Sockets und das HTTP-Protokoll
-
1 Vorwort
1.1 Einleitung
Willkommen zu meinem ersten Tutorial, in dem ich erklären möchte, wie man Sockets unter Linux und Windows benutzt. Am Ende werden wir ein Programm geschaffen haben, welches, auf Eingabe einer URL, über das HTTP-Protokoll die entsprechende Datei herunterlädt und auf der Festplatte speichert. Sie merken, es geht in diesem Tutorial nur um das Verbinden, also fangen Sie am Besten nicht an mit lesen, wenn Sie eine Einführung in die Programmierung von Netzwerkspielen erwarten.
1.2 Vorausetzungen
Unter Windows benutze ich als IDE Code::Blocks (http://www.codeblocks.org) und den GNU-GCC-Compiler in der Version 3.4.4.
Unter Linux verwende ich gedit (http://www.gnome.org/projects/gedit/) und den GNU-GCC-Compilier in der Version 4.1.2.Sie sollten C++-Kenntnisse in Exceptions, Stringstreams und Filestreams haben, außerdem ist Erfahrung mit Zeigern empfehlenswert.
1.3 Linken der benötigten Libs
Wenn Sie unter Linux sind, brauchen Sie gar nichts tun. Falls Sie aber unter Windows arbeiten, müssen Sie noch gegen die benötigte Winsock-Library linken. Der Name der Lib lautet libws2_32.a. Falls diese bei Ihnen nicht vorhanden ist, suchen Sie einfach eine beliebige heraus, die nach Sockets klingt und probieren Sie sie einfach aus. Sollte das nicht helfen, fragen Sie am besten im Compiler- oder WinAPI-Forum. Hier 2 Screenshots für das Hinzufügen mit Code::Blocks:
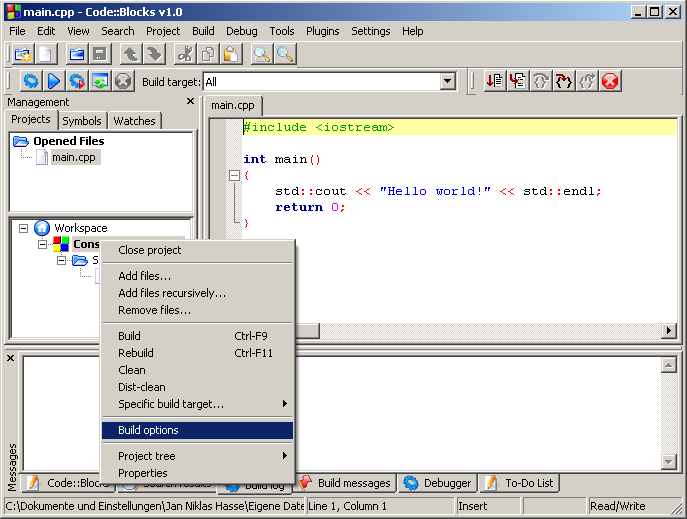
Abb. 1.3.1 Auswählen der Build-Options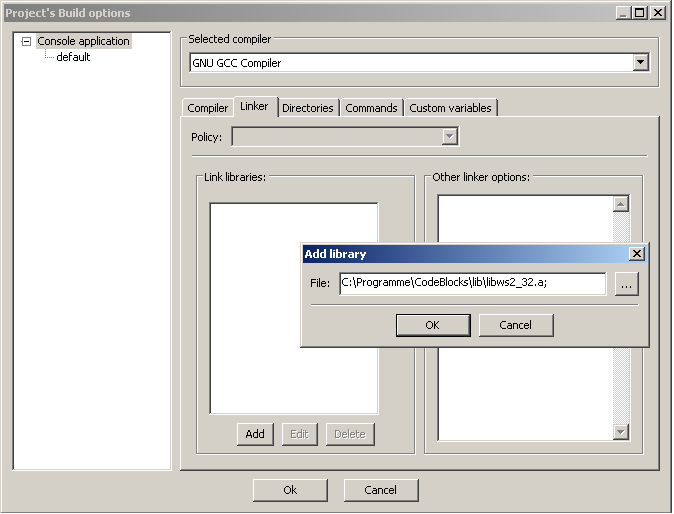
Abb. 1.3.2 Eingeben der Winsock-Lib.Sollten Sie Nutzer der MS VisualC++ IDE sein, müssen Sie die WS2_32.lib Bibliothek dem Linker bekannt geben. Dazu gehen Sie unter Projekt->Eigenschaften->Linker und tragen, wie im Screenshot zu sehen, die Library unter "Zusätzliche Abhängigkeiten" ein:
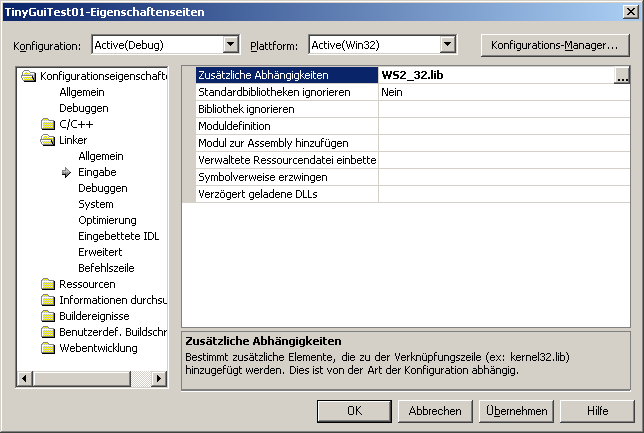
Abb. 1.3.3 Zusätzliche Abhängigkeiten2 Das erste Socket-Programm
Unser erstes Programm soll einfach nur über den Port 80, welcher der standardmäßige Port für das HTTP-Protokoll ist, eine Verbindung aufbauen.
Zuerst müssen Sie die nötigen Headerdateien inkludieren:#include <iostream> #ifdef linux #include <sys/socket.h> // socket(), connect() #include <arpa/inet.h> // sockaddr_in #else #include <winsock2.h> #endif int main() { using namespace std;Die Konstante linux wird von meinem Compiler automatisch definiert, wenn ich unter Linux bin. Nähere Infos: http://predef.sourceforge.net/preos.html
Sie können auch einfach nur den für Ihr Betriebssystem benötigten Code nehmen und den Rest verwerfen.
Die iostream-Headerdatei ist klar; für Windows müssen wir nur die winsock2.h inkludieren, dort sind alle Funktionen für die zweite Winsock-Version definiert. Bei Linux sind die einzelnen Sachen in verschiedene Dateien aufgeteilt.Folgender Code ist nur für Windows wichtig:
#ifndef linux WSADATA w; if(int result = WSAStartup(MAKEWORD(2,2), &w) != 0) { cout << "Winsock 2 konnte nicht gestartet werden! Error #" << result << endl; return 1; } #endifMit der Funktion WSAStartup wird Windows mitgeteilt, dass man gerne Zugriff auf die Winsock-Library haben will. Die Parameter sind eigentlich unwichtig, falls diese Sie dennoch interessieren, können Sie auf der MSDN-Seite nachschauen, was sie bedeuten. Das einzige was wir uns merken müssen, ist dass jedes Winsock-Programm mit dieser Funktion starten sollte, bevor es irgendwelche anderen Socket-Funktionen aufruft.
Nun geht es weiter in der main-Funktion:
int Socket = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP); if(Socket == -1) { cout << "Socket konnte nicht erstellt werden!" << endl; return 1; }Die socket()-Funktion erstellt ein neues Socket, einen „Netzwerkanschluss“, und gibt dessen ID zurück. Mit dieser ID können wir später auf dem Socket Daten senden bzw. empfangen. Ein negativer Wert stellt hierbei einen Fehler beim Erstellen dar. Weitere Infos zu der socket-Funktion gibt es hier.
Hinweis: Als Windows-User werden Sie wahrscheinlich auf den Datentyp SOCKET treffen. Dieser ist ein typedef auf unsigned int. Trotzdem können Sie ein Socket einfach als int behandeln, da es eine implizite Umwandlung zwischen diesen Typen gibt.
Nachdem wir ein Socket erstellt haben, müssen wir eine Verbindung aufbauen.
Jede Verbindung hat verschiedene Parameter, die in einer Struktur namens sockaddr gespeichert sind. Sie müssen sich das so vorstellen, dass die sockaddr eine abstrakte Basisklasse ist (die nie benutzt wird) und Strukturen wie sockaddr_in sind die abgeleiteten Klassen.
(Dass man nicht gleich ein Klassendesign gewählt hat, liegt daran, dass Sockets auch unter C funktionieren sollen)
Wir benötigen nur die sockaddr_in, sie ist für die normalen, vierstelligen IP-Adressen zuständig (z.B. 192.168.114.100). Falls Sie sich mit dem neuen IPv6 beschäftigen wollen, benötigen Sie dann eine andere sockaddr-Struktur. Eine gute Übersicht gibt's hier.
Der erste Parameter dieser Strukturen ist immer der Typ der sockaddr-Struktur:sockaddr_in service; // Normale IPv4 Struktur service.sin_family = AF_INET; // AF_INET für IPv4, für IPv6 wäre es AF_INET6Als nächstes müssen wir einen Port festlegen, auf dem wir connecten wollen, dies wäre beim HTTP-Protokoll der Port 80. Hierbei ist zu beachten, dass die Struktur den Port in umgekehrter Bytereihenfolge speichert. Also zuerst das eigentlich hintere Byte von short und dann das vordere. Klingt komisch, ist aber eigentlich gar nicht so schwer, denn um eine normale Zahl in die umgekehrte Reihenfolge zu bringen, gibt es schon die Funktion htons(). Für genauere Infos suchen Sie im Internet nach big-endian.
service.sin_port = htons(80); // Das HTTP-Protokoll benutzt Port 80Falls Sie noch Probleme haben, das mit der Bytereihenfolge zu verstehen, gibt es hier ein kleines Beispiel für eine mögliche Implementierung dieser Funktion:
unsigned short my_htons(unsigned short h) { char* p = reinterpret_cast<char*>(&h); char n[2]; n[0] = p[1]; n[1] = p[0]; return *reinterpret_cast<unsigned short*>(n); }Falls Sie später htons durch my_htons ersetzen, sollte es genauso funktionieren.
Jetzt kommen wir zum Interessanten: Der IP. Bei unserem ersten Programm soll der User erstmal nur eine IP eingeben, zu der dann verbunden wird.
string ip; cout << "IP: "; cin >> ip;Nun wird es wieder etwas schwieriger. Wie Sie wissen, wird die IP in der Form 123.44.32.99 dargestellt. Die einzelnen vier Werte gehen von 0 bis 255, und da muss jedem Programmierer sofort auffallen, dass dies ein unsigned char ist. Also haben wir 4 unsigned chars die durch einen Punkt getrennt sind. Dies ist aber nur eine für Menschen leserlich gemachte Form. In Wirklichkeit speichert der Computer natürlich keinen String sondern die 4 Bytes direkt. Also haben wir ein 4 Byte großes Array aus unsigned char. Klingt logisch; macht Sie das nicht misstrauisch? Richtig! Natürlich speichert man kein Array, sondern einen unsigned long. Wäre vielleicht ja noch ganz logisch, wenn man diesen anstelle einer Struktur benutzt, aber nein, den packen wir den nochmal in eine Struktur rein.
struct in_addr { unsigned long s_addr; // long ist 4 bytes also 4 chars groß };Dass dies sinnlos ist, haben sich die Entwickler bei Microsoft wohl auch gedacht. Also haben sie die in_addr bei Winsock neu entworfen. In deren Struktur gibt es vier unsigned chars, zwei unsigned shorts und einen unsigned long. Damit das ganze kompatibel ist, hat man diese Variablen in eine union gepackt. Somit lassen sich immernoch Casts von unsigned long* zu einem in_addr* durchführen, dazu aber später mehr. Wichtig ist: Vergessen Sie die Microsoft-Version der in_addr und stellen Sie sich einfach vor, die in_addr-Struktur enthält nur einen unsigned long, der die IP-Adresse in binärer Form speichert.
Da wir ja wollen, dass der User nicht die IP-Adresse binär eingibt, sondern in der gewohnten Form, müssen wir sie umwandeln. Zum Glück gibt es dafür auch schon eine Funktion namens inet_addr. Diese gibt einen unsigned long zurück, den wir dann einfach an den s_addr-Member der in_addr-Struktur übergeben. Dieser heißt in der sockaddr_in-Struktur sin_addr (Siehe Übersicht der sockaddr_in-Struktur).
service.sin_addr.s_addr = inet_addr(ip.c_str());Nun haben wir alle Informationen für eine Verbindung an die vom User eingegebene IP gespeichert. Es ist an der Zeit nun wirklich zu verbinden. Dazu gibt es die Funktion connect. Diese erwartet als ersten Parameter ein Socket, als zweiten einen Zeiger auf unsere sockaddr-Struktur, den wir natürlich casten müssen, da wir ja in Wirklichkeit eine sockaddr_in Struktur haben. Und als letztes folgt die Länge unserer sockaddr-Struktur. Die Länge muss übergeben werden, weil... äh.. ist eigentlich eine gute Frage, denn theoretisch, kann die connect-Funktion ja durch die sin_family herausfinden wie lang die bestimmte sockaddr-Struktur ist. Aber hier hat man sich anscheinend dazu entschieden, die Länge zur Sicherheit auch noch zu übergeben, vielleicht weil sie nicht plattformunabhängig ist.
int result = connect(Socket, reinterpret_cast<sockaddr*>(&service), sizeof(service));Der Rückgabewert von connect ist bei einem Fehler -1. Dies überprüfen wir und geben bekannt, falls die Verbindung fehlgeschlagen ist:
if(result == -1) { cout << "Verbindung fehlgeschlagen!" << endl; return 1; } cout << "Verbindung erfolgreich!" << endl;An dieser Stelle haben wir jetzt eine Verbindung mit dem Server aufgebaut und könnten theoretisch Daten austauschen, das verschieben wir aber mal lieber auf das nächste Kapitel und beenden jetzt schon die Verbindung:
#ifdef linux close(Socket); #else closesocket(Socket); #endif }Diese Funktion schließt das Socket, dessen Identifizierungsnummer hier übergeben wird. Unter Linux heißt sie close() und unter Windows closesocket(). Falls wir hier nach nochmal connect() oder eine andere Funktion aufrufen, die ein Socket erwartet, werden wir eine Fehlermeldung erhalten, denn diese ID zeigt nicht auf ein gültiges Socket. Wir beachten, dass die closesocket-Funktion threadsicher ist und alle blockenden Socket-Funktionen, die dieses Socket benutzen, stoppt. Auch wird ein bestimmter Status gesendet, sodass das Gegenüber weiß, dass die Verbindung geschlossen wurde. Also schrecken Sie nicht davor zurück, close zu benutzen.
Unser Programm sollte nun so aussehen. Nun können wir es kompilieren und es sollte keine Fehlermeldung erscheinen. Testen Sie eine IP, hinter der Sie einen Webserver wissen. Falls Ihnen keine einfällt, können Sie z.B. mit dem Konsolen-Befehl
nslookup www.google.dedie IP-Adresse von Google erfahren. (Die Konsole starten Sie unter Windows mit [Windowstaste]+[R] und dann „cmd“ ausführen.)
Die Verbindung sollte erfolgreich zustande kommen. Probieren Sie auch einfach irgendetwas beliebiges aus, denn nun sollte es eine Fehlermeldung geben. Eine Konsolenausgabe könnte z.B. so aussehen (Linux):jhasse@jhasse-desktop:~/C++/http$ g++ 01.cpp jhasse@jhasse-desktop:~/C++/http$ nslookup www.google.de Server: 217.237.149.161 Address: 217.237.149.161#53 Non-authoritative answer: www.google.de canonical name = www.google.com. www.google.com canonical name = www.l.google.com. Name: www.l.google.com Address: 209.85.129.104 Name: www.l.google.com Address: 209.85.129.147 Name: www.l.google.com Address: 209.85.129.99 jhasse@jhasse-desktop:~/C++/http$ ./a.out IP: 209.85.129.104 Verbindung erfolgreich! jhasse@jhasse-desktop:~/C++/http$ ./a.out IP: 209.85.129.147 Verbindung erfolgreich! jhasse@jhasse-desktop:~/C++/http$ ./a.out IP: 209.85.129.99 Verbindung erfolgreich! jhasse@jhasse-desktop:~/C++/http$ ./a.out IP: 123.123.123.123 Verbindung fehlgeschlagen! jhasse@jhasse-desktop:~/C++/http$Bis hierhin sollten Sie alles verstanden haben. Falls es dennoch Probleme gibt, schauen Sie noch mal in die Referenzen und anderen Tutorials (siehe Links am Ende).
3 Unser eigenes nslookup
Jetzt ist es natürlich sehr nervig, dass man immer eine IP eingeben muss. Es wäre doch viel praktischer, wenn man wie beim Browser einfach einen Namen eingibt und das Programm diesen automatisch auflöst. Also fangen wir an: Programmieren wir uns unser eigenes nslookup.
Die Funktion, die uns interessiert heißt gethostbyname und gibt einen Zeiger auf eine hostent-Struktur zurück. Diese wollen wir uns mal genauer anschauen:
struct hostent { char* h_name; /* Offizieller Name des Host */ char** h_aliases; /* Weitere Namen für diesen Host */ int h_addrtype; /* Adresstyp, meistens AF_INET */ int h_length; /* Länge einer IP-Adresse in Bytes, meistens 4 */ char** h_addr_list; /* Die IP-Adressen */ };Der erste Parameter ist ein C-Array, der den Namen des Host speichert. Dieser ist für uns später unwichtig genauso wie die weiteren Namen des Hosts. Da diese mehrere sein können, haben wir eine Liste aus Zeiger, bzw aus C-Arrays. Das wird jetzt sehr kompliziert, deswegen ein kurzes Beispiel:
char* = C-String char** = C-String*Wir haben also einen Zeiger auf einen C-String. Aber wozu einen Zeiger? Klar, weil es sich um ein dynamisches Array handelt:
Dynamisches Array in C: T* p = (T)malloc(size); Dynamisches Array in C++: std::vector<T> v(size);Wenn also in C ein dynamisches Array ein Zeiger ist, der auf einen Speicherbereich zeigt, dann ist es in C++ ein Vector. Also würde h_aliases in C++ so aussehen:
std::vector<std::string> h_aliases;Schade, dass die hostent-Struktur in C geschrieben wurde, aber ich hoffe, Sie haben das Prinzip verstanden.
Der nächste Typ beschreibt den Adresstyp, bei uns also einfach nur AF_INET, IPv6-Adressen sind uns egal. Also ist auch der nächste Parameter nicht relevant und sollte eigentlich immer 4 betragen.
Wichtig ist nun die Liste der IP-Adressen. Diese sieht am Anfang genau so aus wie die Liste der Aliases, doch passen Sie auf: es ist nicht das gleiche. Hier haben wir keine Strings, denn die IP-Adressen werden, wie in der sockaddr, binär gespeichert.
Da ein Bild mehr als 1000 Worte sagt, ist hier mal ein Bild:
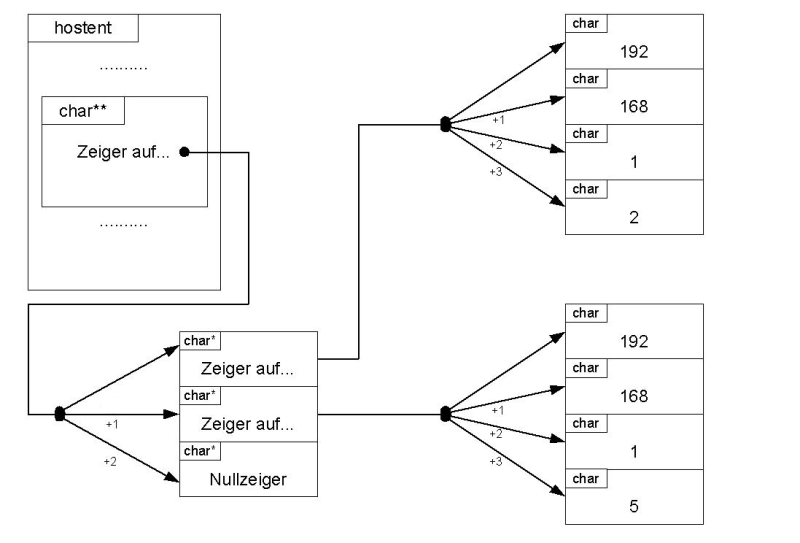
Dies ist der grundsätzliche Aufbau der hostent-Struktur. Kommen wir zurück zur gethostbyname-Funktion. Diese erwartet einen C-String, in dem der Hostname in der Form www.bla.de enthalten ist. Unser neues Programm fängt also so an:
#include <iostream> #ifdef linux #include <netdb.h> // gethostbyname(), hostent #include <arpa/inet.h> // inet_ntoa() #else #include <winsock2.h> #endif int main() { using namespace std; #ifndef linux WSADATA w; if(int result = WSAStartup(MAKEWORD(2,2), &w) != 0) { cout << "Winsock 2 konnte nicht gestartet werden! Error #" << result << endl; return 1; } #endif cout << "Bitte gebe einen Hostnamen ein: "; string Hostname; cin >> Hostname; hostent* phe = gethostbyname(Hostname.c_str());Dass der Zeiger auf die hostent-Struktur wieder freigegeben wird, soll uns nicht kümmern, denn dies wird automatisch erledigt. Erstmal sollten wir checken, ob der Hostname überhaupt existiert:
if(phe == NULL) { cout << "Host konnte nicht aufgeloest werden!" << endl; return 1; }Nun geben wir den Namen sowie die Aliases aus:
cout << "\nHostname: " << phe->h_name << endl << "Aliases: "; for(char** p = phe->h_aliases; *p != 0; ++p) { cout << *p << " "; } cout << endl;Die Funktion der for-Schleife ist nicht ganz einfach: p zeigt auf den ersten C-String und wird nach jedem Schleifendurchlauf um 1 erhöht, bis wir einen Nullzeiger haben. Wichtig: Keinen leeren String der ein '\0' enthält, sondern die Liste von Zeigern auf C-Strings enthält einen Nullzeiger, der nicht auf einen C-String zeigt.
Als nächstes wird einfach nur überprüft, ob es sich bei den IPs um IPv4-Adressen handelt. IPv6 lassen wir außer Acht.
if(phe->h_addrtype != AF_INET) { cout << "Ungueltiger Adresstyp!" << endl; return 1; } if(phe->h_length != 4) { cout << "Ungueltiger IP-Typ!" << endl; return 1; }Nun wollen wir diese IP-Adressen ausgeben, doch sie liegen in binärer Form vor. Also müssen wir sie in einen String umwandeln und hierzu gibt es die Funktion inet_ntoa(). Sie wandelt eine in_addr-Struktur in einen String um, in der Form „x.x.x.x“. Leider haben wir keine Zeiger auf in_addr-Strukturen sondern Zeiger auf chars. Da die in_addr-Struktur die Daten auch nur binär speichert, können wir den Zeiger einfach in einen in_addr-Zeiger casten:
reinterpret_cast<in_addr*>(*phe->h_addr_list);Dieser neue Zeiger muss nun noch dereferenziert werden, da inet_ntoa() eine Instanz und keinen Zeiger erwartet:
cout << inet_ntoa(*reinterpret_cast<in_addr*>(*phe->h_addr_list));Nun müssen wir noch, wie bei den Aliases, die Liste wirklich durchgehen und nicht einfach nur das erste Element nehmen, da ein Host ja auch mehrere IPs haben kann. Der endgültige Code sieht also so aus:
cout << "IP-Adressen: "; for(char** p = phe->h_addr_list; *p != 0; ++p) { cout << inet_ntoa(*reinterpret_cast<in_addr*>(*p)) << " "; } cout << endl; }Um die Funktion der inet_ntoa-Funktion etwas klarer zu machen, hier nochmal eine mögliche Implementierung:
#include <sstream> std::string my_inet_ntoa(in_addr& ip) { unsigned char* p = reinterpret_cast<unsigned char*>(&ip); std::stringstream sstream; for(int i = 0; i < 4 && (i == 0 || (sstream << ".")); ++i) { sstream << static_cast<int>(p[i]); } return sstream.str(); }Nun sind wir schon fertig. Das endgültiges Programm könnt ihr nun testen, mit einer Adresse wie www.google.de oder www.microsoft.com (oder www.kernel.org :P). Alles sollte klappen und als nächstes wollen wir diesen Code in das vorherige Programm einfügen.
4 Integration von nslookup
Nun wollen wir unser eigenes nslookup in das Programm aus Kapitel 2 einfügen. Danach sollte der Benutzer nur noch den Namen der Internetseite eingeben müssen und das Programm kümmert sich um die Verbindung. Dies klingt einfacher als es ist, da ein Host ja mehrere IP-Adressen haben kann und diese müssen alle ausprobiert werden, bevor gesagt wird: "Keine Verbindung möglich!". Denn das wäre ja gelogen ;).
Fangen wir zuerst an wie beim Programm vom vorherigen Kapitel:
#include <iostream> #ifdef linux #include <netdb.h> // gethostbyname(), hostent #include <arpa/inet.h> // inet_ntoa() #else #include <winsock2.h> #endif int main() { using namespace std; #ifndef linux WSADATA w; if(int result = WSAStartup(MAKEWORD(2,2), &w) != 0) { cout << "Winsock 2 konnte nicht gestartet werden! Error #" << result << endl; return 1; } #endif cout << "Bitte gebe einen Hostnamen ein: "; string Hostname; cin >> Hostname; hostent* phe = gethostbyname(Hostname.c_str()); if(phe == NULL) { cout << "Host konnte nicht aufgeloest werden!" << endl; return 1; } cout << "\nHostname: " << phe->h_name << endl << "Aliases: "; for(char** p = phe->h_aliases; *p != 0; ++p) { cout << *p << " "; } cout << endl; if(phe->h_addrtype != AF_INET) { cout << "Ungueltiger Adresstyp!" << endl; return 1; } if(phe->h_length != 4) { cout << "Ungueltiger IP-Typ!" << endl; return 1; }Nun müssen wir jede einzelne IP-Adresse testen, ob sie klappt. Dazu gehen wir die Liste vom Anfang durch und sobald wir eine Verbindung gefunden haben, fahren wir fort. Falls das Ende der Liste erreicht wurde und keine IP-Adresse klappte, brechen wir ab. Mit ein bisschen Logik kann man daraus eine Schleife erstellen, ich habe es so gemacht:
int Socket = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP); if(Socket == -1) { cout << "Socket konnte nicht erstellt werden!" << endl; return 1; } sockaddr_in service; service.sin_family = AF_INET; service.sin_port = htons(80); // Das HTTP-Protokoll benutzt Port 80 char** p = phe->h_addr_list; // p mit erstem Listenelement initialisieren int result; // Ergebnis von connect do { if(*p == NULL) // Ende der Liste { cout << "Verbindung fehlgschlagen!" << endl; return 1; } service.sin_addr.s_addr = *reinterpret_cast<unsigned long*>(*p); ++p; result = connect(Socket, reinterpret_cast<sockaddr*>(&service), sizeof(service)); } while(result == -1); cout << "Verbindung erfolgreich!" << endl;Ich erstelle eine Variable result, die das Ergebnis von connect speichert, eine Variable p die als Iterator dient. Als erstes prüfe ich, ob ein Nullzeiger vorliegt, also ob die Liste zu Ende ist. Wenn nicht, erstelle ich meine binäre IP-Adresse und erhöhe danach schonmal den p-Zeiger (irgendwo muss ich's ja tun). Jetzt wird versucht zu verbinden. Falls result -1 ist, also fehlgeschlagen, dann wird das Ganze wiederholt, wenn nicht geht's nach der Schleife weiter.
Nun müssen wir nur noch die Verbindung beenden und unser Programm ist fertig.
5 Senden und Empfangen
5.1 Grundlegender Aufbau des HTTP-Protokolls
Nun wollen wir uns endlich mit dem Senden und Empfangen von Daten beschäftigen. Was bei uns eine Internetadresse ist, besteht aus folgenden Abschnitten:
http://www.kernel.org/faq/index.html 1 | 2 | 3Zuerst kommt das Protokoll (1), danach der Host den wir auflösen (2) und als letztes die Datei bzw. der Pfad, den wir an den Webserver schicken müssen. Die Kommunikation zwischen Browser und Webserver geschieht hierbei über das HTTP-Protokoll. Es handelt sich also um eine Sprache, mit der der Dateiaustausch über das Internet geregelt werden kann. Ein anderes Protokoll wäre z.B. das FTP-Protokoll.
Nun müssen Sie wissen, wie das HTTP-Protokoll funktioniert: Ein Webserver horcht auf Port 80. Sobald sich ein Client verbindet, wird auf zu empfangende Daten gewartet. Der Client, meistens der Browser, in diesem Fall aber unser Programm, schickt nun eine Anfrage, welche Datei er haben möchte. Bei dieser Anfrage handelt sich um einfachen Text im ASCII-Format (Deswegen auch unter anderem die Probleme beim Realisieren von Domainnamen mit Umlauten). Eine Anfrage, die wir dem Server nach dem Verbindungsaufbau schicken, sieht so aus:GET /faq/index.html HTTP/1.1 Host: www.kernel.org (hier eine leere Zeile)Zuerst kommt ein Befehl, in diesem Fall GET, gefolgt von einem Leerzeichen. Nun kommt die Datei, die wir anfordern, noch ein Leerzeichen und dann die Protokollversion (HTTP/1.0 wäre zum Beispiel die ältere Variante). Nun kommen wir in die nächste Zeile, dabei müssen wir aber eines beachten: Die Zeilenumbrüche sind hier im DOS-Format, das heißt wir haben zuerst ein \r-Zeichen (ASCII-Code 13) und ein \n-Zeichen (ASCII-Code 10). Wollen wir nun also einen String erstellen der unsere Anfrage enthält, würde es so aussehen:
const string request = "GET /faq/index.html HTTP/1.1\r\nHost: www.kernel.org\r\n\r\n";Am Ende haben wir ein \r\n\r\n, hierbei handelt es sich einfach um die leere Zeile, die am Ende gesendet werden muss, damit der Server erkennt, dass hier die Anfrage zu Ende ist.
Nach der Anfrage kommt natürlich die Antwort. Diese besitzt auch einen ganz bestimmten Aufbau, den wir uns aber erst im nächsten Kapitel anschauen wollen. Jetzt kommen wir zuerst zum allgemeinen Senden und Empfangen von Daten.5.2 Die Funktionen send und recv
Das Senden bzw. Empfangen geschieht mit Hilfe folgender Funktionen:
int send(int sockfd, const void *msg, int len, int flags); int recv(int sockfd, void *buf, int len, unsigned int flags);Der Aufbau beider Funktion ist ziemlich gleich. Der erste Parameter ist der Socket, auf dem gesendet werden soll, der zweite ein Zeiger auf einen Binärenspeicherbereich mit der Länge len. Der letzte Parameter flags ist für uns unwichtig und es wird einfach 0 übergeben.
Nicht zu vergessen ist der Rückgabewert: Hierbei handelt es sich um die Anzahl der übertragenen Bytes. Denn auch wenn man versucht, einen Buffer von 100 Byte zu übertragen, kann send damit nicht fertig werden und wird vorher schon aufhören und dann die geschaffte Anzahl zurückgeben, z.B. 34. Unsere Aufgabe ist es also den restlichen Buffer von 64 Bytes noch zu senden. Dazu schreiben wir eine Funktion, die uns diese Arbeit immer abnehmen soll:void SendAll(int socket, const char* const buf, const int size) { int bytesSent = 0; // Anzahl Bytes die wir bereits vom Buffer gesendet haben do { bytesSent += send(socket, buf + bytesSent, size - bytesSent, 0); } while(bytesSent < size); }Diese Funktion sendet den von uns übergebenen Buffer komplett. Doch was passiert nun, wenn während dem Senden ein Fehler auftritt? Vielleicht bricht die Verbindung ab oder geht verloren. Dies signalisiert uns send(), indem es uns einen Wert kleiner 0 zurückgibt.
Da dies unerwartet ist, nehmen wir hierfür Exceptions. Hierzu werden wir die std::runtime_error-Klasse verwenden. Jedes mal wenn wir sie werfen wollen, lassen wir sie von einer Funktion erstellen:std::runtime_error CreateSocketError() {Die Signatur der Funktion ist selbsterklärend, doch wenn wir zum Inhalt kommen, wird's kompliziert. Leider sind die Funktionen zum Erhalt von Fehlermeldungen unter Windows und Linux ziemlich verschieden. Alle Linux-Fans können jetzt aufatmen:
std::ostringstream temp; #ifdef linux temp << "Socket-Fehler #" << errno << ": " << strerror(errno);Da der Konstruktor von std::runtime_error einen std::string erwartet, verwenden wir einen std::ostringstream zur einfachen Formatierung. Wir geben eine Fehlernummer aus, gefolgt von einem Text, der den Fehler beschreibt. Natürlich müssen wir uns dies nicht selbst ausdenken. Eine Fehlernummer wird in der globalen Variable errno gespeichert, mit der Funktion strerror(int) erzeugen wir einen Text den wir ausgeben können. Hierzu muss man nur noch die errno.h am Anfang inkludieren.
Unter Windows sieht das ganze so aus:
#else int error = WSAGetLastError(); temp << "Socket-Fehler #" << error; char* msg; if(FormatMessage(FORMAT_MESSAGE_ALLOCATE_BUFFER | FORMAT_MESSAGE_FROM_SYSTEM, NULL, error, MAKELANGID(LANG_NEUTRAL, SUBLANG_DEFAULT), reinterpret_cast<char*>(&msg), 0, NULL)) { try { temp << ": " << msg; LocalFree(msg); } catch(...) { LocalFree(msg); throw; } } #endifHier gibt die Funktion WSAGetLastError() eine Fehlernummer zurück und FormatMessage erzeugt daraus einen Text. Die genaue Funktionsweise lässt sich in der MSDN nachlesen.
Am Ende unserer Funktion erstellen wir eine Instanz der std::runtime_error-Klasse und geben sie zurück:
return std::runtime_error(temp.str()); }Nun wollen wir von unserer neuen Funktion Gebrauch machen und fügen sie in die SendAll-Funktion ein:
void SendAll(int socket, const char* const buf, const int size) { int bytesSent = 0; // Anzahl Bytes die wir bereits vom Buffer gesendet haben do { int result = send(socket, buf + bytesSent, size - bytesSent, 0); if(result < 0) // Wenn send einen Wert < 0 zurück gibt deutet dies auf einen Fehler hin. { throw CreateSocketError(); } bytesSent += result; } while(bytesSent < size); }Nun entwickeln wir noch eine Funktion für das Empfangen von Daten. Da das HTTP-Protokoll ja zeilenweise sendet, soll unsere Funktion auch so aufgebaut sein:
// Liest eine Zeile des Sockets in einen stringstream void GetLine(int socket, std::stringstream& line) {Wir lesen byteweise von dem Socket bis wir auf einen Zeilenumbruch treffen.
for(char c; recv(socket, &c, 1, 0) > 0; line << c) { if(c == '\n') { return; } }Die Schleife wird nur verlassen, wenn recv einen Wert kleiner oder gleich 0 zurück gibt, somit werfen wir dahinter unsere Exception.
throw CreateSocketError(); }Falls die recv-Funktion einen Wert gleich 0 zurück gibt, deutet dies auf einen normalen Verbindungsabbruch hin. Dies ist der Fall, wenn die andere Seite close/closesocket aufruft.
5.3 Request
Nun wollen wir ein Programm erstellen, das all diese Sachen anwendet. Wir schicken einen Request an www.kernel.org und geben dann erstmal einfach die Ausgabe auf der Konsole aus. Unser Programm fängt so an:
#include <iostream> #include <fstream> #include <stdexcept> // runtime_error #include <sstream> #ifdef linux #include <sys/socket.h> // socket(), connect() #include <arpa/inet.h> // sockaddr_in #include <netdb.h> // gethostbyname(), hostent #include <errno.h> // errno #else #include <winsock2.h> #endif // Hier die Funktionen CreateSocketError, SendLine und GetLine einfügen int main() { using namespace std; #ifndef linux WSADATA w; if(int result = WSAStartup(MAKEWORD(2,2), &w) != 0) { cout << "Winsock 2 konnte nicht gestartet werden! Error #" << result << endl; return 1; } #endif hostent* phe = gethostbyname("www.kernel.org"); if(phe == NULL) { cout << "Host konnte nicht aufgeloest werden!" << endl; return 1; } cout << "\nHostname: " << phe->h_name << endl << "Aliases: "; for(char** p = phe->h_aliases; *p != 0; ++p) { cout << *p << " "; } cout << endl; if(phe->h_addrtype != AF_INET) { cout << "Ungueltiger Adresstyp!" << endl; return 1; } if(phe->h_length != 4) { cout << "Ungueltiger IP-Typ!" << endl; return 1; } int Socket = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP); if(Socket == -1) { cout << "Socket konnte nicht erstellt werden!" << endl; return 1; } sockaddr_in service; service.sin_family = AF_INET; service.sin_port = htons(80); // Das HTTP-Protokoll benutzt Port 80 char** p = phe->h_addr_list; // p mit erstem Listenelement initialisieren int result; // Ergebnis von connect do { if(*p == NULL) // Ende der Liste { cout << "Verbindung fehlgschlagen!" << endl; return 1; } service.sin_addr.s_addr = *reinterpret_cast<unsigned long*>(*p); ++p; result = connect(Socket, reinterpret_cast<sockaddr*>(&service), sizeof(service)); } while(result == -1); cout << "Verbindung erfolgreich!" << endl;Wie Sie sehen, nehmen wir als Hostnamen www.kernel.org, denn die Seite www.kernel.org/faq/index.html soll unsere Testseite werden. Nun wollen wir unsere Anfrage senden:
const string request = "GET /faq/index.html HTTP/1.1\r\nHost: www.kernel.org\r\nConnection: close\r\n\r\n"; SendAll(Socket, request.c_str(), request.size());Dies ist, bis auf das Hinzufügen der folgenden Zeile, die gleiche Anfrage:
Connection: closeSie bewirkt, dass nachdem wir die Antwort erhalten haben, der Server die Verbindung schließt. Die Verbindung könnte z.B. aufrecht erhalten bleiben, wenn wir weitere Request hinterherschicken wollten, um z.B. Bilder zu laden.
Da das Behandeln der Response im nächsten Kapitel behandelt wird, wollen wir die Antwort vorläufig in eine Textdatei schreiben:ofstream fout("output.txt"); cout << "Empfange und schreibe Antwort in output.txt..." << endl; while(true) { stringstream line; try { GetLine(Socket, line); } catch(exception& e) // Ein Fehler oder Verbindungsabbruch { break; // Schleife verlassen } fout << line.str() << endl; // Zeile in die Datei schreiben. }Am Ende schließen wir wie gewohnt das Socket und unser Programm sieht so aus.
Wenn wir es ausführen, wird die Antwort die Response vom Server in die output.txt-Datei geschrieben. Diese sollte ungefähr so anfangen:
HTTP/1.1 200 OK Date: Fri, 15 Dec 2006 14:51:19 GMT Server: Apache/2.2.2 (Fedora) Last-Modified: Wed, 08 Nov 2006 22:06:19 GMT ETag: "b643c8-6118-421c3874aacc0" Accept-Ranges: bytes Content-Length: 24856 Connection: close Content-Type: text/html X-Pad: avoid browser bug <?xml version="1.0" encoding="utf-8"?> ...6 Response
6.1 Statuszeile
Die erste Zeile beschreibt einen Statuscode. Sie besteht aus der HTTP-Version des Servers, einer Status-Nr. und einem Text, der diese beschreibt. Eine Liste aller Codes gibt's unter anderem bei Wikipedia. Für uns wichtig ist zuerst einmal der Code 200: Er steht dafür, dass alles geklappt hat, unsere Anfrage in Ordnung war und die Datei existiert. Ein weiterer wichtiger Status-Code ist 100. Er sagt uns, dass der Server noch etwas Zeit braucht die Anfrage zu verarbeiten und uns gleich noch eine Antwort schicken wird. Das könnte z.B. so aussehen:
HTTP/1.1 100 Continue HTTP/1.1 200 OK Date: Fri, 15 Dec 2006 14:51:19 GMT Server: Apache/2.2.2 (Fedora) ...Nach der ersten Antwort die uns nur sagt, dass es gleich weiter geht, kommt eine freie Zeile und dann die richtige Antwort.
In unserem letzten Programm machen wir jetzt nach dem Verbinden so weiter:const string request = "GET /faq/index.html HTTP/1.1\r\nHost: www.kernel.org\r\nConnection: close\r\n\r\n"; try { SendAll(Socket, request.c_str(), request.size()); int code = 100; // 100 = Continue string Protokoll; stringstream firstLine; // Die erste Linie ist anders aufgebaut als der Rest while(code == 100) { GetLine(Socket, firstLine); firstLine >> Protokoll; firstLine >> code; if(code == 100) { GetLine(Socket, firstLine); // Leere Zeile nach Continue ignorieren } } cout << "Protokoll: " << Protokoll << endl;Mit der GetLine-Funktion (siehe oben) lesen wir die erste Zeile in einen Stringstream ein. Nun schreiben wir den Protokolltyp in einen String. Zur Erinnerung: Der >>-operator von streams liest bis zu einem Leerzeichen ein. Als nächstes lesen wir den Statuscode aus, wenn dieser 100 ist, müssen wir noch die leere Zeile zwischen der neuen Anfrage ignorieren und beginnen dann wieder von vorne.
Nun müssen wir nur noch eine Fehlermeldung ausgeben, wenn ein Statuscode anders als 200 oder 100 auftrat:if(code != 200) { firstLine.ignore(); // Leerzeichen nach dem Statuscode ignorieren string msg; getline(firstLine, msg); cout << "Error #" << code << " - " << msg << endl; return 0; }6.2 Transfer-Arten
Nun kommen wir zum eigentlichen Header. Er besteht aus vielen Argumenten, von denen einige aber nebensächlich sind. Wichtig für uns ist erstmal die allgemeine Übertragungsart:
Normales Übertragen, Dateigröße nicht mit übergeben
Dies ist die einfachste Art der Übertragung. Sobald der Header zu Ende ist, lesen wir mit recv solange, bis der Server die Verbindung schließt. Wir erinnern uns: recv gibt beim Schließen der Verbindung 0 zurück.
Normales Übertragen, Dateigröße übergeben
Nun machen wir alles genauso wie vorher, nur das wir nicht darauf warten müssen, dass recv 0 zurück gibt: Wir hören einfach auf, sobald wir die Datei vollständig erhalten haben. Vorteil: Wir können den Fortschritt in % anzeigen.
Chunked-Encoding
Chunked-Encoding ist die komplizierteste Art: Die Datei wird nicht als ganzes übertragen, sondern in verschiedenen Abschnitten. Dies ist z.B. notwendig, wenn der Server ein PHP-Script ausführt noch während die Seite gesendet wird.
Die für diese 3 Übertragunstypen wichtigen Argumente sind folgende:
Content-Length: 1234 Transfer-Encoding: chunkedContent-Length gibt uns die Größe der Datei in Bytes und das Argument Transfer-Encoding existiert nur dann, wenn auch das Chunked-Encoding angewendet wird.
Wir erstellen uns also eine bool-Variable, die speichert ob das "Tranfer-Encoding: chunked" angegeben wurde, sowie eine Variable, die die übergebene Dateigröße speichert und mit einer Konstanten belegt wird, falls keine Größe angegeben wurde:bool chunked = false; const int noSizeGiven = -1; int size = noSizeGiven;Nun starten wir mir der zeilenweisen Auslesung des Headers:
while(true) { stringstream sstream; GetLine(Socket, sstream); if(sstream.str() == "\r") // Header zu Ende? { break; }Zur Erinnerung: Der Header endet mit einer leeren Zeile, da als Zeilenumbruch allerdings nicht \n verwendet wird (sondern \r\n), handelt es sich um eine Zeile, die nur ein \r enthält:
HTTP/1.1 200 OK\r\nAsd: 123\r\n[b]\r[/b]\nNun lesen wir in einen String ein, der der Name des Arguments ist. Danach ignorieren wir ein Zeichen (das Leerzeichen), um danach den Wert einzulesen.
string left; // Das was links steht sstream >> left; sstream.ignore(); // ignoriert LeerzeichenWenn der Name "Content-Size" ist, lesen wir die Größe ein:
if(left == "Content-Length:") { sstream >> size; }Falls wir auf eine Angabe über das Transfer-Encoding treffen, werten wir den Wert aus. Ist dieser "chunked", setzen wir die Bool-Variable:
if(left == "Transfer-Encoding:") { string transferEncoding; sstream >> transferEncoding; if(transferEncoding == "chunked") { chunked = true; } } }Nun sind wir schon fertig mit der Auswertung des Headers.
")
6.3 Die Übertragung
Nun beginnen wir mit der eigentlichen Übertragung der Datei. Dazu erstellen wir erstmal eine Output-Datei, in die wir binär schreiben werden:
fstream fout("faq.html", ios::binary | ios::out); if(!fout) { cout << "Could Not Create File!" << endl; return 1; }Wir erstellen uns drei Variablen:
int recvSize = 0; // Empfangene Bytes insgesamt char buf[1024]; int bytesRecv = -1; // Empfangene Bytes des letzten recvIn der ersten Variable speichern wir, wieviel Bytes wir schon emfpangen haben (dies ist z.B. für eine Prozentanzeige notwendig). Außerdem erstellen wir ein Array aus 1024 bytes für die Pufferung der Daten.
Als letztes erstellen wir die temporäre Variable bytesRecv, die den letzten Rückgabe wert von recv speichert.if(size != noSizeGiven) // Wenn die Größe über Content-length gegeben wurde { cout << "0%";Wenn eine Größe übergeben wurde, können wir eine Fortschrittsanzeige ausgeben.
Wir empfangen so lange, bis die gesamte Datei übertragen wurde:while(recvSize < size) {Nun schreiben wir die Daten, die wir auf unserem Socket empfangen, in den Buffer:
if((bytesRecv = recv(Socket, buf, sizeof(buf), 0)) <= 0) { throw CreateSocketError(); }Falls recv einen Wert kleiner oder gleich 0 zurück gibt, brechen wir ab und werfen eine Exception.
Nun addieren wir die aktuell empfange Anzahl an Bytes zu der Gesamtanzahl und schreiben den Buffer in die Datei:recvSize += bytesRecv; fout.write(buf, bytesRecv);Als letztes geben wir noch eine Prozentanzeige aus und sind auch schon fertig:
cout << "\r" << recvSize * 100 / size << "%" << flush; // Mit \r springen wir an den Anfang der Zeile } }Nun müssen wir noch die anderen zwei Transfer-Arten implementieren:
else { if(!chunked) { cout << "Downloading... (Unknown Filesize)" << endl; while(bytesRecv != 0) // Wenn recv 0 zurück gibt, wurde die Verbindung beendet { if((bytesRecv = recv(Socket, buf, sizeof(buf), 0)) < 0) { throw CreateSocketError(); } fout.write(buf, bytesRecv); } }Dies ist die normale Übertragung ohne Angabe von Dateigröße. Der Unterschied besteht darin, dass wir nicht wissen, wann die Übertragung zu Ende ist, sondern einfach auf einen Verbindungsabbruch warten müssen.
6.4 Chunked Transfer-Encoding
Das letzte was uns nun noch fehlt, ist die Übertragung mit Chunks. Dazu müssen wir uns wieder den Aufbau angucken:
HTTP/1.1 200 OK Transfer-Encoding: chunked <Größe des Chunks in Hex> <Daten des Chunks> <Größe des zweiten Chunks in Hex> <Daten des zweiten Chunks> 0 Weiteres Argument: Blabla Noch ein Argument: 123 (hier eine leere Zeile)Anstelle der Daten folgt bei dieser Übertragungs-Art eine Zeile in hexadezimalen Schreibweise, der wir die Größe des Chunks in Bytes entnehmen können. Daraufhin kommen die Daten, gefolgt von einem Zeilenumbruch. Nun beginnt entweder ein neuer Chunk, oder es wird die Größe 0 übergeben, was für das Ende der Chunks steht. Hiernach können noch weitere Argumente folgen, die für uns aber unwichtig sind. Hauptsache wir haben die Datei und dann schnell weg :P.
Machen wir also weiter im Code, wo wir vorhin aufgehört haben:
else { cout << "Downloading... (Chunked)" << endl; while(true) { stringstream sstream; GetLine(Socket, sstream); int chunkSize = -1; sstream >> hex >> chunkSize; // Größe des nächsten Parts einlesenWir lesen die erste Zeile ein und schreiben die hexadezimale Zahl in size. Hierzu brauchen wir nur das "hex"-Flag setzen, damit der Stream auch das Hexadezimalsystem anwendet.
Wenn die Größe kleiner oder gleich 0 ist, verlassen wir unsere Schleife:if(chunkSize <= 0) { break; }Nun beginnen wir eine Schleife die den aktuellen Chunk runterlädt:
cout << "Downloading Part (" << chunkSize << " Bytes)... " << endl; recvSize = 0; // Vor jeder Schleife wieder auf 0 setzen while(recvSize < chunkSize) {Nun erstellen wir uns eine Variable, die nur speichert, wie viel Bytes wir diesen Schleifendurchgang noch empfangen müssen:
int bytesToRecv = chunkSize - recvSize;Dies ist nämlich notwendig, da wir ja am Ende unseres Chunks, nicht mehr empfangen dürfen als notwendig, sonst könnten wir z.B. versehentlich schon die Größe des nächsten Chunks in unsere Datei schreiben und das wäre fatal. Deswegen übergeben wir an recv als Größe entweder sizeof(buf) oder aber bytesToRecv, wenn wir nur noch ein kleines Stück empfangen müssen:
if((bytesRecv = recv(Socket, buf, bytesToRecv > sizeof(buf) ? sizeof(buf) : bytesToRecv, 0)) <= 0) { throw CreateSocketError(); }Nun addieren wir wie gewohnt die empfangenen Bytes und geben eine Prozentanzeige aus:
recvSize += bytesRecv; fout.write(buf, bytesRecv); cout << "\r" << recvSize * 100 / chunkSize << "%" << flush; } cout << endl;Nun haben wir alles empfangen, doch halt: Haben wir nicht noch etwas vergessen? Richtig: Nach den Daten erfolgt ein Zeilenumbruch. Dieser besteht aus einem \r und einem \n, also 2 Bytes. Es ist also am einfachesten wenn wir eben 2 Bytes vom Socket ignorieren:
for(int i = 0; i < 2; ++i) { char temp; recv(Socket, &temp, 1, 0); }Nun geben wir noch ein "Finished!" aus und unser Programm ist fertig:
} } } cout << endl << "Finished!" << endl; } catch(exception& e) { cout << endl; cerr << e.what() << endl; } #ifdef linux close(Socket); // Verbindung beenden #else closesocket(Socket); // Windows-Variante #endif }Das ganze Programm sollte uns jetzt die faq.html-Datei herrunterladen und auf der Festplatte speichern. Nun sind wir schon fast fertig.
7 Der letzte Feinschliff
Als letztes wollen wir unser Programm um ein paar Funktionen ergänzen, die eine Eingabe einer URL ermöglichen. Schließlich will man nicht immer nur eine Datei herunterladen. Dazu fügen wir am Anfang eine Eingabe hinzu:
int main() { using namespace std; cout << "URL: "; string URL; cin >> URL; // User gibt URL der Datei ein, die heruntergeladen werden sollNun müssen wir ein vor der URL evtl. existierendes http:// entfernen:
// Entfernt das http:// vor der URL void RemoveHttp(std::string& URL) { size_t pos = URL.find("http://"); if(pos != std::string::npos) { URL.erase(0, 7); } }Diese Funktion rufen wir nun nach dem Start von WinSock auf:
#ifndef linux WSADATA w; if(int result = WSAStartup(MAKEWORD(2,2), &w) != 0) { cout << "Winsock 2 konnte nicht gestartet werden! Error #" << result << endl; return 1; } #endif RemoveHttp(URL);Jetzt extrahieren wir den Hostnamen aus der URL und speichern ihn in einem neuen String ab:
string hostname = RemoveHostname(URL);Die RemoveHostname-Funktion sieht so aus:
// Gibt den Hostnamen zurück und entfernt ihn aus der URL, sodass nur noch der Pfad übrigbleibt std::string RemoveHostname(std::string& URL) { size_t pos = URL.find("/"); if(pos == std::string::npos) { std::string temp = URL; URL = "/"; return temp; } std::string temp = URL.substr(0, pos); URL.erase(0, pos); return temp; }Nun lösen wir den Hostnamen in dem neuen String auf:
hostent* phe = gethostbyname(hostname.c_str());Es folgt der Aufbau der Verbindung:
if(phe == NULL) // ... cout << "Verbindung erfolgreich!" << endl;Als nächstes müssen wir eine HTTP-Request erstellen:
string request = "GET "; request += URL; // z.B. /faq/index.html request += " HTTP/1.1\n"; request += "Host: " + hostname + "\nConnection: close\n\n";Diesen übergeben wir jetzt an unsere SendAll-Funktion und danach folgt der Code aus 05.cpp bis zur Öffnung des Filestreams:
try { SendAll(Socket, request.c_str(), request.size()); // Anfrage an Server senden int code = 100; // 100 = Continue // ... }Nun muss die Datei erstellt und der Inhalt eingelesen werden. Das größte Problem ist hierbei der Dateiname: Bei vielen Fällen lässt er sich extrahieren aber manchmal ist er auch unbekannt (z.B. www.google.de). Die sauberste Methode wäre es, das Response-Argument "Content-Type:" auszuwerten, dies wollen wir uns aber mal sparen und nennen unsere Datei einfach download und hängen eine Endung an, falls diese in der URL enhalten ist:
// Gibt die Dateiendung in der URL zurück std::string GetFileEnding(std::string& URL) { using namespace std; size_t pos = URL.rfind("."); if(pos == string::npos) { return ""; } URL.erase(0, pos); string ending = "."; // Algorithmus um Sachen wie ?index=home nicht zuzulassen for(string::iterator it = URL.begin() + 1; it != URL.end(); ++it) { if(isalpha(*it)) { ending += *it; } else { break; } } return ending; }string filename = "download" + GetFileEnding(URL); cout << "Filename: " << filename << endl; fstream fout(filename.c_str(), ios::binary | ios::out); if(!fout) { cout << "Could Not Create File!" << endl; return 1; } int recvSize = 0; // Empfangene Bytes insgesamt // ... } catch(exception& e) { cout << endl; cerr << e.what() << endl; } #ifdef linux close(Socket); // Verbindung beenden #else closesocket(Socket); // Windows-Variante #endif }Fertig! Das komplette Programm können Sie sich hier herunterladen.
8 Nachwort
Falls Sie eine URL finden sollten, die dieses Programm nicht herunterladen kann, können Sie auf mein Tutorial antworten und mir den Link mitteilen, damit ich es mir ansehen kann.
Bei allgemeinen Fragen zum Thema Sockets können Sie in der WinAPI- oder der Linux/Unix-Abteilung nachfragen.In meinem Code rufe ich recv auf, um nur ein einziges Byte zu empfangen. Dies sollte man in der Praxis möglichst unterlassen und immer eine angemesse Buffergröße wählen, z.B. 4 KB. Hierdurch kann recv uns einzelne TCP-Packete im Ganzen zurück geben. Um trotzdem zeilenweise einzulesen muss man einfach die recv-Funktion in seiner eigenen Funktion kapseln. Dies sollte man sowieso tun, da recv und send sehr low-level sind. Ein auf diese Weise verändertes Programm sähe so aus.
Desweiteren wurde die gethostbyname-Funktion von der flexibleren getaddrinfo-Funktion ersetzt. Eine Erklärung sowie Beispiele finden Sie hier.Ich bedanke mich bei jcmds, flammenvogel, scrub, GPC, Artchi, predator und allen anderen aus der Redaktion, die mir geholfen haben. Das war's von mir, vielen Dank fürs Lesen!
9 Linkliste
Socket-Referenz
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/winsock/winsock/wsastartup_2.aspSocket-Tutorial
http://beej.us/guide/bgnet/HTTP-Tutorial
http://www.jmarshall.com/easy/http/RFC für HTTP/1.1
http://tools.ietf.org/html/rfc2616
-
joomoo schrieb:
unsigned short my_htons(unsigned short h) { char* p = reinterpret_cast<char*>(&h); char n[2]; n[0] = p[1]; n[1] = p[0]; return *reinterpret_cast<unsigned short*>(n); }so'n umständlichen endiantauscher hab' ich noch nie gesehen

mach so:unsigned short my_htons (unsigned short h) { return (h>>8) | (h<<8); }oder so:
#ifdef BIG_ENDIAN #define MY_HTONS(h) (h) #else #define MY_HTONS(h) ((h>>8)|(h<<8)) #endif:xmas2:
-
gethostbyname sollte man nicht mehr benutzen, sondern man sollte getaddrinfo verwenden.
-
http://www.c-plusplus.net/magazin/bilder/sockets_und_das_http-protokoll/07.cpp
Der Link funktioniert nicht.
-
Dies signalisiert uns send(), indem es uns einen Wert gleich 0, für eine normale Beendigung der Verbindung
Das ist IMHO falsch. Wenn die Verbindung venünftig beendet wird kriegt man das nur über recv mit.
Zu WSAStartup: Wenn das fehlschlägt darf man WSAGetLastError nicht benutzen, sondern man muss den Rückgabewert als Fehlercode nehmen.
-
Hallo addr,
Vielen Dank für die Hinweise, die Datei hab ich gerade eben hochgeladen.
Die anderen Sachen schau ich mir auch eben an und antworte gleich nochmal (bin gerade nach Hause gekommen).mfg.
-
ten schrieb:
joomoo schrieb:
unsigned short my_htons(unsigned short h) { char* p = reinterpret_cast<char*>(&h); char n[2]; n[0] = p[1]; n[1] = p[0]; return *reinterpret_cast<unsigned short*>(n); }so'n umständlichen endiantauscher hab' ich noch nie gesehen
mach so:unsigned short my_htons (unsigned short h) { return (h>>8) | (h<<8); }Klar ist der Endiantauscher umständlich, doch ich hab ihn ja auch nicht zum Einsetzen geschrieben sondern um die Funktionsweise zu demonstrieren. Deswegen wollte ich lieber auf Bitoperatoren verzichten.
mfg.
edit: Dies war ja gar nicht addr, sondern ten. Auch an dich ein großes Dankeschön!
-
gethostbyname sollte man nicht mehr benutzen, sondern man sollte getaddrinfo verwenden.
Oh, das wusste ich gar nicht. Ich hatte mich nach Beej's Network Guide gerichtet. Ändern kann ich es leider nicht mehr aber ich habe eine Bemerkung am Ende ergänzt.
Das ist IMHO falsch. Wenn die Verbindung venünftig beendet wird kriegt man das nur über recv mit.
Tatsächlich. Vielen Dank, ich hab es jetzt im Artikel korrigiert.
Zu WSAStartup: Wenn das fehlschlägt darf man WSAGetLastError nicht benutzen, sondern man muss den Rückgabewert als Fehlercode nehmen.
Danke, ich hab's jetzt geändert und gebe den Rückgabewert aus.
mfg.
-
Das eingescannte Bild ist einfach nur cool


-
Das eingescannte Bild wirkt einfach nur billig.
-
Die Kompressionsrate des JPEGs ist nur zu hoch. Man kann deshalb fast nichts erkennen. Ansonst hat das Bild irgendwie einen gewissen Charme.

-
Ja das Bid ist ein bisschen billig, das hab ich in einer langweiligen Geschichtsstunde gemalt
Falls jemand Zeit und Lust hat kann er ja versuchen es durch eine schöne Grafik zu ersetzen, ich kenn mich leider mit sowas nicht aus.
mfg.
-
Ich hab den Text zwischen den Zeilen auf dem Bild verstanden.
-
scrub war so nett und hatt das Bild nachgebaut. Das neue Bild könnt ihr schon im Artikel bewundern, das alte Bild gibt's noch hier:
http://www.c-plusplus.net/magazin/bilder/sockets_und_das_http-protokoll/hostent.jpg@scrub
Vielen Dank für das Bild!! Ich hab noch eine Kleinigkeit geändert und die Auflösung etwas runter gesetzt damit auch 1024-User in den Genuss kommen.mfg.
-
joomoo schrieb:
#ifdef linux #include <sys/socket.h> // socket(), connect() #include <arpa/inet.h> // sockaddr_in #else #include <winsock2.h> #endifDas ist ziemlich unportabel. Besser ist:
/* all UNIX-like OSs (Linux, *BSD, MacOSX, Solaris, ...) */ #if defined(unix) || defined(__unix) || defined(__unix__) #include <sys/socket.h> #include <arpa/inet.h> /* MS Windows */ #elif defined(WIN32) || defined(_WIN32) || defined(__WIN32__) || defined(__TOS_WIN__) #include <winsock2.h> /* IBM OS/2 */ #elif defined(OS2) || defined(_OS2) || defined(__OS2__) || defined(__TOS_OS2__) #include <sys/socket.h> #include <arpa/nameser.h> #else #error unsupported or unknown operating system. #endif
-
Fye schrieb:
Besser ist...
das ist ja schon mal ein anfang. kannst es ja noch ergänzen: http://predef.sourceforge.net/preos.html
-
Ich hab nicht gesagt, dass das vollständig ist. Ich mein halt, sich auf Windows und Linux zu beschränken und die armen BSD'ler und MacOSX'ler außen vor zu lassen ist nicht so toll.
")
BTW: Die Seite kenne ich. Was meinste, wo ich die Makros alle herhabe?
-
Fye schrieb:
Ich hab nicht gesagt, dass das vollständig ist. Ich mein halt, sich auf Windows und Linux zu beschränken und die armen BSD'ler und MacOSX'ler außen vor zu lassen ist nicht so toll.
aber os-halbe wird berücksichtigt. ein system dass seit 10 jahren kein schwein mehr verwendet
Fye schrieb:
BTW: Die Seite kenne ich. Was meinste, wo ich die Makros alle herhabe?
selbst gebastelt? ich dachte das hast du aus irgendso'nem open source projekt rauskopiert...
-
Müsste es nicht HTT-Protokoll und FT-Protokoll heißen?
-
void SendAll(int socket, const char* const buf, const size_t size) { size_t bytesSent = 0; // Anzahl Bytes die wir bereits vom Buffer gesendet haben do { bytesSent += send(socket, buf + bytesSent, size, 0); if(bytesSent < 0) // Wenn send einen Wert < 0 zurück gibt deutet dies auf einen Fehler hin. { throw CreateSocketError(); } } while(bytesSent < size); }Ich habe den Artikel nur kurz überflogen, aber das sieht falsch aus - muss der dritte Parameter nicht size - bytesSent sein? Sonst liest send() unter Umständen über den Puffer hinaus. Außerdem kann es nach dem ersten Schleifendurchlauf passieren, dass bytesSent schon einen positiven Wert hat, send() etwas negatives zurückgibt und bytesSent danach aber immer noch positiv ist.
{kind=link}