Cachemisses - relevanz
-
otze schrieb:
Warum? beide Programme waren sehr Datenintensiv. Sie haben also immer eine Menge Daten in den Cache gezogen mit denen sie dann weiter gerechnet haben. Nun bedeutet 4 Kerne nicht auch 4 Caches. Effektiv haben sich damit die beiden parallel laufenden Prozesse gegenseitig den Cache zerschossen und fleissig Cachemisses produziert.
Bist du sicher? Hast du das nen Thread-Profiler ermitteln lassen, oder ist das einfach nur ne Schätzung?
")
Es gibt nämlich zumindest einen anderen Effekt, der da kräftig mit reinspielen kann, und den ich für den wahrscheinlicheren Übeltäter halte: False Sharing
-
Kann mal einer ein Codebeispiel zeigen, bei dem man das mit den Cachemisses wirklich sieht. Ich hab was versucht, aber die 2. Version ist immer langsamer, egal wie groß das Array ist. Oder ist der Cache nur ein paar hundert Byte groß?
int main( int argc, char**) { std::cout<<argc<<"\n"; #define MM const int M = 40000000; const size_t N = 100*argc; std::vector<int> v(N); for(size_t i = 0; i<N; i++) { v[i]=1; } #ifdef MMM size_t sum=0; clock_t start = clock(); for(int m = 0; m<M; m++) { for(size_t i = 0; i<N; i+=2 ) { sum += v[i] + v[i+1]; } } clock_t end = clock(); std::cout << "1. time: " << end-start << " sum: " <<sum << "\n"; #else size_t sum = 0; const size_t N2 = N/2; clock_t start = clock(); for(int m = 0; m<M; m++) { for(size_t i = 0; i<N2; i++ ) { sum += v[i] + v[N2+i]; //sum += v[i] + v[N-i-1]; } } clock_t end = clock(); std::cout << "2. time: " << end-start << " sum: " <<sum << "\n"; #endif }
-
beim cache geht es meines wissens nicht so um die größe das wäre dann eher die cacheline. beim cache kommt es darauf an, dass man häufig auf ein und die selbe adresse(n) zugreift. bsp.
10 mal zugriff auf 10 unterschiedliche adressen vs. zugriff auf 100 unterschiedliche adressen (um das richtig zu messen sollte jede adresse auf einer eigenen cacheline liegen)
-
der beste Weg das zu zeigen, ist mit unterschiedlichen Schrittlängen durch den Speicher zu gehen.
step = 1;//16 sollte der erste Performance-Breakdown sein for(size_t i=0;i < N;i+=step){ //mach was mit v[i] }
-
Wenn ich mit step=16 durch ein 16 mal größeres Array gehe, brauche ich gerade vier mal länger als mit step=1 durch ein kleineres Array. Und das auch nur, wenn ich nur eine einfache Operation (sum += v[i]) mache. Wenn ich etwas komplizierteres mache (sum += v[i] / v[i]; ), kann ich keinen Unterschied mehr messen. Das mit dem Cachemiss sieht mir relativ überbewertet aus.
-
Sorry, ich hatte dich verwirrt.
schau mal hier:
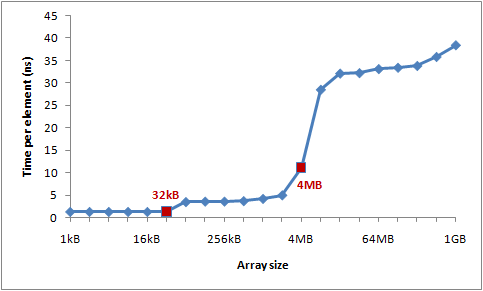
http://igoro.com/archive/gallery-of-processor-cache-effects/insbesondere das Bild:
http://igoro.com/wordpress/wp-content/uploads/2010/02/image.png
-
Naja, was soll das aussagen? Soll ich meine Daten nicht in einem 64MB Array verteilen, wenn ich sie auch ein ein 32kB Array bekommen würde? Wer macht sowas? Irgendwie scheint mir dass so, als das man sich dazu noch dümmer anstellen muss, als einen schlechten Algo zu schreiben, der O(N*M) statt O(N+M) hat.
-
Der Artikel besagt: es gibt Cachemisses und sie sind relevant. Natürlich wird niemand so einen Code schrieben wie dort, der nur zu Veranschaulichung der Problematik dient. Ich dachte ja eigentlich, das wäre klar

Aber wie viele Leute machen sowas?
std::vector<MyObject*> objects; for (o in objects) o->getFoo("blub")->doSth();Und genau in solchen Fällen landet man überall im Speicher und hat permanent cache misses. Der Artikel vernaschaulicht auch verdammt gut, warum manchmal lineare Suche in einer Datenmenge wesentlich schneller sein kann als Bäume.
Ich hab letztens ein nettes paper von NVIDIA gelesen, wo sie ihr Bufferfree Design als OpenGl extension vorgestellt haben. Und da stand mal Knochentrocken drin, dass Bufferlookups im RAM durch Cache Misses so viel Zeit kosten, dass man in vielen Fällen Faktor 2-3 beim Rendern rausholen kann, nur indem man diese Lookups spart.
//edit hier
http://developer.nvidia.com/object/bindless_graphics.htmlbinds require several reads from the driver internal object data structure to accomplish what the driver actually needs to do. In an OpenGL driver, it looks like this:
* name->obj (lookup object by name)
* obj->{refcount, GPU address, state, etc.} (dereference object to reference count it, to get its GPU virtual address, and validate its state).Each of these dereferences has a high probability of causing a CPU L2 cache miss due to the inherently LRU-eviction-unfriendly nature of graphics applications (each frame starts over at the beginning). These L2 cache misses are a huge bottleneck in modern drivers, and a penalty paid for every frame rendered.
-
otze schrieb:
Der Artikel besagt: es gibt Cachemisses und sie sind relevant. Natürlich wird niemand so einen Code schrieben wie dort, der nur zu Veranschaulichung der Problematik dient. Ich dachte ja eigentlich, das wäre klar
Und genau das ist das Problem an solchen "Beweisen", es wird immer ein unrealistisches Beispiel gezeigt, bei dem die Auswirkung besonders groß ist. Mit realem Code hat das selten was zu tun und darum halte ich sowas für wertlos.
Aber wie viele Leute machen sowas?
std::vector<MyObject*> objects; for (o in objects) o->getFoo("blub")->doSth();Und genau in solchen Fällen landet man überall im Speicher und hat permanent cache misses.
Und wo hast du dazu einen Test der zeigt, wieviel Zeit in einem realen Programm durch Cachemisses verschwendet wird?
Ich hab letztens ein nettes paper von NVIDIA gelesen, wo sie ihr Bufferfree Design als OpenGl extension vorgestellt haben. Und da stand mal Knochentrocken drin, dass Bufferlookups im RAM durch Cache Misses so viel Zeit kosten, dass man in vielen Fällen Faktor 2-3 beim Rendern rausholen kann, nur indem man diese Lookups spart.
//edit hier
http://developer.nvidia.com/object/bindless_graphics.htmlbinds require several reads from the driver internal object data structure to accomplish what the driver actually needs to do. In an OpenGL driver, it looks like this:
* name->obj (lookup object by name)
* obj->{refcount, GPU address, state, etc.} (dereference object to reference count it, to get its GPU virtual address, and validate its state).Each of these dereferences has a high probability of causing a CPU L2 cache miss due to the inherently LRU-eviction-unfriendly nature of graphics applications (each frame starts over at the beginning). These L2 cache misses are a huge bottleneck in modern drivers, and a penalty paid for every frame rendered.
Und jetzt müsste noch mal einer prüfen, was man noch rausholen kann, wenn man nicht soviel Müll programmieren würde. Meine Erfahrung ist, dass meistens Zeug programmiert wird, das soweit vom Optimum weg ist, dass man noch lange nicht über Cachemisses nachdenken muss. Vorallem, wenn mehrere Leute an einem Projekt arbeiten wird soviel Zeug programmiert das nicht zusammen passt. Das letzte Beispiel das ich optimiert hab, war einen allgemeinen Callback für alle möglichen Änderungen durch einen für genau die Änderung die einen wirklich interessiert zu ersetzen. Hat den Vorgang von mehreren Sekunden auf deutlich unter eine Sekunde reduziert.
-
Miss Cache schrieb:
Und genau das ist das Problem an solchen "Beweisen", es wird immer ein unrealistisches Beispiel gezeigt, bei dem die Auswirkung besonders groß ist. Mit realem Code hat das selten was zu tun und darum halte ich sowas für wertlos.
Ganz ehrlich: dann lass es sein.
Cache Misses sind nicht etwas dass trivial zu erkennen ist. Sie sind immer von der Umgebung abhaengig. Deshalb ist es nicht einfach simplen Code zu zeigen der sinnvoll cache misses demonstriert.
Hier in dem Thread gab es massig Infos. Wenn die dir nicht reicht, dann mach doch ein Referat ueber Pferde.
-
Ach Shade, wenn doch nur alle so toll wären wie du... Merkst noch nicht mal, dass ich nicht der bin der den Thread gestartet hat.
-
Sehr interessanter Thread

-
Shade Of Mine kann man einfach nicht mehr ernst nehmen.
-
@Miss Cache natürlich liegen die bremsklötze meist woanders. allerdings zeichnet einen guten programmierer aus, dass er nicht nur seine programmiersprache/algorithmen/librarys kennt, sondern sich auch mit der darunterliegenden hardware bzw. seinem compiler auskennt. ich denke es ist schon sinnvoll sich auch über sowas gedanken zu machen. deswegen muß man aber nicht jeden code dahingehend optimieren. desweiteren denke ich das heutzutage fast keiner mehr in der lage ist das system als ganzes zu durchblicken. dazu ist software mittlerweile einfach zu komplex.
-
@Miss Cache:
Ganz einfaches & IMO sehr reales Beispiel:
Du hast ein 2D Array, in den du alle Werte in einem rechteckigen Ausschnitt verdoppeln willst.
Da es um einen rechteckigen Ausschnitt geht kann man nicht einfach eine Schleife von 0 bis (width * height - 1) laufen lassen.
Also schreibt man zwei schleifen.Variante 1:
int* array = ... size_t const xStep = 1; size_t const yStep = arrayWidth; for (size_t x = left; x < right; x++) { int* p = &arrary[x * xStep + y * yStep]; for (size_t y = top; y < bottom; y++) { *p += *p; p += yStep; } }Variante 2:
int* array = ... size_t const xStep = 1; size_t const yStep = arrayWidth; for (size_t y = top; y < bottom; y++) { int* p = &arrary[x * xStep + y * yStep]; for (size_t x = left; x < right; x++) { *p += *p; p += xStep; } }Variante 1 ist wesentlich langsamer als Variante 2.
Wenn man ein wenig über Caches & Speicherzugriffe bescheid weiss, ist klar warum.
Wenn man nichts über Caches weiss, könnte man Variante 1 programmieren, und nichtmal auf die Idee kommen dass das noch schneller geht.Weiters ist der in dem "gallery-of-processor-cache-effects" Posting/Paper auch beschriebene "false sharing" Effekt sehr real, das passiert oft genug. Nur wird es oft nicht bemerkt, da kaum jemand ein Programm von einem Tool ala Intel Thread-Profiler untersuchen lässt. Und wenn man nicht weiss wo die Bremsklötze sind, warum sollte man dann auf die Idee kommen andere Varianten auszuprobieren.
-
Miss Cache schrieb:
Das mit dem Cachemiss sieht mir relativ überbewertet aus.
Dein persönliches Empfinden ist unbegründet. Es gibt genügend Paper, die gerade das Gegenteilige belegen.
-
OK, bei der Bildverarbeitung kann man schon etwas langsam machen, wenn man überhaupt keine Ahung von Caches hat und quer durch den Speicher geht, aber davon, dass Cachemisses das sind was jetzt Programme so furchbar langsam macht, sind wir weit weg. Die meisten Programme sind viel schlechter durchdacht, als ein bekannter Bildverarbeitungsalgo. da läßt sich viel einfacher viel mehr rausholen, als man jetzt versuchen müsste alles perfekt auf den Cache anzupassen. Bei den meisten Programmen dürfte es ungefähr so sinnvoll sein nach Cachemisses zu suchen, wie mit ner Dampfwalze in nen Windkanal zu gehen.
-
meeeep schrieb:
Miss Cache schrieb:
Das mit dem Cachemiss sieht mir relativ überbewertet aus.
Dein persönliches Empfinden ist unbegründet. Es gibt genügend Paper, die gerade das Gegenteilige belegen.
Ja, leider gibt es (wahrscheinlich) keine Paper, die untersuchen wieviele Programme einfach schlecht programmiert sind und ganz unabhängig von Cachemisses deutlich schneller sein könnten, wenn nicht soviel Müll programmiert werden würde. Da könnte man dann etwas über viel größere Performancegewinne lesen, als in den Papers über Cachemisses.
-
Und was hat das mit dem Thema zu tun?
-
Tim schrieb:
Und was hat das mit dem Thema zu tun?
Ich bezeifle einfach, dass das die großen Probleme moderner Programme sind.
TGGC schrieb:
Cache Misses sind in einem normalen PCs das ungefaher langsamste was er so macht. Sie werden immer relevanter, da die Speicheranbindungen langsamer wachsen als alles andere.
rüdiger schrieb:
Die Relevanz ist heutzutage größer denn je. Das liegt nämlich daran, dass die Geschwindigkeit der CPUs drastisch wächst. Aber die Anbindung zum RAM nicht schnell genug nachkommt. Das heißt das Zugriffe zum RAM proportional teurer werden und daher wird es relevanter, dass man sich besser darum kümmert, dass die wichtigen Daten in den Cache passen.
{kind=link}