PrettyOS Fehler-/Testthread
-
Aktueller Problemstatus bei 0.0.1.43 - Rev: 607:

- vm86 Testcode (ckernel.c, Zeilen 104 - 112) macht Probleme auf real PC
- fdir bleibt hängen (schon länger beobachtet)
-
Aktueller Problemstatus bei 0.0.1.66 - Rev: 635:
- strg + t (ruft scheduler_log() auf) führt zum #PF --> Absturz
- fdir bleibt hängen (schon länger beobachtet) --> Absturz
EDIT: alles erledigt

-
im IRC:
<somone>MrX: ich habe mal versucht ein userprogramm zu schreiben mit, fgets u. fputc, aber qemu bringt fehlermeldungen, das ich nicht schreiben oder lesen kann...
<somone>FLOPPY ERROR: fdctrl_write_data: can't write data in status mode
<somone>FLOPPY ERROR: fdctrl_read_data: can't read data in CMD stateEDIT: ich habe die syscall-Nr. korrigiert
-
seit 0.0.1.131 werden "reboots" verzeichnet, die im Ablauf - nicht reproduzierbar - eintreten (qemu, PC). MrX: action please.
general protection fault: err_code: 65276 adress(eip): 00113d10h...
-
Da dies der Testthread von PrettyOS ist ,wollte ich meinen Test wiedergeben.
Also ich habe das Image des .tar.gz Archives verwendet ,welches ich von ehenkes bekommen habe.
Dies habe ich natürlich prompt mit meiner Sun VirtualBox unter meinem Ubuntu getestet.
Die Hardwareerkennung schien gut zu laufen zumindest ,wenn es nach der Ausgabe von PrettyOS ging.
Dann bin ich in der ,für meine Verhältnisse unübersichtlichen, Shell gelandet.
Sie ist deswegen unübersichtlich ,weil unter und über der Eingabe ,in der die eingegebenen Zeichen erscheinen, Text beziehungsweise ein Zug zu sehen ist und man erst suchen muss.
Als ich damit zurecht gekommen bin habe ich help eingeben und die implementierten Funktionen/Befehle getestet.
Alles hat funktioniert außer reboot.
Und noch etwas ,was aber wahrscheinlich so gehört, ist ,dass mit dem Befehl fformat das Floppyimage nicht mehr PrettyOS gebootet hat.
Also in diesem Sinne einen Gruß von mir und hoffentlich hilft euch mein Rückblick.
tev
-
vielen dank für das feedback. wir sind auch an weitergehenden tests aller art interessiert.
tastenkombis
strg+t (screenshot ==> floppy),
strg+u (screenshot ==> usb-stick),
ESC+h (Heap regions anzeigen)
-
PrettyOS 0.0.1.166 - Rev: 744
wenn ich hello starte und in konsole m strg+t ausführe, landet der ausdruck bei konsole 0, also bei hello (unerwartetes verhalten)
-
ein übler fehler wurde entdeckt:
zwischen svn rev. 579 und 580 ging das strg+s "kaputt". Test: img in qemu starten, strg+s, fdir (directory zerstört)
Der erste Screenshot (strg+s) überschreibt boot2.bin (cluster #2 u. #3) und den ersten cluster (#4) von kernel.bin. Damit kann qemu PrettyOS nicht mehr starten.
Dass dies über eine lange Strecke nicht entdeckt wurde, zeigt, wir brauchen einen vorgeschriebenen Testablauf, zumindest alle 10 commits, damit wir zeitnah Fehler entdecken. Hier bitte ich um Vorschläge.
-
Ich versuche zunächst zur Fehlerbehebung den genauen Fehler einzugrenzen:
FS_ERROR FAT_fputc(file_t* file, char c) { uint32_t retVal = FAT_fwrite(&c, 1, 1, file->data); /// TEST static uint32_t i=0; i++; printf("\tfputc %u ",i); /// TEST if (retVal == 1) { /// TEST printf("OK "); if (i==4098) { waitForKeyStroke(); } /// TEST return(CE_GOOD); } return CE_WRITE_ERROR; }Damit kann man den FAT_putc verfolgen. Nach dem 4098ten (video screen + zeilenumbruch) FAT_fputc wird qemu gestoppt und abgebrochen. Schaut man sich dann per EDITDISK boot2.bin und kernel.bin mit dem hex-editor an, so stellt man fest, dass diese Dateien unbeschädigt sind. screen.txt ist angelegt mit Größe 0 byte. Es fehlt also noch der dir-entry-Eintrag.
Lässt man das waitForKeyStroke() durch Bestätigung in qemu weiter laufen, so wird boot.bin komplett mit 0 überschrieben und kernel.bin im ersten Sector genullt.
Fazit: FAT_putc richtet hier keinen direkten Schaden an.
---------------
Nächster Versuch:
static uint32_t cluster2sector(FAT_partition_t* volume, uint32_t cluster) { //..... // #ifdef _FAT_DIAGNOSIS_ printf("\n>>>>> cluster2sector<<<<< cluster: %u sector %u", cluster, sector); if (sector < 100) waitForKeyStroke(); // #endif return (sector); }Hierbei fällt bei strg+s im unteren Bereich nur die Zahl "sector 19" an. Die Daten des Screenshots werden beginnend ab 0x51000 (sector 648 = 617+31) abgelegt. Dies führt auch nicht weiter.
Die Daten, die z.Z. überschrieben werden, beginnen ab sector 33.
---------------
... und weiter gehts:
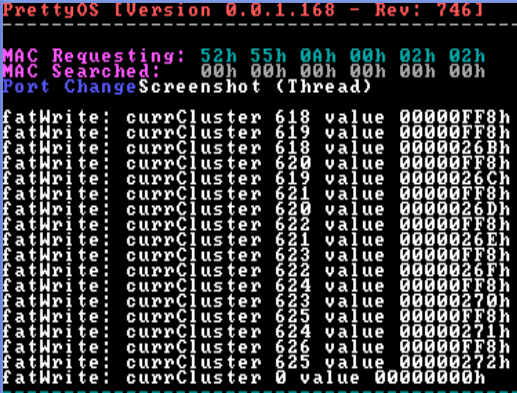
static uint32_t fatWrite (FAT_partition_t* volume, uint32_t currCluster, uint32_t value, bool forceWrite) { /// TEST printf("\nfatWrite: currCluster %u value %X", currCluster, value); /// TESTfat.h
#define LAST_CLUSTER_FAT12 0xFF8http://www.henkessoft.de/OS_Dev/Bilder/0_0_1_168_Analyzing_Bug_Screenshot.PNG
Im Ergebnis sieht das aber gut aus:

http://www.henkessoft.de/OS_Dev/Bilder/0_0_1_168_Analyzing_Bug_Screenshot_a.PNG
-
Im irc:
<DerHartmut>
Testen: Jede sinnvolle Plattform, sprich: Mindestens 3 Virtuelle Maschinen und 2 Real-PCs (wenn nicht möglich dann halt nicht möglich), Funktion der Änderung testen, ggf. Testcode einbauen (bei Commit wieder entfernen), eventuelle Wechselwirkungen beachten und andere Stellen testen, falls Wechselwirkungen vorhanden.Also ich persönlich <DerHartmut> mache das so
1. Code schreiben
2. Compillieren, bis er sauber durchbaut
3. Testcode schreiben (falls nötig), mit printf() mögliche Ausgaben ausgeben
4. Ist vom Code noch anderer Code betroffen?
5. Rekursion!
6. Alles klappt? Testcode entfernen, nochmal durchbauen
7. Committen
-
Ich habe nun alle Schreibvorgänge protokolliert:
http://www.henkessoft.de/OS_Dev/Bilder/0_0_1_168_Analyzing_Bug_Screenshot_b.PNG2: FAT1 11: FAT2 19: Root Directory 648 ff.: DataDa sieht man keinen "Angriff" auf Sektor 33-35 (0x4200 ff.)
Da würde dort ja auch etwas anderes stehen als lauter Nullen.
-
Es liegt am Readcache. Der genaue Fehler muss noch gefunden und beseitigt werden.
-
Vorbemerkung: Unerkannte Bugs sind ein echtes Problem, weil sie an unpassender Stelle zuschlagen können, vor allem in Kombination, und Verwirrung stiften.
Bugs müssen zeitnah erkannt werden, da man so am besten reagieren kann. Daher wird hier ein systematischer Test vorgeschlagen.
Dinge, die man ständig beim Ausführen von PrettyOS implizit testet, werden ausgelassen, z.B. Boot-Verhalten.Test für PrettyOS (sollte alle 10 commits durchgeführt und dokumentiert werden):
---------------------------------------------------------------------------------CPU:
FPU-Test (should be implemented at ESC+f)Memory:
recognized correctly? (should be implemented at ESC+m)Keyboard:
Are AltGr keys recognized? Test known combinations of strg+key or ESC+key?Video/Monitor:
Physical Address of grafics card?
Which vbe modes are shown?
Does vbe grafics work properly?Tasking/Scheduler:
Start different programs in their own consoles. Check with strg+t.
Change freqency at timer_install(100). Try 1000 Hz.Floppy Disk Device:
Please test the sequence strg+s, fdir, strg+s, fdir.
Load "arrow" two times.USB mass storage devices:
Try FAT16 and FAT32 (and FAT12 if possible):
Please test the sequence strg+u, strg+u, strg+u. Test the Directory and the content of screenshot (3 texts in "screen.txt").Networking:
Describe environment. Test ARP reply, PING reply. All incoming packets recognized?User Library:
Load program "test" (to be developed).Bitte um Mithilfe, diesen Test weiter auszuarbeiten.
-
Neben der Optimierung des äußeren Testens (eigentlich Overhead) gilt es, folgende Strategie verstärkt zu beachten:
- Loggen/Visualisieren
- Internes Testen durch PrettyOS selbst
- Verstärkte Kommunikation bezüglich Änderungen bei Memory und Prozess Management (hier sind ausführliches Loggen und Tests bei mehreren Umgebungen unerlässlich, um Fehler möglichst früh zu detektieren und zu debuggen)
-
problem im task management:
0.0.1.223 - Rev: 807
...
current task: pid: 6
running tasks:
pid: 5 esp: C020CEB0h eip: 001150DEh PD: 01021000h k_stack: C020D000h
parent: 0
pid: 0 esp: 0018FF00h eip: 00000000h PD: 01021000h k_stack: 00000000h
child-threads: 5
pid: 6 esp: C02055C0h eip: 001150DEh PD: 01021000h k_stack: C0205720h
parent: 0
blocked tasks:
pid: 3 esp: C0002F70h eip: 001150DEh PD: C0208000h k_stack: C0003120h
freetime task:
pid: 1 esp: C0001054h eip: 001150DEh PD: 01021000h k_stack: C00010A8hpid0 hat 2 kinder, verleugnet aber eines davon
-
http://www.c-plusplus.net/forum/viewtopic-var-p-is-1948598.html#1948598
Der neue beschleunigte Lesevorgang bewirkt massive Kollateralschäden. strg+s zerschlägt z.B. so einiges. Um Analyse / Behebung wird gebeten, damit wir das beschleunigte Lesen beibehalten können.
-
Wir tappen bei dem Fehler bislang im dunkeln. Ich fasse mal hier kurz zusammen, was ich festgestellt habe (auch um selbst den Überblick zu behalten):
Das bloße abstellen des neuen Cachings (z. 616 auskommentieren) bewirkt keine Besserung (aber natürlich eine Lese-Verlangsamung, weil für jeden Sektor der Track neu gelesen wird (trackweise!)).
-> Am Caching liegt es nicht.Eine Umstellung auf sektorweises Lesen bewirkt keine Fehler bei strg+s.
-> Es hat was mit dem trackweisen Lesen zu tunLeert man den DMA_BUFFER, bevor man schreibt (und schreibt anschließend das rein, was man schreiben will), verändert dies den Zustand des Floppyimages nach strg+s. Korrekt wäre, wenn sich nichts ändern würde am Verhalten.
-> Es scheint, als würde fälschlicherweise ein ganzer Track (oder zumindest mehr aus dem DMA_BUFFER als nötig) geschrieben.
-
Es scheint, als würde fälschlicherweise ein ganzer Track (oder zumindest mehr aus dem DMA_BUFFER als nötig) geschrieben.
Hier liegt der Hebel. Das passiert auch, wenn man Zeile 616 auskommentiert und Zeilen 625 und 655 (anstelle 624 u. 654) verwendet!
-
Das Rätsel ist gelüftet.
Erklärung: Die meisten Floppy-Treiber, die ich bislang gesehen habe (z.B. Tyndur und CDI), inklusive zahlreicher Seiten zum FDC (lowlevel-wiki, osdev.org) sind fehlerhaft. Wir merken es nur, weil unsere DMA-Implementation marode ist.
Der Schlüssel ist Bit 7 des Kommandos an den FDC beim lesen/schreiben eines Sektors. lowlevel war (ist jetzt korrigiert) der Meinung, dort müsste die Anzahl der Sektoren pro Track stehen.
Osdev.org behauptete, dort müsste die Anzahl der zu lesenden Sektoren stehen.
Die Treiber, die ich auch zu Rate gezogen habe folgten dem lowlevel-Vorschlag.Nachdem ich auf einen Kommentar im CDI-Treiber gestoßen bin (der die richtige Info enthielt, sie aber nicht anwendete im Code) wurde mir das Problem klar. Kwolf/taljeth und ich haben in #lost dann darüber diskutiert, wer Recht hat und letztlich fanden wir auch in der offiziellen Spec den Hinweis, das dort der letzte zu bearbeitende Sektor stehen muss. Steht dort 18, wird bis zum letzten Sektor des Tracks gearbeitet (Also trackweise, wenn man von 1 an liest^^). (Beim lesen ists ja ohnehin egal, ob zuviel gelesen wird.)
Bei uns wurde durch die falsche Angabe zuviel geschrieben, bei tyndur aber nicht. Das liegt am DMA-Treiber. Die zweite Begrenzung für die geschriebene Datenmenge ist die Datenmenge, die DMA dem FDC gibt. Das ist bei uns falsch eingestellt (immer Trackgröße), bei tyndur hingegen richtig (Sektorgröße, wenn nur ein Sektor gelesen/geschrieben wird)
-
Hervorragende Leistung! Da bin ich mal auf die nächste Version gespannt, ob der Hexeditor endlich Entwarnung geben kann.
Ja, hat geklappt! Echt klasse.
{kind=link}
{kind=link}
{kind=link}