RGB zu YCbCr
-
hustbaer schrieb:
Und nochwas...
if ((i + 8 + 1) % 2) A; else B; // ist das selbe wie if ((i + 1) % 2) A; else B; // und das selbe wie if (i % 2) B; else A;Erstmal zu dem. Das ist schlau.
 Danke dafür.
Danke dafür.hustbaer schrieb:
Sehr schön.
Ich hatte es übrigens so gemeint:#define ZZIDX(x, y) (x + (y * 8)) unsigned char const g_zigZagTable[64] = { ZZIDX(0, 0), ZZIDX(0, 1), ZZIDX(1, 0), ZZIDX(2, 0), ZZIDX(1, 1), ZZIDX(0, 2), ZZIDX(0, 3), ZZIDX(1, 2), ZZIDX(2, 1), ZZIDX(3, 0), ZZIDX(4, 0), ZZIDX(3, 1), ZZIDX(2, 2), ZZIDX(1, 3), ZZIDX(0, 4), ZZIDX(0, 5), ZZIDX(1, 4), ZZIDX(2, 3), ZZIDX(3, 2), ZZIDX(4, 1), ZZIDX(5, 0), ZZIDX(6, 0), ZZIDX(5, 1), ZZIDX(4, 2), ZZIDX(3, 3), ZZIDX(2, 4), ZZIDX(1, 5), ZZIDX(0, 6), ZZIDX(0, 7), ZZIDX(1, 6), ZZIDX(2, 5), ZZIDX(3, 4), ZZIDX(4, 3), ZZIDX(5, 2), ZZIDX(6, 1), ZZIDX(7, 0), ZZIDX(7, 1), ZZIDX(6, 2), ZZIDX(5, 3), ZZIDX(4, 4), ZZIDX(3, 5), ZZIDX(2, 6), ZZIDX(1, 7), ZZIDX(2, 7), ZZIDX(3, 6), ZZIDX(4, 5), ZZIDX(5, 4), ZZIDX(6, 3), ZZIDX(7, 2), ZZIDX(7, 3), ZZIDX(6, 4), ZZIDX(5, 5), ZZIDX(4, 6), ZZIDX(3, 7), ZZIDX(4, 7), ZZIDX(5, 6), ZZIDX(6, 5), ZZIDX(7, 4), ZZIDX(7, 5), ZZIDX(6, 6), ZZIDX(5, 7), ZZIDX(6, 7), ZZIDX(7, 6), ZZIDX(7, 7), }; void Bar() { // Meine Variante for (int i = 0; i < 64; i++) { int x = g_zigZagTable[i] & 7; int y = g_zigZagTable[i] / 8; printf("%d, %d\n", x, y); } } int main() { Foo(); printf("\n\n"); Bar(); }Man ersetzt also die 6 Schleifen durch eine Schleife + einen 64 Byte grossen Table.
mMn. wesentlich übersichtlicher.
[/cpp]Ahhhhaa das verstehe ich nun auch. Ich danke dir dafür das ist viel besser. Dazu kommt das bei deiner Variante nur eine Tabelle und bei mir ein 3d Array. Vielen dank.
Ich werde mal weiter machen und hier weiter meine Vorschritte posten.
-
Mal eine kleine Frage...
Die DCT oder auch iDCT Rechnung muss ja mit jedem wert durch geführt werden. Also wenn ich alle werte die ich beim Decoden nach der ReQuantisierung habe in einen Vektor pushe, könnte ich doch dann einfach jeden Wert ohne 8x8 Matrix errechnen oder?
Dann noch die Farbumwandlung und Überabtastung und schon bin ich fertig ??
-
Ich glaub du verwechselst da gerade was. Oder ich verstehe dich nicht richtig. Die (i)DCT kann immer nur auf ganzen 8x8 Blöcken arbeiten.
Also beim Decoden hast du (frei aus dem Gedächtnis):
Entropy Decoding (Huffman/Arithmetic) => De-Quantisierung => De-ZigZag => iDCTDann bist du im Prinzip fertig und hast ein Bild in dem Colorspace und den Channel-Auflösungen vorliegen wie sie abgespeichert wurden.
Wenn Subsampling und YUV verwendet wurde, und du 1:1:1 Sampling und RGB haben willst folgt darauf nochResampling => Color Space ConversionBeim Entropy Decoding gibt's sowieso (noch) keine Blöcke, da entstehen die ja erst.
Die De-Quantisierung arbeitet zwar im Prinzip auf jedem Wert einzeln, aber der Quantizer muss aus an der richtigen Stelle der Quantizer-Matrix nachgeschlagen werden - ist also auch nicht ganz von der Block-Struktur losgelöst.
De-ZigZag und iDCT sind sowieso total blockgebunden.Resampling ist dann auf dem ganzen Bild zu machen, und Color Space Conversion auf einzelnen Pixeln, wobei du da aber die Werte aller 3 Kanäle für diesen Pixel gleichzeitig brauchst.
-
Hmm ... also ich hab grade überlegt. Bei der Quantisierung ist es doch so das man 2 Matrizen je nachdem ob De- oder Quantisierung * () / nimmt. Da ist es für mich auch logisch. Gut Huffman ist doch unabhängig von dem 8x8 Block man muss nur wissen welche Tabelle man anwenden muss. Beispiel: Man hat 3 8x8 Blöcke, Block 1 und 2 nutzen Tabelle 1 und der 3 Tabelle 2. Nun kann ich ja auch auf die ersten 128 Zeichen Tabelle 1 anwenden und auf die letzten von 129-192 Tabelle 2 oder nicht?
Den Zick Zack muss man dann wieder mit 8x8 Blöcken machen das ist mir klar. Die Reihenfolge ist ja dadrauf ausgelegt.
Gut nun (i)DCT da muss man ja die gleiche Rechnung für jedes Zeichen machen, also für jeden AC und wenn ich das richtig verstanden hab für jeden DC. Da hab ich gedacht das man das nicht unbedingt in einem 8x8 Block machen muss. Oder hab ich bei der (i)DCT was falsch verstanden??Zur Reihenfolge noch mal
Encoder:
RGB zu YCbCr -> dann für jede Schicht ein Scan -> DCT -> Quantisierung -> RLE -> Huffman -> 010100011...
Decoder:
01010011... -> Huffman -> RLE -> Dequantisierung -> iDCT -> YCbCr zu RGB
-
Fuchs aus dem Wald schrieb:
Gut nun (i)DCT da muss man ja die gleiche Rechnung für jedes Zeichen machen, also für jeden AC und wenn ich das richtig verstanden hab für jeden DC. Da hab ich gedacht das man das nicht unbedingt in einem 8x8 Block machen muss. Oder hab ich bei der (i)DCT was falsch verstanden??
Wie willst du eine Frequenzzerlegung machen, wenn du nur einen Wert kennst? Das kann nicht gehen. Aber wie gesagt: versuch's zu implementieren, dann siehst du ganz schnell warum es nicht geht.
-
Ja ok.
Das war ziemlich dumm von mir. ^^
Ich hab mir jetzt mal so ein kleines Programm zum testen geschrieben, da ich ein Buch hier habe (Das hier)
in dem ein Beispiel drin ist. Ich hab mir mal den ersten 8x8 Block abgetippt + die Quantisierungstabelle.
Was mein Code machen soll:
- startmatrix * quantisierungstabellenmatrix
- iDCT für die neue Matrix
- +128 um die Werte zu rekonstruierenBuch Beschreibung:
"Die Quantisierungssymbole und die durch IDCT und Addition von 128 rekonstruierten Werte sind nachfolgend aufgelistet."
Mein Code:
#include <iostream> #include <cmath> #define PI (4*atan(1)) //definition von PI #define sqt 0.70711 //definition von 1/sqrt(2) //hilfs funktion double clckwert(int wert){ if(wert == 0){ return sqt; }else{ return 1; } } //hilfs funktion double coswert(int x, int k){ return cos((((2*x)+1)*k*PI)/16); } int main(){ int startmatrix[8][8] = {{-24,-17, 2, 1, 1,-1, 0, 0}, {-13, 7, 2,-3, 0, 0, 0, 0}, { 0, 2,-4, 1, 1, 0, 0, 0}, { 0, 0, 0, 2,-2,-1, 1, 1}, { 1, 0, 0,-1,-1, 2,-1,-1}, { 0, 0, 1,-1, 0,-1,-1, 1}, { 1, 0, 0,-1, 1,-1, 0, 0}, { 0, 0, 1, 0, 0,-1, 1,-1}}; //quantisierungs Tabelle int quantmatrix2[8][8] = {{20, 30, 40,50,50,50,50,50}, { 31, 41, 50,50,50,50,50,50}, { 42, 50, 50,50,50,50,50,50}, { 50, 50, 50,50,50,50,50,50}, { 50, 50, 50,50,50,50,50,50}, { 50, 50, 50,50,50,50,50,50}, { 50, 50, 50,50,50,50,50,50}, { 50, 50, 50,50,50,50,50,50}}; int buffmatrix[8][8]; int erg = 0; int ergmatrix[8][8]; for(int i = 0; i<8; ++i){ std::cerr << '\n';// damit die ausgabe in einem 8x8 block passiert for(int j = 0; j<8; ++j){ ergmatrix[i][j] = 0; startmatrix[i][j] = (startmatrix[i][j]*quantmatrix2[i][j]); //quantisierung for(int k = 0; k<8; ++k){ for(int l = 0; l<8; ++l){ buffmatrix[k][l] = 0.25*(clckwert(k)*clckwert(l)*startmatrix[k][l]*(coswert(i, k)*coswert(j, l)));//iDCT erg = erg + buffmatrix[k][l]; //iDCT wert in erg speichern und vorherigen iDCT wert addieren }//l }//k erg += 128; ergmatrix[i][j] = erg; // erg in ergebnismatrix speichern std::cerr << ergmatrix[i][j] << " ";//ausgabe erg = 0; }//j }//i }Hier noch mal die Formel der iDCT Formel
P.S.: Irgendwas muss ich noch falsch machen, da im Buch als Ergebnis das hier steht:
0 32 27 0 13 0 0 23 0 0 0 0 9 15 0 15 1 18 0 1 15 0 11 243 0 18 0 25 0 6 219 214 18 7 0 0 13 218 211 231 9 0 10 0 213 228 205 232 7 0 0 15 227 245 202 220 7 0 12 240 241 253 240 209Meine Matrix sieht so aus:
65 -7 11 32 80 114 131 169 -56 -10 -35 -17 -17 -13 27 99 -3 -4 -16 -16 -1 27 80 149 3 8 -12 -19 16 57 153 237 15 18 0 -23 63 161 238 233 14 0 -1 -37 177 245 194 217 -6 3 -2 27 241 229 212 207 6 -19 12 233 235 254 241 211Nicht gleich aber die Werte werden von oben links nach unten rechts größer.

Vielleicht hat ja noch wer mal ein Tipp was da schief gehen könnte.(Am Ende wird noch im Buch erwähnt: "Entsprechend den JFIF-Vorgaben müssen Cb- Cr-Komponente überabgetastet und interpoliert werden. Die Transformation von YCbCr- in den RGB-Farbraum schließt die Verarbeitung ab."
Also wurden diese schritte noch nicht gemacht. Brauche ich also auf meine Matrix noch nicht anwenden. Also so hab ich das verstanden.)
-
Wofür brauchst du "buffmatrix"?
"erg" sollte vermutlich eindoublesein.
Und es gibt viel schnellere iDCT Algorithmen (O(N log N) statt O(N²)).ps
überabgetastet
Manche Leute übertreibens echt. Man muss nicht immer alles 1:1 auf Deutsch übersetzen.
-
hustbaer schrieb:
Wofür brauchst du "buffmatrix"?
Ja ist unnötig hast recht.
hustbaer schrieb:
"erg" sollte vermutlich ein
doublesein.Ja obwohl es nicht viel am Ergebnis ändert.
hustbaer schrieb:
Und es gibt viel schnellere iDCT Algorithmen (O(N log N) statt O(N²)).
Da bin ich ehrlich gesagt nicht so gut. Könntest du das genau erklären oder mir einen Link mit genauer Erklärung geben?
")
Obwohl das ja nicht mein Problem behebt. Also das Ergebnis ist immer noch nicht richtig.hustbaer schrieb:
ps
überabgetastet
Manche Leute übertreibens echt. Man muss nicht immer alles 1:1 auf Deutsch übersetzen.
Ja...

-
Fuchs aus dem Wald schrieb:
hustbaer schrieb:
Wofür brauchst du "buffmatrix"?
Ja ist unnötig hast recht.
hustbaer schrieb:
"erg" sollte vermutlich ein
doublesein.Ja obwohl es nicht viel am Ergebnis ändert.
Hast du "buffmatrix" rausgenommen UND "erg" zu nem double gemacht?
So lange du über "buffmatrix" gehst kanns ja nicht stimmen, weil "buffmatrix" Integer ist, und damit Nachkommastellen vernichtet.Fuchs aus dem Wald schrieb:
hustbaer schrieb:
Und es gibt viel schnellere iDCT Algorithmen (O(N log N) statt O(N²)).
Da bin ich ehrlich gesagt nicht so gut. Könntest du das genau erklären oder mir einen Link mit genauer Erklärung geben?
Obwohl das ja nicht mein Problem behebt. Also das Ergebnis ist immer noch nicht richtig.Google mal nach "fast inverse dct", da solltest du einiges finden.
Diese "fast" Varianten von DCT, FFT etc. leitet man sich normalerweise nicht selbst her, das ist zu heftig. Die googelt man einfach, und übernimmt den fertigen Algorithmus.
Maximal dass man den dann noch linear optimiert, mit MMX, SSE oder was man halt auf der jeweiligen CPU zur Verfügung hat.BTW: es gibt auch Algorithmen die für 4x4 oder 8x8 (i)DCT mit Integer Berechnungen auskommen.
Google "inverse integer dct 8x8" oder so.
-
So Leute ich bin jetzt schon um einiges weiter.
Was ich schon hab:
- Huffman Tabelle anwenden (für DC und AC)
- iDCT
- DeQuantisierungWas mir noch fehlt:
- Überabtastung
- Interpolieren
- Farbraum UmrechnungMeine Frage(was ich ja am Anfang des Threads schon wissen wollte):
- Wenn ich jetzt die UmrechnungeN bis zum Farbraum Umrechnen gemacht habe. Was sind den nun Pixel?
- Beispiel:
Ich hab ein Array was 8x8 ist. Diese Werte speicher ich meinet wegen in einen Vector. Am ende habe ich dann alle umgerechneten Werte in dem Vector hintereinander.
Nehme ich dann die ersten drei Werte und das ist dann 1 Pixel? Sprich wert1 = Y wert2 = Cb wert3 = Cr? Dadraus wird dann --> wert1 = R wert2 = G wert3 = B? Und dann die nächsten 3?Oder kann ich die Umrechnung auch gleich für das 8x8 Array machen. Da habe ich irgendwie Verständnis Probleme.
-
In jedem 8x8 Array stehen immer nur Werte des selben Kanals.
Also entweder hast du 64 Y oder 64 Cb oder 64 Cr Werte.Ein 8x8 Y Block steht dabei normalerweise für 8x8 Pixel im Bild.
Und ein 8x8 Cb oder Cr Block steht dabei für 16x16 Pixel im Bild.D.h. du baust erstmal aus allen 8x8 Y Blöcken den gesamten Y Kanal zusammen (=über die volle Fälche des Bildes), aus allen Cb Blöcken den Cb Kanal und aus allen Cr Blöcken den Cr Kanal.
Dann verdoppelst du die Grösse der Cb und Cr Kanäle.Und dann kannst du YCbCr -> RGB umrechnen.
-
Wow danke. Man das sollte man ja eigentlich selber wissen. xD
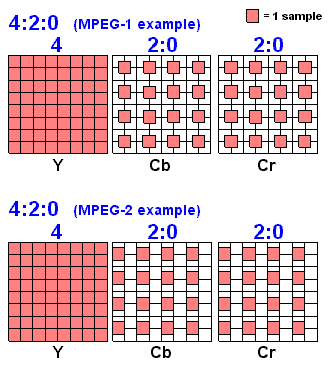
Also ich hab jetzt eine Abtast Form von 4:2:0
Würde das heißen ich muss Cb und Cr x4 nehmen?
Ich mein es sind ja immer 4 Y-Blöcke und jeweils ein Cb-Block udn Cr-Block.Gleich noch eine Frage:
- Was heißt verdoppeln der Größe? Aus einer 8x8 Matrix zwei gleiche 8x8 Matrizen?
-
Ne guck mal...
Jede 8x8 Matrix ist ein kleines 8x8 Rechteck aus dem vollständigen Bild.
Nur dass du nicht ein farbiges Bild hast, sondern 3 monochrome.
Je eins für Y, Cr und Cb.Das Y Bild hat sagen wir mal 256x256 Pixel, besteht also aus 32x32 Rechtcken von denen jedes 8x8 Pixel gross ist.
Die Cb und Cr Bilder sind nur 128x128 Pixel gross, bestehen also aus 16x16 Rechtcken von denen jedes 8x8 Pixel gross ist.Um zu einem farbigen Bild zu kommen musst du nun die Y, Cb und Cr Bilder übereinanderlegen. Die Cb und Cr Bilder sind aber zu klein, das heisst du musst sie vergrössern (Resamplen). Und zwar von 128x128 auf 256x256, also einfach Breite und Höhe verdoppeln.
Die einfachste Variante, die zum Testen erstmal reichen sollte, ist jeden Pixel einfach in ein 2x2 Quadrat mit genau dieser Farbe zu verwandeln.Ein Set aus 4 Y Blöcken + je einem Cb und Cr Block enthält also die Informationen die nötig sind um ein 16x16 Rechteck des original Bildes zu rekonstruieren.
Wobei ich es wie gesagt nicht auf Block-Ebene machen würde, sondern erst das gesamte "Y Bild", das gesamte "Cb Bild" und das gesamte "Cr Bild" aufbauen, dann die Cb und Cr "Bilder" vergrössern, und dann YCbCr -> RGB konvertieren.
-
Vielen dank.
D.h. also das wenn ich ein 128x128 auf 256x256 vergrößer, ist das sozusagen noch mal ein 128x128 dazu aber leeres? Wie hier zu sehen ist im oberen Teil.
-
Fuchs aus dem Wald schrieb:
Vielen dank.
D.h. also das wenn ich ein 128x128 auf 256x256 vergrößer, ist das sozusagen noch mal ein 128x128 dazu aber leeres?
Den Satz versteh ich nicht. Muss man aber glaub ich auch nicht verstehen.
Wie hier zu sehen ist im oberen Teil.
Ja.
Du sollst einfach dasABCDEFGH 12345678 ........in das verwandeln:
AABBCCDDEEFFGGHH AABBCCDDEEFFGGHH 1122334455667788 1122334455667788 ................ ................Ich versteh nicht was daran so schwer zu verstehen ist.
Aufblasen halt. Vergrössern. Grösser machen. Resampeln. Skalieren.
-
Ich dachte so:
ABCA B CAlso doch noch mal genau das gleiche wie ich es schon gesagt hatte dazu...
-
Hä?
Wenn A == 100 und B == 200, was ist dann " "?
-
Ja ich sag ich hab falsch gedacht. Aber hatte es erst richtig doch du hast mich noch mal verwirrt.
Aus einer 8x8 Matrix zwei gleiche 8x8 Matrizen?
Naja ich hab es jedenfalls verstanden. Danke dir.
-
Hat vielleicht noch jemand mal eine Idee wie ich das vergleichen der codewörter beschleunigen könnte?
void SCANS::huffsel(Huffman* keeper, const char* sos, int j){ bool up = true; Huffman* last = keeper; for(int k = 0; k<8; ++k){ for(int l = 0; l<8; ++l){ keeper = last; if( k != 0 && l != 0){ while(keeper){ up = huffcalc(keeper, sos, j); if(up){ if(keeper->rle){ helper(k, l); } matrixBuff[k][l] = keeper->category; keeper = 0; }else{ keeper = keeper->next; }//else }//while ++j; }//if }//l }//k }bool SCANS::huffcalc(Huffman* keeper, const char* sos, int j){ uint16_t buff = 0; buff = (uint8_t)sos[j] & BITMASK; if(buff == keeper->codeword){ return true; }else{ buff = (buff << 8) | (uint8_t)sos[j+1]; for(int o = 0; o<16; ++o){ if(buff == keeper->codeword){ return true; } if(buff == 0) { o = 16; } buff = buff >> 1; } return false; } }So wie es jetzt ist ruft huffsel() für jedes Codewort huffcalc() auf. Und zwar für jede Stelle an der ich grade bin wird die ganze Tabelle durchlaufen.
Macht mich ruhig fertig den es ist wirklich schrecklich lahm. (3milarden prozesse in der huffcalc())
EDIT:
Ach so hier noch der helper:void SCANS::helper(int &k, int &l){ int counter = 0; for(int k; k<8; ++k){ for(int l; l<8; ++l){ if(keeper->rle == counter){ return; }else{ matrixBuff[k][l] = 0; ++counter; }//if }//l }//k }
-
Huffman Dekodierung ist ja nicht JPEG-spezifisch, da findest du genug Infos im Netz.
Auch was die Üblichen Optimierungen angeht.Im Prinzip kannst du hergehen und Tables aufbauen wo du für alle möglichen N-Bit Kombinationen abspeicherst:
* Ja, für diese Kombination gibt es komplettes Codewort das mit den ersten Bit M Bits der Kombination anfängt
oder
* Nein, es gibt kein komplettes Codewort das mit den ersten Bit M Bits der Kombination anfängtGanz grob skizziert:
HuffmanInputStream h; int codeLengthTable[1024] = {}; //... // h Initialisieren, codeLengthTable anfüllen //... while (h.remainingBitCount >= 10) { int v = h.first10Bits; int codeLength = codeLengthTable[v]; if (codeLength == 0) { // Mist, langsame Variante // ... // ... } else { // Hui, getroffen // 'codeLength' Bits aus 'v' rausnehmen und damit // das auszugebende Symbol nachschlagen h.ConsumeBits(codeLength); } } while (h.remainingBitCount >= 10) { // Langsame Variante }Also wenn z.B. "10" ein Code ist, dann füllst du alle 256 Einträge in codeLengthTable die mit "10" anfangen mit 2.
Das auszugebende Symbol schlägst du natürlich auch in einem Table nach.
Dadurch musst du für die häufigsten Symbole schonmal den Baum nicht durchgehen. Bits rumschieben muss man natürlich immer noch.Das lässt sich vermutlich auch über Tables optimieren, aber da ich das selbst noch nie gemacht habe, und es wie gesagt genügend Material dazu online geben sollte... darfst du das selbst nachlesen.
{kind=link}
{kind=link}