s.impl.data+--s.impl.used); } void dismiss() { do_pop=false; } } on_exit_guard( *this ); try { return impl.data[impl.used-1]; } catch ( ... ) { on_exit_guard.dismiss(); throw; } }
-
camper schrieb:
Die Verteilung der Aufgaben auf Stack und StackImpl ist verwirrend, da Stack ist für die Erzeugung und StackImpl für die Zerstörung der Objekte zuständig ist.
Ist eine gaengige Implementierunsvariante. irgendwas ala shared_X ist einfach nur falsch hier zu verwenden. ein scoped array uU, aber wozu? eine klasse muss nicht immer eine vollstaendig allein funktionierende einheit sein. stackimpl ist nur ein helfer der sich um den speicher kuemmert.
impl ist eine RAII klasse, nur eben keine selbststaendige. aber wozu muss sie eine vollstaendige eigenstaendige klasse sein? welchen vorteil habe ich davon? mehr aufwand. und wiederverwenden kann ich es eh nicht.
-
Frage zum Artikel, da steht, daß man nicht den ganzen Code in einen try-Block setzen soll. Warum nicht?
MFG
-
Weil du dann nicht weißt woher und warum die Exception geflogen ist, könnte quasi ja von überall herkommen. Ist aber oft als "last resort" ganz außen in Programmen üblich.
MfG SideWinder
-
@SideWinder sagte in Modernes Exception-Handling Teil 2 - Hinter den Kulissen:
Weil du dann nicht weißt woher und warum die Exception geflogen ist, könnte quasi ja von überall herkommen. Ist aber oft als "last resort" ganz außen in Programmen üblich.
MfG SideWinder
Im Artikel steht aber auch daß man Exceptions zentral auffangen soll. Das beißt sich schon ein bischen, meinen Sie nicht auch?
Denn: Eine zentrale Fehlerbehandlung funktioniert ja nur wenn die Exceptions entsprechend klassifiziert sind. Und genau damit weiß man auch wo sie gefallen sind. Noch dazu wenn ein Backtrace verfügbar ist.
MFG
-
Beides ist imho richtig: fange kontextlose Exceptions möglichst lokal und kontextbehaftete dann zentral. Ich versuch's mal mit einem Beispiel:
try { auto x = query_database_a(); // wirft network_exception wenn datenbank nicht erreichbar // wenn hier drin noch viele andere query_database_b(), etc. wären, die auch network_exception werfen, wüsste man unten im catch nicht welche datenbank überhaupt die war die nicht erreichbar war => daher möglichst kleiner try/catch-block } catch(network_exception& ne) { // network_exception ist kontextlos, aber weil ich try nur um ein statement rumgemacht habe, weiß ich sofort, dass es sich um ein problem bei query_database_a() handeln muss: throw database_a_error("Could not reach database A."); // diese exception hier kann man nun möglichst zentral catchen und einen error dialog anzeigen oder ähnliches }Hoffe das Beispile hilft. Ist zumindest ein Weg den ich in C#/Java immer gehe, kenne mich mit aktuellem C++ Exception Best Practices nicht aus.
MfG SideWinder
-
ich hatte mal ein Programm (Perl) das lief nicht auf jedem System. Selbst der Kollege der den Code entwickelt hatte wusste nicht warum, außer der Feststellung daß es wohl ein lokales Problem sein müsse.
Kurzerhand setzte ich den ganzen Code in einen try-Block und fand damit raus woran es gelegen hat. Natürlich war es ein lokales Problem aber das war ja vorher schon klar wenns bei allen anderen Kunden läuft nur bei dem einem nicht.MFG
-
zu Deinem Code: Wenn eine
network_exceptionvon der Stange nicht unterscheidet zwischen einer nicht zustandegekommenen Verbindung und einer verlorenen Verbindung ist das ein Grund über eine eigene Klassifizierung nachzudenken, also eigene Exception-Klassen. darüber hinaus gibt es sicher auch in C# und Java Möglichkeiten vor einer Query den Verbindungsstatus abzufragen (ping).
Auf diese Art und Weise muss man nicht jedes Statement in einen eigenen try-Block setzen sondern einfach nur eine gezielte Ex werfen die zentral gefangen wird.MFG
-
Auch wenn eine sehr gute Exception geworfen wird, wird sie evtl. nicht zwischen database_a und database_b unterscheiden wenn es zwei Connections sind die zurselben Art von DB gehen, aber sind natürlich alles konstruierte Beispiele, wenn die Exception gut genug ist, spricht natürlich absolut nichts dagegen den catch-Block so weit außen wie möglich zu machen.
MfG SideWinder
-
so ist es. Es kommt ja auch darauf an, was mit der Exception gemacht werden soll. Ich hatte z.B. mal ein Programm für einen Datentransfer von Oracle nach MySQL zu entwickeln, da kam es nur darauf an, daß dieses Programm bei nicht Erreichbarkeit einer der beiden (egal welche) in einer Warteschleife weiterläuft bis die Verbindung wieder steht.
Schönen Sonntag!
-
Die Aussage ist wohl nur, wenn du innerhalb einer Methode einen try/catch-Block machst, dann ist es best practice ihn so klein wie möglich zu machen. Dass du weit außen ein einziges try/catch rund um app.Run() hast, ist davon nicht betroffen.
MfG SideWinder
-
Ich fahre da zwei Philosophien (je nach Projekt)... Entweder, alles "nach oben" weitergeben - oder aber die try-catch-Blöcke so früh und klein wie möglich wählen, damit man a weiß, was die Exception verursachte, und b ggf. darauf entsprechend regieren kann, ohne das Programm zu beenden.
Ein von @_ro_ro vorgeschlagener Mischmasch führt meines Erachtens nur zu Chaos.
-
@omggg sagte in Modernes Exception-Handling Teil 2 - Hinter den Kulissen:
Ich fahre da zwei Philosophien (je nach Projekt)... Entweder, alles "nach oben" weitergeben - oder aber die try-catch-Blöcke so früh und klein wie möglich wählen, damit mit man a weiß, was die Exception verursachte, und b ggf. darauf entsprechend regieren kann, ohne das Programm zu beenden.
Ein von @_ro_ro vorgeschlagener Mischmasch für meines Erachtens nur zu Chaos.
Ich habe gar nichts vorgeschlagen. Ich finde nur, daß der Artikel in sich widersprüchliche Aussagen trifft.
Im übrigen ist meine Frage immer noch nicht beantwortet. MFG
-
@_ro_ro sagte in Modernes Exception-Handling Teil 2 - Hinter den Kulissen:
@omggg sagte in Modernes Exception-Handling Teil 2 - Hinter den Kulissen:
Ich fahre da zwei Philosophien (je nach Projekt)... Entweder, alles "nach oben" weitergeben - oder aber die try-catch-Blöcke so früh und klein wie möglich wählen, damit mit man a weiß, was die Exception verursachte, und b ggf. darauf entsprechend regieren kann, ohne das Programm zu beenden.
Ein von @_ro_ro vorgeschlagener Mischmasch für meines Erachtens nur zu Chaos.
Ich habe gar nichts vorgeschlagen. Ich finde nur, daß der Artikel in sich widersprüchliche Aussagen trifft.
Im übrigen ist meine Frage immer noch nicht beantwortet. MFG
Kein Grund, aggressiv zu werden oder zu eskalieren ... Ich habe nur den Subtext gedeutet.
-
@_ro_ro sagte in Modernes Exception-Handling Teil 2 - Hinter den Kulissen:
Frage zum Artikel, da steht, daß man nicht den ganzen Code in einen try-Block setzen soll. Warum nicht?
@_ro_ro sagte in Modernes Exception-Handling Teil 2 - Hinter den Kulissen:
Ich habe gar nichts vorgeschlagen. Ich finde nur, daß der Artikel in sich widersprüchliche Aussagen trifft.
Welche Sätze meinst du denn genau? Zumindestens in diesem (Teil-)Artikel finde ich keine Aussagen bzgl. der Vermeidung eines globalen
try...catch-Handlers.
-
Da der Thread bzw der Artikel ursprünglich mal "Modernes Exception Handling" hieß; in modernem C++ gibt es auch andere Möglichkeiten der Fehlerbehandlung, z.B. mit
std::optionaloder noch neuerstd::except. Hier ein Artikel dazu: https://devblogs.microsoft.com/cppblog/cpp23s-optional-and-expected/