[X] Eine MFC-Anwendung Unicodefähig machen
-
CStoll schrieb:
Wie oben gesagt, solltest du die generischen Stringfunktionen zumindest erwähnen (von allen klassischen Funktionen gibt es eine wchar_t-Version und ein Hilfsmakro, das je nach UNICODE-DEfinition auf die "richtige" Version umgebogen wird).
Werde es demnächst dementsprechend ändern und anschließend wieder posten.
-
Eine MFC-Anwendung Unicodefähig machen
Inhaltsverzeichnis
- Einleitung
- Was ist Unicode?
- Woran erkennt man eine Unicode Datei?
- Wie kann man Unicode in einer eigenen MFC-Anwendung nutzen?
- Worauf muss nun in der MFC-Anwendung geachtet werden?
- Kleines Beispiel anhand einer Unicode Textdatei
- Speziellen Dank an Alexander Müller
Einleitung
Dieses Artikel handelt von dem so genannten Unicode Standard.
Hier wird nur auf den Unicode Standard UTF 16 eingegangen. Neben diesem existieren noch die UTF Standards 32, 8, 7 (veraltet), EBCDIC. Wer mehr Informationen zu den in diesem Artikel nicht genannten UTF Standards benötigt, kann auf der Internetseite von Wikipedia ( http://de.wikipedia.org/wiki/UTF ) mehr dazu erfahren.
Für das erzeugte Beispiel wurde Visual Studio C++ 6.0 genutzt.Was ist Unicode?
Bisher wurde stets davon ausgegangen, daß ein Zeichen in ein Byte hineinpaßt, und dies hat auch einige Jahre problemlos funktioniert. Nun lassen sich in einem Byte aber maximal 256 verschiedene Zeichen darstellen. Unser Alphabet hat zwar nur 26 Zeichen, aber die übrigen Zeichen waren ebenfalls schnell reserviert, sei es für Steuerzeichen, Leerzeichen, Symbole und so weiter. Die ersten 127 Zeichen sind als "ASCII" - Tabelle bekannt und enthalten alle Klein- und Großbuchstaben des lateinischen Alphabets. Häufige Verwendung findet auch die "ANSI" - Tabelle, die in den ersten 127 Zeichen mit ASCII übereinstimmt, und in den hinteren 128 Zeichen weitere Zeichen enthält, unter anderem auch die deutschen Umlaute.
Es hat sich jedoch gezeigt, daß ein Byte einfach zuwenig ist, um alle möglichen Zeichen aus allen Welt - Alphabeten einheitlich darzustellen. Also wurde Unicode als Standard erfunden. Unicode ist eine Zeichentabelle, die 32767 verschiedene Zeichen ermöglicht, weil jedes Zeichen 2 Byte (= 16 Bit) groß ist. Auch Symbole wie Euro, Dollar und britisches Pfund haben dort ihren eindeutigen Platz. Der Nachteil ist jedoch, daß jedes Zeichen 16 Bit Platz braucht, und daß dies natürlich Texte und Strings auf die doppelte Größe aufbläht.
Woran erkennt man eine Unicode Datei?
Woher weiß jetzt eine Textverarbeitung wie Word oder Notepad, ob in einer Textdatei, die geöffnet werden soll, Unicode oder 1-Byte-Zeichen verwendet werden ? Es hat sich durchgesetzt, daß Unicode - Textdateien stets mit den beiden Bytes "FF FE" beginnen, daran wird diese Erkennung festgemacht. Daher sollte man diesen Code auch selbst verwenden, wenn man Unicode-Dateien erzeugt.
Wie kann man Unicode in einer eigenen MFC-Anwendung nutzen?
Im ersten Schritt müssen wir dem Compiler mitteilen das wir in unserer Anwendung Unicode nutzen wollen und er dies beim kompilieren berücksichtigen soll. Dies erreichen wir durch das definieren des Makros _UNICODE!
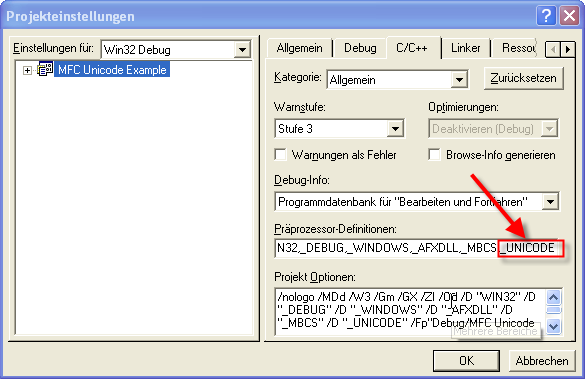
Da wir Unicode nutzen wollen benötigen wir für die MFC-Anwendung ein anderer Einstiegspunkt (wWinMainCRTStartup). Diesen können wir ebenfalls über die Projekteinstellungen definieren.
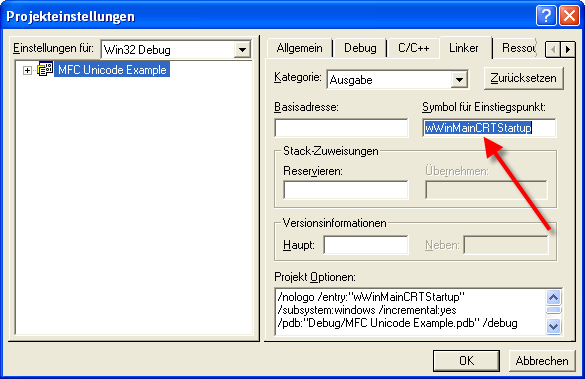
Worauf muss in einer MFC-Anwendung geachtet werden?
Wir müssen beim Programmieren darauf achten das wir unsere Texte die wir im Quellcode Hard kodieren mit dem Makro _T("") umschließen. Dieses Makro kümmert sich um die Konvertierung der Zeichen wenn _UNICODE definiert ist.
Aus
CString szText = "Hallo Welt";wird
CString szText = _T("Hallo Welt");Die CString Klassen können wir ganz normal weiternutzen, da diese Unicodefähig ist. Bei manchen Befehlen ist es möglich das wir diese durch die Unicodefähigen Alternativen ersetzen müssen. Beispiel hierfür wäre der Befehl strcpy der durch den Befehl wcscpy ersetzen zu wäre. Für die meisten klassischen Funktionen ist eine eine wchar_t Version vorhanden.
Hier ein paar Beispiele solcher Befehle:
Funktionsname => wchar_t Versionstrcpy => wcscpy
strcat => wcscat
fopen => _wfopenManche Klassen wie die CString Klasse nutzen automatisch die richtige Funktion. Dies wird durch eine Define Anweisung in der Klasse geregelt.
Kleines Beispiel anhand einer Unicode Textdatei
Da wir zum Laden einer Unicode Datei nicht mehr die normale Klasse CStdioFile nutzen können benötigen wir nun eine neue Klasse die mit Unicode umgehen kann. In diesem Beispiel verwende ich die CStdioFileEx Klasse die extra für Unicode ausgelegt ist. Diese ist zu finden unter http://www.codeproject.com.
Hier seht ihr die Kleine GUI anhand ich euch dieses kleine Beispiel demonstrieren möchte.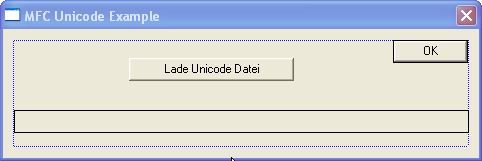
Die Funktion des Buttons "Lade Unicode Datei" enthält folgenden Quellcode
void CMFCUnicodeExampleDlg::OnLadeUnicodeDatei() { // Variable deklarieren CString szText; CStdioFileEx readfile; // Datei öffnen readfile.Open(_T("Hallo_Welt.txt"),CFile::modeRead|CFile::typeText); // Zeile einlesen readfile.ReadString(szText); // Datei schließen readfile.Close(); // Text dem CStatic Element zuordnen GetDlgItem(IDC_STATIC_UNICODE_AUSGABE)->SetWindowText(szText); }Würden wir nun die Applikation ausführen würden wir folgendes erhalten:
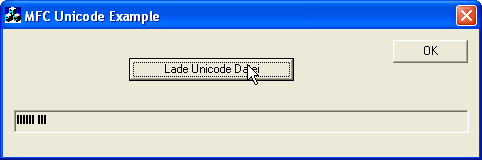
Wie Ihr seht steht unser Text leider nicht korrekt in dem CStatic Feld, sondern hierfür lauter kleine schwarze Kästchen. Der Fehler hierfür liegt an der Schriftart die das CStatic Feld nutzt. Aus diesem können Grund wir schließen das wir die Schriftart des CStatic Feldes ändern müssen.
Um dies zu bewerkstelligen deklarieren wir eine Private Membervariable in der Dialog Headerdatei mit dem Namen m_Font.
CFont m_Font; // Font Variable deklarierenSobald der Dialog geöffnet wird erstellen wir die neue Schrift und weißen diese dem CStatic Feld zu. Hier bietet sich die OnInitDialog Funktion an, da diese direkt nach dem Aufruf des Dialoges aufgerufen wird.
Folgender Ausschnitt muss dieser Funktion hinzugefügt werden.
// Font Struktur deklarieren LOGFONT logf; // Struktur mit NULL füllen ZeroMemory(&logf,sizeof(LOGFONT)); // Schriftgröße festlegen logf.lfHeight = 16; // Schriftart festlegen wcscpy(logf.lfFaceName,_T("Arial")); // Schrift erstellen m_Font.CreateFontIndirect(&logf); // Schrift dem CStatic Element zuweisen GetDlgItem(IDC_STATIC_UNICODE_AUSGABE)->SetFont(&m_Font);Würden wir nun unseren Dialog erneut ausführen und die Textdatei laden, würde der Text aus der Textdatei korrekt dargestellt werden. Dieser Text bedeutet nichts anderes wie "Hallo Welt".
Ich hoffe ich konnte euch mit diesem Artikel bezüglich Unicode ein wenig weiterhelfen.
Mit freundlichen Grüßen
euer GünniSpeziellen Dank an Alexander Müller
Ein spezieller Dank geht an den Author Alexander Müller, der mir erlaubte einige Textfragmente von seinem Artikel über Unicode in diesem Artikel zu verwenden.
Der Original Artikel von Alexander Müller ist unter http://www.a-m-i.de/tips/strings/strings.php zu erreichen.
-
Was ist Unicode?
Ich denke Du solltes einen Hinweis auf das Unicode-Consortium http://www.unicode.org geben. Die Organisation kümmert sich um die ganze Standardisierung von Unicode. Du findest dort auch alle Code-Chars und sonstige Informationen.
Ein bißchen schade finde ich, dass sich der Artikel auf MFC beschränkt. Eigentlich brauchst Du die MFC ja nur als Frontend.
Alle anderen Funktionalitäten könnte man Hilfe von Standard-C++ (wstring, wifstream, usw.) und der Win-APi programmieren.
-
rik schrieb:
Ich denke Du solltes einen Hinweis auf das Unicode-Consortium http://www.unicode.org geben. Die Organisation kümmert sich um die ganze Standardisierung von Unicode. Du findest dort auch alle Code-Chars und sonstige Informationen.
Werde ich noch hinzufügen, danke für den Hinweis
-
Eine MFC-Anwendung Unicodefähig machen
Inhaltsverzeichnis
- Einleitung
- Was ist Unicode?
- Woran erkennt man eine Unicode Datei?
- Wie kann man Unicode in einer eigenen MFC-Anwendung nutzen?
- Worauf muss nun in der MFC-Anwendung geachtet werden?
- Kleines Beispiel anhand einer Unicode Textdatei
- Speziellen Dank an Alexander Müller
Einleitung
Dieses Artikel handelt von dem so genannten Unicode Standard.
Hier wird nur auf den Unicode Standard UTF 16 eingegangen. Neben diesem existieren noch die UTF Standards 32, 8, 7 (veraltet), EBCDIC. Wer weitere Informationen zu den in diesem Artikel nicht genannten UTF Standards benötigt, kann auf der Internetseite von Wikipedia ( http://de.wikipedia.org/wiki/UTF ) mehr dazu erfahren. Ebenfalls sollte man hier die Organisation der Webseite http://www.unicode.org erwähnen, die sich um die Standardisierung des Unicodes kümmert.
Für das erzeugte Beispiel wurde Visual Studio C++ 6.0 genutzt.Was ist Unicode?
Bisher wurde stets davon ausgegangen, daß ein Zeichen in ein Byte hineinpaßt, und dies hat auch einige Jahre problemlos funktioniert. Nun lassen sich in einem Byte aber maximal 256 verschiedene Zeichen darstellen. Unser Alphabet hat zwar nur 26 Zeichen, aber die übrigen Zeichen waren ebenfalls schnell reserviert, sei es für Steuerzeichen, Leerzeichen, Symbole und so weiter. Die ersten 127 Zeichen sind als "ASCII" - Tabelle bekannt und enthalten alle Klein- und Großbuchstaben des lateinischen Alphabets. Häufige Verwendung findet auch die "ANSI" - Tabelle, die in den ersten 127 Zeichen mit ASCII übereinstimmt, und in den hinteren 128 Zeichen weitere Zeichen enthält, unter anderem auch die deutschen Umlaute.
Es hat sich jedoch gezeigt, daß ein Byte einfach zuwenig ist, um alle möglichen Zeichen aus allen Welt - Alphabeten einheitlich darzustellen. Also wurde Unicode als Standard erfunden. Unicode ist eine Zeichentabelle, die 32767 verschiedene Zeichen ermöglicht, weil jedes Zeichen 2 Byte (= 16 Bit) groß ist. Auch Symbole wie Euro, Dollar und britisches Pfund haben dort ihren eindeutigen Platz. Der Nachteil ist jedoch, daß jedes Zeichen 16 Bit Platz braucht, und daß dies natürlich Texte und Strings auf die doppelte Größe aufbläht.
Woran erkennt man eine Unicode Datei?
Woher weiß jetzt eine Textverarbeitung wie Word oder Notepad, ob in einer Textdatei, die geöffnet werden soll, Unicode oder 1-Byte-Zeichen verwendet werden ? Es hat sich durchgesetzt, daß Unicode - Textdateien stets mit den beiden Bytes "FF FE" beginnen, daran wird diese Erkennung festgemacht. Daher sollte man diesen Code auch selbst verwenden, wenn man Unicode-Dateien erzeugt.
Wie kann man Unicode in einer eigenen MFC-Anwendung nutzen?
Im ersten Schritt müssen wir dem Compiler mitteilen das wir in unserer Anwendung Unicode nutzen wollen und er dies beim kompilieren berücksichtigen soll. Dies erreichen wir durch das definieren des Makros _UNICODE!
Da wir Unicode nutzen wollen benötigen wir für die MFC-Anwendung ein anderer Einstiegspunkt (wWinMainCRTStartup). Diesen können wir ebenfalls über die Projekteinstellungen definieren.
Worauf muss in einer MFC-Anwendung geachtet werden?
Wir müssen beim Programmieren darauf achten das wir unsere Texte die wir im Quellcode Hard kodieren mit dem Makro _T("") umschließen. Dieses Makro kümmert sich um die Konvertierung der Zeichen wenn _UNICODE definiert ist.
Aus
CString szText = "Hallo Welt";wird
CString szText = _T("Hallo Welt");Die CString Klassen können wir ganz normal weiternutzen, da diese Unicodefähig ist. Bei manchen Befehlen ist es möglich das wir diese durch die Unicodefähigen Alternativen ersetzen müssen. Beispiel hierfür wäre der Befehl strcpy der durch den Befehl wcscpy ersetzen zu wäre. Für die meisten klassischen Funktionen ist eine eine wchar_t Version vorhanden.
Hier ein paar Beispiele solcher Befehle:
Funktionsname => wchar_t Versionstrcpy => wcscpy
strcat => wcscat
fopen => _wfopenManche Klassen wie die CString Klasse nutzen automatisch die richtige Funktion. Dies wird durch eine Define Anweisung in der Klasse geregelt.
Kleines Beispiel anhand einer Unicode Textdatei
Da wir zum Laden einer Unicode Datei nicht mehr die normale Klasse CStdioFile nutzen können benötigen wir nun eine neue Klasse die mit Unicode umgehen kann. In diesem Beispiel verwende ich die CStdioFileEx Klasse die extra für Unicode ausgelegt ist. Diese ist zu finden unter http://www.codeproject.com.
Hier seht ihr die Kleine GUI anhand ich euch dieses kleine Beispiel demonstrieren möchte.Die Funktion des Buttons "Lade Unicode Datei" enthält folgenden Quellcode
void CMFCUnicodeExampleDlg::OnLadeUnicodeDatei() { // Variable deklarieren CString szText; CStdioFileEx readfile; // Datei öffnen readfile.Open(_T("Hallo_Welt.txt"),CFile::modeRead|CFile::typeText); // Zeile einlesen readfile.ReadString(szText); // Datei schließen readfile.Close(); // Text dem CStatic Element zuordnen GetDlgItem(IDC_STATIC_UNICODE_AUSGABE)->SetWindowText(szText); }Würden wir nun die Applikation ausführen würden wir folgendes erhalten:
Wie Ihr seht steht unser Text leider nicht korrekt in dem CStatic Feld, sondern hierfür lauter kleine schwarze Kästchen. Der Fehler hierfür liegt an der Schriftart die das CStatic Feld nutzt. Aus diesem können Grund wir schließen das wir die Schriftart des CStatic Feldes ändern müssen.
Um dies zu bewerkstelligen deklarieren wir eine Private Membervariable in der Dialog Headerdatei mit dem Namen m_Font.
CFont m_Font; // Font Variable deklarierenSobald der Dialog geöffnet wird erstellen wir die neue Schrift und weißen diese dem CStatic Feld zu. Hier bietet sich die OnInitDialog Funktion an, da diese direkt nach dem Aufruf des Dialoges aufgerufen wird.
Folgender Ausschnitt muss dieser Funktion hinzugefügt werden.
// Font Struktur deklarieren LOGFONT logf; // Struktur mit NULL füllen ZeroMemory(&logf,sizeof(LOGFONT)); // Schriftgröße festlegen logf.lfHeight = 16; // Schriftart festlegen wcscpy(logf.lfFaceName,_T("Arial")); // Schrift erstellen m_Font.CreateFontIndirect(&logf); // Schrift dem CStatic Element zuweisen GetDlgItem(IDC_STATIC_UNICODE_AUSGABE)->SetFont(&m_Font);Würden wir nun unseren Dialog erneut ausführen und die Textdatei laden, würde der Text aus der Textdatei korrekt dargestellt werden. Dieser Text bedeutet nichts anderes wie "Hallo Welt".
Ich hoffe ich konnte euch mit diesem Artikel bezüglich Unicode ein wenig weiterhelfen.
Mit freundlichen Grüßen
euer GünniSpeziellen Dank an Alexander Müller
Ein spezieller Dank geht an den Author Alexander Müller, der mir erlaubte einige Textfragmente von seinem Artikel über Unicode in diesem Artikel zu verwenden.
Der Original Artikel von Alexander Müller ist unter http://www.a-m-i.de/tips/strings/strings.php zu erreichen.
-
Krieg ich kein Feedback?
-
Okay... Probegelesen für "Ohne Vorkenntnisse":
Die Kapitelnumerierung fehlt
Was ist CStdioFileEx?Sonst sieht es verständlich aus und ist nachvollziehbar.
")
-
estartu schrieb:
Okay... Probegelesen für "Ohne Vorkenntnisse":
Die Kapitelnumerierung fehlt
Was ist CStdioFileEx?Sonst sieht es verständlich aus und ist nachvollziehbar.
OK, werds am WE korrigieren und dann die neue Version online stellen.
-
Eine MFC-Anwendung Unicodefähig machen
Inhaltsverzeichnis
- Einleitung
- Was ist Unicode?
- Woran erkennt man eine Unicode Datei?
- Wie kann man Unicode in einer eigenen MFC-Anwendung nutzen?
- Worauf muss nun in der MFC-Anwendung geachtet werden?
- Kleines Beispiel anhand einer Unicode Textdatei
- Speziellen Dank an Alexander Müller
1. Einleitung
Dieses Artikel handelt von dem so genannten Unicode Standard.
Hier wird nur auf den Unicode Standard UTF 16 eingegangen. Neben diesem existieren noch die UTF Standards 32, 8, 7 (veraltet), EBCDIC. Wer weitere Informationen zu den in diesem Artikel nicht genannten UTF Standards benötigt, kann auf der Internetseite von Wikipedia ( http://de.wikipedia.org/wiki/UTF ) mehr dazu erfahren. Ebenfalls sollte man hier die Organisation der Webseite http://www.unicode.org erwähnen, die sich um die Standardisierung des Unicodes kümmert.
Für das erzeugte Beispiel wurde Visual Studio C++ 6.0 genutzt.2. Was ist Unicode?
Bisher wurde stets davon ausgegangen, daß ein Zeichen in ein Byte hineinpaßt, und dies hat auch einige Jahre problemlos funktioniert. Nun lassen sich in einem Byte aber maximal 256 verschiedene Zeichen darstellen. Unser Alphabet hat zwar nur 26 Zeichen, aber die übrigen Zeichen waren ebenfalls schnell reserviert, sei es für Steuerzeichen, Leerzeichen, Symbole und so weiter. Die ersten 127 Zeichen sind als "ASCII" - Tabelle bekannt und enthalten alle Klein- und Großbuchstaben des lateinischen Alphabets. Häufige Verwendung findet auch die "ANSI" - Tabelle, die in den ersten 127 Zeichen mit ASCII übereinstimmt, und in den hinteren 128 Zeichen weitere Zeichen enthält, unter anderem auch die deutschen Umlaute.
Es hat sich jedoch gezeigt, daß ein Byte einfach zuwenig ist, um alle möglichen Zeichen aus allen Welt - Alphabeten einheitlich darzustellen. Also wurde Unicode als Standard erfunden. Unicode ist eine Zeichentabelle, die 32767 verschiedene Zeichen ermöglicht, weil jedes Zeichen 2 Byte (= 16 Bit) groß ist. Auch Symbole wie Euro, Dollar und britisches Pfund haben dort ihren eindeutigen Platz. Der Nachteil ist jedoch, daß jedes Zeichen 16 Bit Platz braucht, und daß dies natürlich Texte und Strings auf die doppelte Größe aufbläht.
3. Woran erkennt man eine Unicode Datei?
Woher weiß jetzt eine Textverarbeitung wie Word oder Notepad, ob in einer Textdatei, die geöffnet werden soll, Unicode oder 1-Byte-Zeichen verwendet werden ? Es hat sich durchgesetzt, daß Unicode - Textdateien stets mit den beiden Bytes "FF FE" beginnen, daran wird diese Erkennung festgemacht. Daher sollte man diesen Code auch selbst verwenden, wenn man Unicode-Dateien erzeugt.
4. Wie kann man Unicode in einer eigenen MFC-Anwendung nutzen?
Im ersten Schritt müssen wir dem Compiler mitteilen das wir in unserer Anwendung Unicode nutzen wollen und er dies beim kompilieren berücksichtigen soll. Dies erreichen wir durch das definieren des Makros _UNICODE!
Da wir Unicode nutzen wollen benötigen wir für die MFC-Anwendung ein anderer Einstiegspunkt (wWinMainCRTStartup). Diesen können wir ebenfalls über die Projekteinstellungen definieren.
5. Worauf muss in einer MFC-Anwendung geachtet werden?
Wir müssen beim Programmieren darauf achten das wir unsere Texte die wir im Quellcode Hard kodieren mit dem Makro _T("") umschließen. Dieses Makro kümmert sich um die Konvertierung der Zeichen wenn _UNICODE definiert ist.
Aus
CString szText = "Hallo Welt";wird
CString szText = _T("Hallo Welt");Die CString Klassen können wir ganz normal weiternutzen, da diese Unicodefähig ist. Bei manchen Befehlen ist es möglich das wir diese durch die Unicodefähigen Alternativen ersetzen müssen. Beispiel hierfür wäre der Befehl strcpy der durch den Befehl wcscpy ersetzen zu wäre. Für die meisten klassischen Funktionen ist eine eine wchar_t Version vorhanden.
Hier ein paar Beispiele solcher Befehle:
Funktionsname => wchar_t Versionstrcpy => wcscpy
strcat => wcscat
fopen => _wfopenManche Klassen wie die CString Klasse nutzen automatisch die richtige Funktion. Dies wird durch eine Define Anweisung in der Klasse geregelt.
6. Kleines Beispiel anhand einer Unicode Textdatei
Da wir zum Laden einer Unicode Datei nicht mehr die normale Klasse CStdioFile nutzen können benötigen wir nun eine neue Klasse die mit Unicode umgehen kann. In diesem Beispiel verwende ich die CStdioFileEx Klasse von der Webseite http://www.codeproject.com/file/stdiofileex.asp. Mit Hilfe dieser Klasse lassen sich Unicode Dateien kompfortabel einlesen und schreiben. Die oben genannte Klasse wurde speziell für die Arbeit mit Unicode Dateien erstellt.
Hier seht ihr die Kleine GUI anhand ich euch dieses kleine Beispiel demonstrieren möchte.Die Funktion des Buttons "Lade Unicode Datei" enthält folgenden Quellcode
void CMFCUnicodeExampleDlg::OnLadeUnicodeDatei() { // Variable deklarieren CString szText; CStdioFileEx readfile; // Datei öffnen readfile.Open(_T("Hallo_Welt.txt"),CFile::modeRead|CFile::typeText); // Zeile einlesen readfile.ReadString(szText); // Datei schließen readfile.Close(); // Text dem CStatic Element zuordnen GetDlgItem(IDC_STATIC_UNICODE_AUSGABE)->SetWindowText(szText); }Würden wir nun die Applikation ausführen würden wir folgendes erhalten:
Wie Ihr seht steht unser Text leider nicht korrekt in dem CStatic Feld, sondern hierfür lauter kleine schwarze Kästchen. Der Fehler hierfür liegt an der Schriftart die das CStatic Feld nutzt. Aus diesem können Grund wir schließen das wir die Schriftart des CStatic Feldes ändern müssen.
Um dies zu bewerkstelligen deklarieren wir eine Private Membervariable in der Dialog Headerdatei mit dem Namen m_Font.
CFont m_Font; // Font Variable deklarierenSobald der Dialog geöffnet wird erstellen wir die neue Schrift und weißen diese dem CStatic Feld zu. Hier bietet sich die OnInitDialog Funktion an, da diese direkt nach dem Aufruf des Dialoges aufgerufen wird.
Folgender Ausschnitt muss dieser Funktion hinzugefügt werden.
// Font Struktur deklarieren LOGFONT logf; // Struktur mit NULL füllen ZeroMemory(&logf,sizeof(LOGFONT)); // Schriftgröße festlegen logf.lfHeight = 16; // Schriftart festlegen wcscpy(logf.lfFaceName,_T("Arial")); // Schrift erstellen m_Font.CreateFontIndirect(&logf); // Schrift dem CStatic Element zuweisen GetDlgItem(IDC_STATIC_UNICODE_AUSGABE)->SetFont(&m_Font);Würden wir nun unseren Dialog erneut ausführen und die Textdatei laden, würde der Text aus der Textdatei korrekt dargestellt werden. Dieser Text bedeutet nichts anderes wie "Hallo Welt".
Ich hoffe ich konnte euch mit diesem Artikel bezüglich Unicode ein wenig weiterhelfen.
Mit freundlichen Grüßen
euer Günni7. Speziellen Dank an Alexander Müller
Ein spezieller Dank geht an den Author Alexander Müller, der mir erlaubte einige Textfragmente von seinem Artikel über Unicode in diesem Artikel zu verwenden.
Der Original Artikel von Alexander Müller ist unter http://www.a-m-i.de/tips/strings/strings.php zu erreichen.
-
Wenn keine weitere Kritik kommen sollte, würde ich den Status des Artikels ändern.
-
Eine MFC-Anwendung unicodefähig machen
Inhaltsverzeichnis
- Einleitung
- Was ist Unicode?
- Woran erkennt man eine Unicode-Datei?
- Wie kann man Unicode in einer eigenen MFC-Anwendung nutzen?
- Worauf muss nun in der MFC-Anwendung geachtet werden?
- Kleines Beispiel anhand einer Unicode-Textdatei
- Speziellen Dank an Alexander Müller
1. Einleitung
Dieser Artikel handelt von dem so genannten Unicode-Standard.
Hier wird nur auf den Unicode-Standard UTF 16 eingegangen. Neben diesem existieren noch die UTF-Standards 32, 8, 7 (veraltet), EBCDIC. Wer weitere Informationen zu den in diesem Artikel nicht genannten UTF-Standards benötigt, kann auf der Internetseite von Wikipedia ( http://de.wikipedia.org/wiki/UTF ) mehr darüber erfahren. Ebenfalls sollte man hier die Organisation der Webseite http://www.unicode.org erwähnen, die sich um die Standardisierung des Unicodes kümmert.
Für das erzeugte Beispiel wurde Visual Studio C++ 6.0 genutzt.2. Was ist Unicode?
Bisher wurde stets davon ausgegangen, dass ein Zeichen in ein Byte hineinpasst, und dies hat auch einige Jahre problemlos funktioniert. Nun lassen sich in einem Byte aber maximal 256 verschiedene Zeichen darstellen. Unser Alphabet hat zwar nur 26 Zeichen, aber die übrigen Zeichen waren ebenfalls schnell reserviert, sei es für Steuerzeichen, Leerzeichen, Symbole und so weiter. Die ersten 127 Zeichen sind als "ASCII"-Tabelle bekannt und enthalten alle Klein- und Großbuchstaben des lateinischen Alphabets. Häufige Verwendung findet auch die "ANSI"-Tabelle, die in den ersten 127 Zeichen mit ASCII übereinstimmt, und in den hinteren 128 Zeichen weitere Zeichen enthält, unter anderem auch die deutschen Umlaute.
Es hat sich jedoch gezeigt, dass ein Byte einfach zu wenig ist, um alle möglichen Zeichen der Alphabete aus aller Welt einheitlich darzustellen. Also wurde Unicode als Standard erfunden. Unicode ist eine Zeichentabelle, die 32767 verschiedene Zeichen ermöglicht, weil jedes Zeichen 2 Byte (= 16 Bit) groß ist. Auch Symbole wie Euro, Dollar und britisches Pfund haben dort ihren eindeutigen Platz. Der Nachteil ist jedoch, dass jedes Zeichen 16 Bit Platz braucht und dass dies natürlich Texte und Strings auf die doppelte Größe aufbläht.
3. Woran erkennt man eine Unicode-Datei?
Woher weiß jetzt eine Textverarbeitung wie Word oder Notepad, ob in einer Textdatei, die geöffnet werden soll, Unicode oder 1-Byte-Zeichen verwendet werden? Es hat sich durchgesetzt, dass Unicode-Textdateien stets mit den beiden Bytes "FF FE" beginnen. Daran wird diese Erkennung festgemacht. Daher sollte man diesen Code auch selbst verwenden, wenn man Unicode-Dateien erzeugt.
4. Wie kann man Unicode in einer eigenen MFC-Anwendung nutzen?
Im ersten Schritt müssen wir dem Compiler mitteilen, dass wir in unserer Anwendung Unicode nutzen wollen und dass er dies beim Kompilieren berücksichtigen soll. Dies erreichen wir durch das Definieren des Makros _UNICODE!
Da wir Unicode nutzen wollen, benötigen wir für die MFC-Anwendung einen anderen Einstiegspunkt (wWinMainCRTStartup). Diesen können wir ebenfalls über die Projekteinstellungen definieren.
5. Worauf muss in einer MFC-Anwendung geachtet werden?
Wir müssen beim Programmieren darauf achten, dass wir unsere Texte, die wir im Quellcode Hard kodieren, mit dem Makro _T("") umschließen. Dieses Makro kümmert sich um die Konvertierung der Zeichen, wenn _UNICODE definiert ist.
Aus
CString szText = "Hallo Welt";wird
CString szText = _T("Hallo Welt");Die CString-Klassen können wir ganz normal weiternutzen, da diese unicodefähig sind. Bei manchen Befehlen ist es möglich, dass wir diese durch die unicodefähigen Alternativen ersetzen müssen. Beispiel hierfür wäre der Befehl strcpy, der durch den Befehl wcscpy zu ersetzen wäre. Für die meisten klassischen Funktionen ist eine eine wchar_t Version vorhanden.
Hier ein paar Beispiele solcher Befehle:
Funktionsname => wchar_t Versionstrcpy => wcscpy
strcat => wcscat
fopen => _wfopenManche Klassen wie die CString-Klasse nutzen automatisch die richtige Funktion. Dies wird durch eine Define-Anweisung in der Klasse geregelt.
6. Kleines Beispiel anhand einer Unicode-Textdatei
Da wir zum Laden einer Unicode Datei nicht mehr die normale Klasse CStdioFile nutzen können, benötigen wir nun eine neue Klasse die mit Unicode umgehen kann. In diesem Beispiel verwende ich die CStdioFileEx-Klasse von der Webseite http://www.codeproject.com/file/stdiofileex.asp. Mit Hilfe dieser Klasse lassen sich Unicode-Dateien komfortabel einlesen und schreiben. Die oben genannte Klasse wurde speziell für die Arbeit mit Unicode-Dateien erstellt.
Hier seht ihr die kleine GUI, anhand derer ich euch dieses kleine Beispiel demonstrieren möchte.Die Funktion des Buttons "Lade Unicode-Datei" enthält folgenden Quellcode:
void CMFCUnicodeExampleDlg::OnLadeUnicodeDatei() { // Variable deklarieren CString szText; CStdioFileEx readfile; // Datei öffnen readfile.Open(_T("Hallo_Welt.txt"),CFile::modeRead|CFile::typeText); // Zeile einlesen readfile.ReadString(szText); // Datei schließen readfile.Close(); // Text dem CStatic-Element zuordnen GetDlgItem(IDC_STATIC_UNICODE_AUSGABE)->SetWindowText(szText); }Würden wir nun die Applikation ausführen, würden wir Folgendes erhalten:
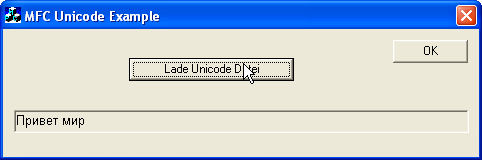
Wie ihr seht, steht unser Text leider nicht korrekt in dem CStatic-Feld, sondern stattdessen lauter kleine schwarze Kästchen. Der Fehler hierfür liegt an der Schriftart, die das CStatic-Feld nutzt. Daraus schließen wir, dass wir die Schriftart des CStatic-Feldes ändern müssen.
Um dies zu bewerkstelligen, deklarieren wir eine private Membervariable in der Dialog-Headerdatei mit dem Namen m_Font.
CFont m_Font; // Font-Variable deklarierenSobald der Dialog geöffnet wird, erstellen wir die neue Schrift und weisen diese dem CStatic-Feld zu. Hier bietet sich die OnInitDialog-Funktion an, da diese direkt nach dem Aufruf des Dialogs aufgerufen wird.
Folgender Ausschnitt muss dieser Funktion hinzugefügt werden.
// Font-Struktur deklarieren LOGFONT logf; // Struktur mit NULL füllen ZeroMemory(&logf,sizeof(LOGFONT)); // Schriftgröße festlegen logf.lfHeight = 16; // Schriftart festlegen wcscpy(logf.lfFaceName,_T("Arial")); // Schrift erstellen m_Font.CreateFontIndirect(&logf); // Schrift dem CStatic-Element zuweisen GetDlgItem(IDC_STATIC_UNICODE_AUSGABE)->SetFont(&m_Font);Würden wir nun unseren Dialog erneut ausführen und die Textdatei laden, würde der Text aus der Textdatei korrekt dargestellt. Dieser Text bedeutet nichts anderes als "Hallo Welt".
Ich hoffe, ich konnte euch mit diesem Artikel bezüglich Unicode ein wenig weiterhelfen.
Mit freundlichen Grüßen
euer Günni7. Speziellen Dank an Alexander Müller
Ein spezieller Dank geht an den Autor Alexander Müller, der mir erlaubte, einige Textfragmente von seinem Artikel über Unicode in diesem Artikel zu verwenden.
Der Originalartikel von Alexander Müller ist unter http://www.a-m-i.de/tips/strings/strings.php zu erreichen.
-
Ich glaube, ich hatte deine Schwierigkeit mit dass und das schon mal angesprochen.
Ansonsten eine Kleinigkeit gen Ende des Artikels:
"Um dies zu bewerkstelligen, deklarieren wir eine private Membervariable in der Dialog Headerdatei mit dem Namen m_Font."
Meinste jetzt "in der Dialog-Headerdatei" oder "im Dialog der Headerdatei"???Klär mich auf, ich sag dir, obs richtig ist, und dann kannste das im Artikel berichtigen.
Mr. B
-
Nach den Zahlen bitte keine Punkte.

-
das möge bitte der artikelersteller verbessern. nach der neuen neuen rechtschreibung bin ich nicht im stande, auch noch auf artikelstil zu achten.
")
Mr. B
-
Eine MFC-Anwendung unicodefähig machen
Inhaltsverzeichnis
- Einleitung
- Was ist Unicode?
- Woran erkennt man eine Unicode-Datei?
- Wie kann man Unicode in einer eigenen MFC-Anwendung nutzen?
- Worauf muss nun in der MFC-Anwendung geachtet werden?
- Kleines Beispiel anhand einer Unicode-Textdatei
- Speziellen Dank an Alexander Müller
1 Einleitung
Dieser Artikel handelt von dem so genannten Unicode-Standard.
Hier wird nur auf den Unicode-Standard UTF 16 eingegangen. Neben diesem existieren noch die UTF-Standards 32, 8, 7 (veraltet), EBCDIC. Wer weitere Informationen zu den in diesem Artikel nicht genannten UTF-Standards benötigt, kann auf der Internetseite von Wikipedia ( http://de.wikipedia.org/wiki/UTF ) mehr darüber erfahren. Ebenfalls sollte man hier die Organisation der Webseite http://www.unicode.org erwähnen, die sich um die Standardisierung des Unicodes kümmert.
Für das erzeugte Beispiel wurde Visual Studio C++ 6.0 genutzt.2 Was ist Unicode?
Bisher wurde stets davon ausgegangen, dass ein Zeichen in ein Byte hineinpasst, und dies hat auch einige Jahre problemlos funktioniert. Nun lassen sich in einem Byte aber maximal 256 verschiedene Zeichen darstellen. Unser Alphabet hat zwar nur 26 Zeichen, aber die übrigen Zeichen waren ebenfalls schnell reserviert, sei es für Steuerzeichen, Leerzeichen, Symbole und so weiter. Die ersten 127 Zeichen sind als "ASCII"-Tabelle bekannt und enthalten alle Klein- und Großbuchstaben des lateinischen Alphabets. Häufige Verwendung findet auch die "ANSI"-Tabelle, die in den ersten 127 Zeichen mit ASCII übereinstimmt, und in den hinteren 128 Zeichen weitere Zeichen enthält, unter anderem auch die deutschen Umlaute.
Es hat sich jedoch gezeigt, dass ein Byte einfach zu wenig ist, um alle möglichen Zeichen der Alphabete aus aller Welt einheitlich darzustellen. Also wurde Unicode als Standard erfunden. Unicode ist eine Zeichentabelle, die 32767 verschiedene Zeichen ermöglicht, weil jedes Zeichen 2 Byte (= 16 Bit) groß ist. Auch Symbole wie Euro, Dollar und britisches Pfund haben dort ihren eindeutigen Platz. Der Nachteil ist jedoch, dass jedes Zeichen 16 Bit Platz braucht und dass dies natürlich Texte und Strings auf die doppelte Größe aufbläht.
3 Woran erkennt man eine Unicode-Datei?
Woher weiß jetzt eine Textverarbeitung wie Word oder Notepad, ob in einer Textdatei, die geöffnet werden soll, Unicode oder 1-Byte-Zeichen verwendet werden? Es hat sich durchgesetzt, dass Unicode-Textdateien stets mit den beiden Bytes "FF FE" beginnen. Daran wird diese Erkennung festgemacht. Daher sollte man diesen Code auch selbst verwenden, wenn man Unicode-Dateien erzeugt.
4 Wie kann man Unicode in einer eigenen MFC-Anwendung nutzen?
Im ersten Schritt müssen wir dem Compiler mitteilen, dass wir in unserer Anwendung Unicode nutzen wollen und dass er dies beim Kompilieren berücksichtigen soll. Dies erreichen wir durch das Definieren des Makros _UNICODE!
Da wir Unicode nutzen wollen, benötigen wir für die MFC-Anwendung einen anderen Einstiegspunkt (wWinMainCRTStartup). Diesen können wir ebenfalls über die Projekteinstellungen definieren.
5 Worauf muss in einer MFC-Anwendung geachtet werden?
Wir müssen beim Programmieren darauf achten, dass wir unsere Texte, die wir im Quellcode Hard kodieren, mit dem Makro _T("") umschließen. Dieses Makro kümmert sich um die Konvertierung der Zeichen, wenn _UNICODE definiert ist.
Aus
CString szText = "Hallo Welt";wird
CString szText = _T("Hallo Welt");Die CString-Klassen können wir ganz normal weiternutzen, da diese unicodefähig sind. Bei manchen Befehlen ist es möglich, dass wir diese durch die unicodefähigen Alternativen ersetzen müssen. Beispiel hierfür wäre der Befehl strcpy, der durch den Befehl wcscpy zu ersetzen wäre. Für die meisten klassischen Funktionen ist eine eine wchar_t Version vorhanden.
Hier ein paar Beispiele solcher Befehle:
Funktionsname => wchar_t Versionstrcpy => wcscpy
strcat => wcscat
fopen => _wfopenManche Klassen wie die CString-Klasse nutzen automatisch die richtige Funktion. Dies wird durch eine Define-Anweisung in der Klasse geregelt.
6 Kleines Beispiel anhand einer Unicode-Textdatei
Da wir zum Laden einer Unicode Datei nicht mehr die normale Klasse CStdioFile nutzen können, benötigen wir nun eine neue Klasse die mit Unicode umgehen kann. In diesem Beispiel verwende ich die CStdioFileEx-Klasse von der Webseite http://www.codeproject.com/file/stdiofileex.asp. Mit Hilfe dieser Klasse lassen sich Unicode-Dateien komfortabel einlesen und schreiben. Die oben genannte Klasse wurde speziell für die Arbeit mit Unicode-Dateien erstellt.
Hier seht ihr die kleine GUI, anhand derer ich euch dieses kleine Beispiel demonstrieren möchte.Die Funktion des Buttons "Lade Unicode-Datei" enthält folgenden Quellcode:
void CMFCUnicodeExampleDlg::OnLadeUnicodeDatei() { // Variable deklarieren CString szText; CStdioFileEx readfile; // Datei öffnen readfile.Open(_T("Hallo_Welt.txt"),CFile::modeRead|CFile::typeText); // Zeile einlesen readfile.ReadString(szText); // Datei schließen readfile.Close(); // Text dem CStatic-Element zuordnen GetDlgItem(IDC_STATIC_UNICODE_AUSGABE)->SetWindowText(szText); }Würden wir nun die Applikation ausführen, würden wir Folgendes erhalten:
Wie ihr seht, steht unser Text leider nicht korrekt in dem CStatic-Feld, sondern stattdessen lauter kleine schwarze Kästchen. Der Fehler hierfür liegt an der Schriftart, die das CStatic-Feld nutzt. Daraus schließen wir, dass wir die Schriftart des CStatic-Feldes ändern müssen.
Um dies zu bewerkstelligen, deklarieren wir eine private Membervariable in der Headerdatei (.h Datei) unseres Dialoges mit dem Namen m_Font.
CFont m_Font; // Font-Variable deklarierenSobald der Dialog geöffnet wird, erstellen wir die neue Schrift und weisen diese dem CStatic-Feld zu. Hier bietet sich die OnInitDialog-Funktion an, da diese direkt nach dem Aufruf des Dialogs aufgerufen wird.
Folgender Ausschnitt muss dieser Funktion hinzugefügt werden.
// Font-Struktur deklarieren LOGFONT logf; // Struktur mit NULL füllen ZeroMemory(&logf,sizeof(LOGFONT)); // Schriftgröße festlegen logf.lfHeight = 16; // Schriftart festlegen wcscpy(logf.lfFaceName,_T("Arial")); // Schrift erstellen m_Font.CreateFontIndirect(&logf); // Schrift dem CStatic-Element zuweisen GetDlgItem(IDC_STATIC_UNICODE_AUSGABE)->SetFont(&m_Font);Würden wir nun unseren Dialog erneut ausführen und die Textdatei laden, würde der Text aus der Textdatei korrekt dargestellt. Dieser Text bedeutet nichts anderes als "Hallo Welt".
Ich hoffe, ich konnte euch mit diesem Artikel bezüglich Unicode ein wenig weiterhelfen.
Mit freundlichen Grüßen
euer Günni7 Speziellen Dank an Alexander Müller
Ein spezieller Dank geht an den Autor Alexander Müller, der mir erlaubte, einige Textfragmente von seinem Artikel über Unicode in diesem Artikel zu verwenden.
Der Originalartikel von Alexander Müller ist unter http://www.a-m-i.de/tips/strings/strings.php zu erreichen.
-
Fertig?

-
estartu schrieb:
Fertig?
Aus meiner Sicht heraus ja? Wo kann man die Beispieldatei zum download ablegen?
-
Leg die Datei zu den Bildern, da haben wir nix extra.
-
In Ordnung. Dann setzte ich den Artikel auf Fertig