Wann kommt die nächste CPU-Generation?
-
Was wäre denn der Vorteil an diesen ARM CPUs? Bis jetzt finde ich nur Energie-Effizienz. Wären die leistungsstärker als ein Intel? Billiger? Oder was?

-
Cpp_Junky schrieb:
Was wäre denn der Vorteil an diesen ARM CPUs? Bis jetzt finde ich nur Energie-Effizienz. Wären die leistungsstärker als ein Intel? Billiger? Oder was?
Kein bis zu 32 Jahre alter Ballast, was in der Zukunft einfach ein gewaltiger Vorteil sein wird.
-
Ethon schrieb:
Kein bis zu 32 Jahre alter Ballast, was in der Zukunft einfach ein gewaltiger Vorteil sein wird.
Du glaubst doch nicht ernsthaft, dass Intels x86er nennenswerte Nachteile hätten, bloß weil sie irgendwo in der Schaltung noch ein A20-Gate haben?
-
Ne aber das Design ist (mittlerweile) übermaeßig komplex.
-
Cpp_Junky schrieb:
Was wäre denn der Vorteil an diesen ARM CPUs? Bis jetzt finde ich nur Energie-Effizienz. Wären die leistungsstärker als ein Intel? Billiger? Oder was?
das problem ist, dass der ertrag von leistung nicht linear mit dem aufwand steigt. ein atom single core ist schneller als ein ARM dual core. Deswegen wuerde ich nicht sagen dass ARM effizienter ist, weil man unterschiedliche leistung und verbrauch vergleicht. Zu sagen bei doppelter leistung wuerde ARM doppelt soviel verbrauchen und damit weniger als ein ATOM dual-core ist eine Milchmaenchenrechnung.
Aber es macht fuer intel auch keinen sinn jetzt eine schwache CPU zu machen nur damit sie in den verbrauchsregionen von ARM liegt, da die evolution ja eher andersrum geht.
auch ARM wird mehr leistung aus ihren CPUs kratzen muessen, neue features wie 64bit und virtualisierung verbauen und je naeher sie an intel (Atom) kommen, desto weniger effizient sind sie.
Entsprechend geben die bei jeder neuen generation viel marketing bla bla von sich, ganz verschweigend, dass die vergleiche die sie zur vorherigen generation ziehen ganz andere herstellungsprozesse handelte.Am ende ( selbst wenn wir annehmen die ARM engineers koennen es mit Intels mithalten, wenn es auf Leistung ankommt ) wenn Intel es durchhaelt immer 1 1/2 generationen voraus zu bleiben, beim herstellungsprozess, werden die anderen hersteller von CPUs/GPUs nicht mithalten koennen. Und das ist nichts was man aufholen kann, denn das aufbauen von Fabs kostet milliarden, das erforschen neuer tech erfordert es, dass man die vorherige generation voll beherrscht, das muesste man also als lizens einkaufen und teure engineers abwerben. Ich denke, dass nichtmal apple sich das leisten koennte nur um ihre ARMs konkurenzfaehig zu produzieren.
das einzige was Intel zu fall bringen koennte, waeren sie selbst.
Leider wissen die das auch, deswegen gibt es seit 6+ Jahren nur quadcores fuer die breite masse, ganz ohne konkurenz. Die margen duerften mittlerweile anorm sein, bestenfalls die iGPUs werden verbessert, aber ich habe keine Ahnung wie Intel damit auf lange zeit irgendwas bei CPUs noch reissen will. Haswell soll 2014 fuer server bis 16Cores haben, auf desktop-mainstream bleiben wir vermutlich bei 4cores.Vielleicht ersetze ich meinen Penryn durch Haswell, weil es AVX2 mit Gather/Scatter instruktionen gibt, aber dann werde ich vermutlich auf die 6core version ein bis 2 jahre warten muessen, fuer 200Euro aufschlag :(...
-
Cpp_Junky schrieb:
Was wäre denn der Vorteil an diesen ARM CPUs? Bis jetzt finde ich nur Energie-Effizienz. Wären die leistungsstärker als ein Intel? Billiger? Oder was?
Möglicherweise eine schnellere Bootzeit, der PC startet nämlich im Real Mode und das BIOS macht alles nach der Reihe, das ist alles nicht unbedingt schnell.
Ob's mit UEFI anders ist, weiß ich nicht, da ich keinen UEFI basierten x86 PC habe.Bei ARM würde dieser ganze Ballast jedenfalls nicht vorhanden sein und das bischen Firmware das die haben ist schnell geladen.
-
rapso schrieb:
Aber es macht fuer intel auch keinen sinn jetzt eine schwache CPU zu machen nur damit sie in den verbrauchsregionen von ARM liegt, da die evolution ja eher andersrum geht.
auch ARM wird mehr leistung aus ihren CPUs kratzen muessen, neue features wie 64bit und virtualisierung verbauen und je naeher sie an intel (Atom) kommen, desto weniger effizient sind sie.
Entsprechend geben die bei jeder neuen generation viel marketing bla bla von sich, ganz verschweigend, dass die vergleiche die sie zur vorherigen generation ziehen ganz andere herstellungsprozesse handelte.Also einen Vorteil hat hier ARM.
Die brauchen nicht so viele Transistoren verbauen, wie es bei x86 CPUs notwendig ist nur um so ne Art RISC Architektur mit µOpcodes für die virtualisierte x86 CISC Architektur zu realisieren.Transistorballast ist da also schon vorhanden, bei den modernen x86ern.
Bei ARM fällt dieser weg.das einzige was Intel zu fall bringen koennte, waeren sie selbst.
Leider wissen die das auch, deswegen gibt es seit 6+ Jahren nur quadcores fuer die breite masse, ganz ohne konkurenz. Die margen duerften mittlerweile anorm sein, bestenfalls die iGPUs werden verbessert, aber ich habe keine Ahnung wie Intel damit auf lange zeit irgendwas bei CPUs noch reissen will. Haswell soll 2014 fuer server bis 16Cores haben, auf desktop-mainstream bleiben wir vermutlich bei 4cores.Vielleicht ersetze ich meinen Penryn durch Haswell, weil es AVX2 mit Gather/Scatter instruktionen gibt, aber dann werde ich vermutlich auf die 6core version ein bis 2 jahre warten muessen, fuer 200Euro aufschlag :(...
Ja, das kennen wir von Intel ja.
-
Rein ideologisch wäre ich auch für eine Architektur, bei der der ganze Ballast an unnötigem Zeug nicht eingebaut ist. Ich denke schon, dass dadurch die Leistung möglicherweise zumindest ein bisschen geschmälert wird. Es geht ja nicht nur um Zeug wie das A20-Gate, sondern auch um die ganzen inzwischen überflüssigen Instruktionen, die es sicherlich gibt (wird ernsthaft noch ein Gleitkomma-Koprozessor eingebaut? Ich müsste jetzt nachschauen, aber eigentlich hatte ich mir vorgenommen, nicht mehr eine Stunde pro Foreneintrag zu brauchen
") (die Zahl ist nicht rein erfunden oder übertrieben))
(die Zahl ist nicht rein erfunden oder übertrieben))
Selbst wenn nicht, dann gibt es bestimmt andere Probleme.
Ich fand das Konzept mit VLIW eigentlich ziemlich gut, ich weiß gar nicht, wieso das nicht so gut ankam. Compiler muss man einmal umschreiben. Alle Programme, die dann damit für die neue Plattform übersetzt werden, profitieren automatisch von der theoretisch besseren Leistung (wenn der Prozessor nicht mehr so viel selbst tun muss, müsste das doch eigentlich grundsätzlich in bessere Laufzeiteigenschaften münden)Leider denke auch ich, dass Intel im Moment keine echte Konkurrenz hat und hoffe, dass sie die Preise zumindest nicht zu übertrieben hoch setzen, denn es hält sie ja eigentlich wenig davon ab (ich brauch dann schätzungsweise im nächsten Monat einen Prozessor und die Preise bewegen sich sogar bei Sandy-Bridge schon wieder nach oben: http://geizhals.at/de/?phist=580328, http://geizhals.at/de/?phist=731595)
So ohne Konkurrenz ist das schon blöd (für den Verbraucher).SeppJ schrieb:
So wie viele Autohersteller auch immer einen flotten Rennwagen im Angebot haben, weil dies positive Assoziationen für ihr Klein- und Mittelklassesegment weckt.
Joa, das ist durchaus plausibel. Die Analogie geht sogar insofern weiter, dass die Prozessoren dann auch so viel kosten wie die flotten Rennwagen (im Verhältnis) …

(Kommt mir wegen dem gesenkten Daumen bitte ned mit Gefasel vonwegen, das sei ja eine Firma und dass die so Handeln sei ganz klar. Ist mir bewusst, finde ich aber trotzdem scheißen. (Nur zur Absicherung, weil ich das erwartet hätte))
-
sdf_ausgeloggt schrieb:
rapso schrieb:
Aber es macht fuer intel auch keinen sinn jetzt eine schwache CPU zu machen nur damit sie in den verbrauchsregionen von ARM liegt, da die evolution ja eher andersrum geht.
auch ARM wird mehr leistung aus ihren CPUs kratzen muessen, neue features wie 64bit und virtualisierung verbauen und je naeher sie an intel (Atom) kommen, desto weniger effizient sind sie.
Entsprechend geben die bei jeder neuen generation viel marketing bla bla von sich, ganz verschweigend, dass die vergleiche die sie zur vorherigen generation ziehen ganz andere herstellungsprozesse handelte.Also einen Vorteil hat hier ARM.
Die brauchen nicht so viele Transistoren verbauen, wie es bei x86 CPUs notwendig ist nur um so ne Art RISC Architektur mit µOpcodes für die virtualisierte x86 CISC Architektur zu realisieren.Transistorballast ist da also schon vorhanden, bei den modernen x86ern.
Bei ARM fällt dieser weg.das ist vorteil und nachteil zugleich.
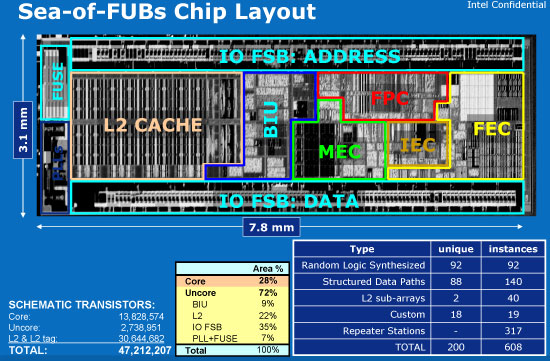
schauen wir uns erstmal den riesigen decoder bei AMD an der fuer ineffiziens sorgt: http://www.extremetech.com/wp-content/uploads/2012/01/BobcatHotChips_August24_8pmET_NDA-17_575px-640x359.jpgIntel Atom (FEC "front end cluster" beinhaltet decoder,branch predictor,instruction cache, thread prefect buffer etc.)
http://images.anandtech.com/reviews/cpu/intel/atom/deepdive/seaoffubs.jpgbeim ARM cortex A9 (ISide beinhalten instruction fetcher und decoder):
http://www.heise.de/imgs/18/4/0/3/7/0/5/48cbe50d1b687e15.pngwie du siehst, es ist ein relativ kleiner teil der CPU der overhead sein soll, und bei ARM ist es nicht sonderlich weniger als bei atom.
zum einen hat ARM "thumb" weil es effizienter ist als die 32bit RISC befehle, besonders im hinblick drauf dass oft nur 16bit speicher an ARM cpus angeschlossen wird. zwei decoder im ARM und dennoch sehen die das als vorteil, da ist intels version nicht so dramatisch, finde ich. natuerlich sind intels instructions komplexer, aber dafuer sind sie sehr kompakt, manchmal hast du 1byte ops manchmal 18byte, die 1byte instructions werden (bzw wurden) sehr oft verwendet, die langen eher selten und wenn, dann ersetzen sie meistens viele voneinander abhaengende operationen wie z.b. mehrere addressen+offsets laden, verrechnen und anhand dessen den finalen wert zu laden. Das geht bei intel meist mit einer einzigen instruktion.
Wenn du fuer arm optimierst, wirst du schnell an den cache oder IRam (expliziter cache) limit kommen, 16kb bei 4byte/instruction sind jaemmerliche 4096instructions.
bei intel kannst du quasi "thumb" und "arm" isa simultan nutzen. ein compare, ein jump sind je 2byte, ein mov mit zero extend sind 4bytes, bei ARM ist compare und branch je 4byte, move udn zero extend 2x 4byte. und waehrend berechnungs leistung stetig steigt, ist man immer mehr speicher limitiert. kleinere instructions -> mehr im cache.zur 80x86 zeiten war der decoder vermutlich ein ziemlich grosser teil von der CPU, jetzt ist das eigentlich nicht mehr wirklich relevant.
hier nochmal (ganz unten) der verbrauch von Atoms http://www.anandtech.com/show/5365/intels-medfield-atom-z2460-arrive-for-smartphones/2
wie man siehst, ist die effiziens irgendwo zwischen 600Mhz und 1.3GHz, 100Mhz ist im ineffizientesten, dicht gefolgt von 1.6GHz, das ist nicht viel anders bei ARM. die Corex dinger die in den meisten geraeten mit 1GHz laufen, wurden mit 'bis zu 2GHz' beworben, afaikdie zukunft duerfte intel zuspielen.
-
Fast2_unreg schrieb:
wird ernsthaft noch ein Gleitkomma-Koprozessor eingebaut?
jup, FPU bei x86 und VFPU bei ARM, obwohl es SSE/AVX/NEON gibt. wobei das bei intel und amd wohl von den selben einheiten berechnet wird, lediglich die register sind wohl overhead.
Ich fand das Konzept mit VLIW eigentlich ziemlich gut, ich weiß gar nicht, wieso das nicht so gut ankam. Compiler muss man einmal umschreiben. Alle Programme, die dann damit für die neue Plattform übersetzt werden, profitieren automatisch von der theoretisch besseren Leistung (wenn der Prozessor nicht mehr so viel selbst tun muss, müsste das doch eigentlich grundsätzlich in bessere Laufzeiteigenschaften münden)
wo soll ich da nur anfangen
")
weil VLIW extrem komplex zu compilieren ist. von GPUs her sehe ich, dass eine grosse auslastung der einheiten nie moeglich ist. wenn viel code da ist (und ich meine VIEL), dann kann man den compiler eine stunde beschaeftigen wenn man will, dann hat er etwas was so ca 99% des mit diesem code moeglichen macht und lastet dann vielleicht 60%-80% aus. Dabei muss man als mensch wirklich viel zeit investieren, du kannst dir eine woche den kopf zerbrechen und im vormals vermeintlich perfekten code dann doch noch ein cycle sparen, dabei hast du dann die ganze funktion total ummutiert (weil es so tiefgreifende dependencies gibt). und ich spreche von dingen mit vielleicht 32instruktionen. ein cycle sparen kann bedeuten, dass du viel mehr instruktionen verbaust. ich habe mal eine, port beigebracht mittels maskieren und loads eine 'OR' instruktion zu emulieren, im static code analyser war es dann 8cycles schneller(weil 8x unrolled, danach war ich out of registers), im echten leben war es dann langsammer, weil ich alle VLIW ports ausnutzte, dadurch soviel memory bandbreite zog, dass es nicht mehr fuer den OR-trick reichte (das war eine architektur die automatisch "NOPs" einbaute falls eine instruktion kam die die cpu auf diesem port nicht konnte und dadurch viel bandbreite sparte).
du hast sehr viele limits zu beachten:
-nicht alle einheiten koennen alles, aber viele instruktionen sind mehrfach vorhanden bzw koennen substituiert werden, z.b. koennte eine einheit shiften, eine addieren, eine multiplizieren und du hast 3 wege um "a*=2;" zu machen. eventuell brauchst du (z.b. bei mul) ein temporaeres register mit einer 2. vielleicht ist irgendwo im VLIW eine instruction frei um das zu laden, oder du hast andere instructions frei um die 2 zu erstellen, oder du behaelst, weil du ja sehr viele register wegen VLIW hast, einfach irgendwoe immer eine '2', weil man sie oefter braucht? und das nur wegen einer instruktion!
-du hast eine limitierte bandbreite im chip, wenn du z.b. ein "a=b*c+d;" als instruktion hast, brauchst du 4 verschiedene register, eventuel hast du bei dem VLIW4 ein limit von insgesaamt 8registern, falls die anderen instruktionen schon viele register brauchen, musst du destruktiv "d=b*c+d" sein und d dann, wie im vorherigen punkt, eventuell anders fuer nachfolgende befehle besorgen. oder du schedulest diesen befehl jetzt so, dass er der letzte ist der d braucht, natuerlich kannst du die 3 anderen die damit gepaart waren nicht mit umsortieren, wobei du dann ja wiederrum in einen ganz anderen instruction slot kommst mit ganz neuen limitierungen.
-obwohl VLIW4 4unabhaengige instructions erstellen kann, kann es sein dass manche sich die einheiten teilen, z.b. ist eine division und wurzel funktion auf aenliche operationen angewiesen, aber durchaus mal auf anderen ports implementiert.weiter siehst du bei einer statischen analyse von programmen, das meistens eine quelle existiert z.b. bei
for(int a=0;Error>0.1;a++) { float x=a*a+a..; }am anfang des loops ist also meist nur eine instruction nach der anderen am abarbeiten, oft mit dependancies und da VLIWs dazu neigen sehr tiefe pipelines zu haben (jedenfalls die die ich kenne), vergehen da ein paar duzent cycles.
danach ist es oft so dass am ende aus den berechnungen wieder eine reduction stattfindet, bei der viele daten zu wenigen zusammengesetzt werden, z.b.
for(int a=0;Error>0.1;a++) { float x=a*a+a..; . . . Error = sqrtf(fabsf(y-x)); }auch dabei wird VLIW sehr ineffizient.
der code-flow bricht die optimierungspotentialle, das schlimme ist, dass du wegen VLIW viele register brauchst und an branch stellen ist es selten effizient wie man die verwalten kann.
vom chip her: der decoder ist ein winziger teil, die execution units ziehen 90% vom die und 40% davon hast du quasi umsonst rumliegen. deswegen wurden GPUs auf skalar umgestellt, mit der G80 von NVidia und dem GCN von AMD.
(Intel hat noch VLIW soweit ich weis, mit 128bit pro instruction.)
Leider denke auch ich, dass Intel im Moment keine echte Konkurrenz hat und hoffe, dass sie die Preise zumindest nicht zu übertrieben hoch setzen, denn es hält sie ja eigentlich wenig davon ab (ich brauch dann schätzungsweise im nächsten Monat einen Prozessor und die Preise bewegen sich sogar bei Sandy-Bridge schon wieder nach oben: http://geizhals.at/de/?phist=580328, http://geizhals.at/de/?phist=731595)
So ohne Konkurrenz ist das schon blöd (für den Verbraucher).ich glaube die preise bleiben relativ gleich ueber die jahre, hab damals meinen quadcore Q9450 fuer ca 300euro gekauft, jetzt bekommst du den besten auch fuer diesen preis. haette intel konkurenz, waeren wir sicher so wie frueher nicht weit von den XEONs entfernt (also 10core) und was mainstream von server unterscheiden wuerde, waere nur die multi socket untersteutzung.
{kind=link}
{kind=link}
{kind=link}