Daten von der Grafikkarte zurück an den Hauptprozessor senden
-
Naja, mir würden noch einige Sachen einfallen, die du ausprobieren könntest (Pixelshader, Viewport, Renderstates checken etc.), aber am auffälligsten find ich folgendes:
1. Meiner Meinung nach ergibt deine Farbangabe nach wir vor keinen Sinn. Du sagst der Pipeline, dass deine Farben als ubyte4 vorliegen, aber definierst sie per float. Definier doch auch deine Farben so, wie du es in der VertexDecl beschreibst.2. Vermutlich sollen deine Vertexpositionen Screenspace Positionen darstellen, oder? Das ergibt aber wenig Sinn, da du einen Pass through VS hast und die Pipeline erwartet, dass die Positionen, die aus dem VS rauskommen, im Projection Space sind (-w <= x,y <= w und 0 <= z <= w). Diese Positionen werden dann noch dividiert durch w (bei dir egal, da die alle 1 sind) und dann noch durchs Viewport Mapping gejagt, was Müll ergibt.
Versuch es mal mit Vertices, deren Positionen bereits im Clip Space sind, also z.B. sowas:float arrVt[3][5] = { {0.0f, 0.0f, 0.0f, 1.0f, 0xFF0000FF}, {0.0f, 0.5f, 0.0f, 1.0f, 0xFF0000FF}, {0.5f, 0.0f, 0.0f, 1.0f, 0xFF0000FF}}
-
Ja jetzt rendert er tatsächlich etwas! Yuhuuuu!
")
Aber jetzt noch mal zum mitschreiben...
Pipeline erwartet, dass die Positionen, die aus dem VS rauskommen, im Projection Space sind (-w <= x,y <= w und 0 <= z <= w).
Siehst du, genau da liegt mein Problem! Woher weisst du das? In der offiziellen Referenz von Microsoft steht folgendes geschrieben:
oPos Position Register FERTIG!
http://msdn.microsoft.com/en-us/library/bb172960(VS.85).aspxIch habe ein Buch neben mir liegen, dass fast ausschliesslich von Vertexshadern und Pixelshadern handelt und da steht folgendes geschrieben:
Zitat:
The position data must be in transformed homogeneous screen coordinates, or you don't see anything on the screen.
Kannst du mir eine gute Resource angeben, wo genau beschrieben wird, wie die Programmable Rendering Pipeline aufgebaut ist, wie sie funktioniert und in welcher Form die Parameter vorliegen müssen?
PS.
Ich habe für die Farbe float verwendet, weil es meiner Meinung nach für die Problemlösung irrelevant ist, ich meine 0.0f hat das bitmuster 00000000.....$
ob ich das nun als float oder DWORD oder UINT oder int oder was auch immer definiere.. (Ich kenne Assembler relativ gut, denke ich
-
Ishildur schrieb:
Siehst du, genau da liegt mein Problem! Woher weisst du das? In der offiziellen Referenz von Microsoft steht folgendes geschrieben:
Meiner Meinung nach sind die DX Dokus eher mäßig und verdienen eigentlich auch nicht die Bezeichnung Doku. IMO ist es eher eine Referenz für Leute, die schon Erfahrung mit 3D-Programmierung/DX haben. Das gilt für die DX10 Doku noch mehr als für die DX9 Doku...
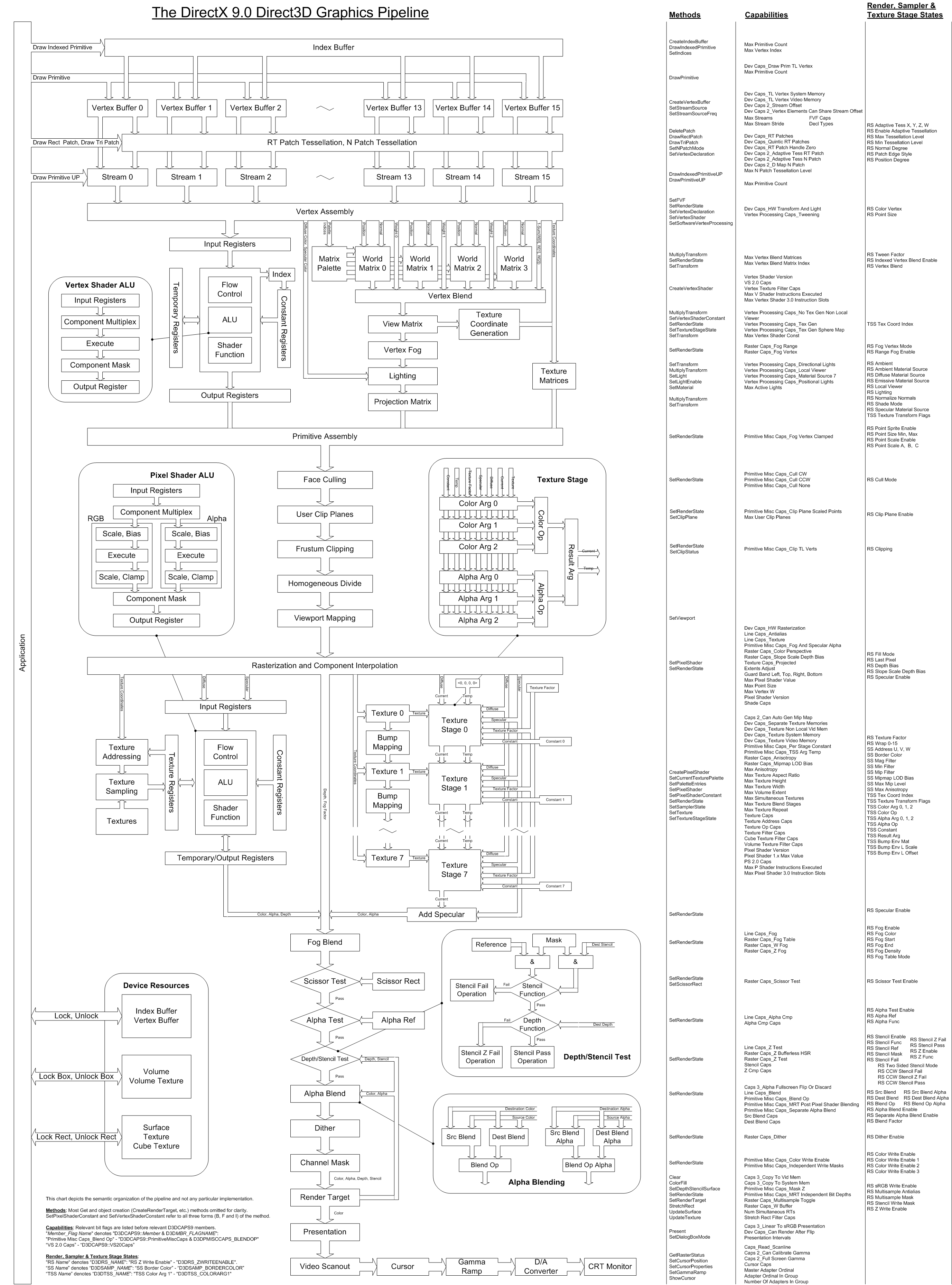
Ich kenne leider auch keine guten Tutorials, die die DX Pipeline beschreiben. Ich habe mir mehrere kleinere Artikel/Tutorials ergoogelt und daraus dann versucht ein Gesamtbild zu bauen. Ziemlich hilfreich fand ich dieses Poster: http://www.xmission.com/~legalize/book/preview/poster/pipeline-9.0.png
The position data must be in transformed homogeneous screen coordinates, or you don't see anything on the screen.
In welchem Kontext steht das? Meistens (leider wird nicht immer die gleiche Terminologie verwendet) bezeichnet man mit den Screen Coordinates die finalen 2D Koordinaten im Rendertarget.
Ishildur schrieb:
Ich habe für die Farbe float verwendet, weil es meiner Meinung nach für die Problemlösung irrelevant ist, ich meine 0.0f hat das bitmuster 00000000.....$
Das Bitmuster von 0.0f muss NICHT zwangsläufig aus lauter Nullern bestehen. Und selbst wenn es so wäre, finde ich es einfach unschön völlig grundlos einen anderen Datentyp anzugeben, weil vielleicht das Bitmuster uminterpretiert auch stimmen könnte. Aber naja, ist ja dein Code;)
-
bezeichnet man mit den Screen Coordinates die finalen 2D Koordinaten im Rendertarget.
Ja, aber was bedeutet das? Wo ist der Koordinatenursprung und wie sieht die skalierung aus.
Wo ist x=0,y=0 ? Am linken oberen Rand? am linken unteren Rand? in der Mitte?
Welche Position is ganz rechts? Ist es abhänging von der Auflösung des Rendertargets? Ist es von 0.0f - 1.0f ? von -1.0f - 1.0f oder 0.0f - 640.0fDas sind alles Fragen, auf die ich nirgends eine Antwort finde...

-
Damit die ganzen Transformationen (Projektion etc.) unabhängig von der konkreten Auflösung des Rendertargets (z.B. 800x600 sind), verwendet man sog. Normalized Device Coordinates (Koordinaten im Normalized Device Space).
Nach der Projektionstransformation (+ Homogenen Division) befinden sich die Positionen in diesem Normalized Device Space. In OpenGL ist das ein Einheitswürfel [-1,1]^3 und in DX sieht der genauso aus, nur das die z-Achse von 0 bis 1 geht, anstatt von -1 bis 1. Das kannst du dir einfach als relative Koordinaten vorstellen: (1,1) ist ganz oben rechts im finalen Bild und (-1,-1) ganz links unten. Um nun konkrete Pixelkoordinaten zu erzeugen (also eine Transformation vom NDS => Screenspace), verwendet man das Viewport Mapping. Das ist im Grunde nur eine Translation (da der Ursprung des NDS im Zentrum liegt und der Ursprung im Screen Space in einer Ecke; meistens links oben) + Skalierung (um eben die 2x2 Fläche auf die absolute Größe (z.B. 800x600) zu skalieren) sowie eine Spiegelung entlang der y-Achse (da im NDS die y-Koordinate nach obne zeigt aber im Screenspace für gewöhnlich nach unten). Der Ursprung (0,0) des Screenspace ist also oben links und bei einem 800x600 Rendertarget wäre der Pixel rechts unten (799,599).
-
Hehe, was du alles weisst!
")
Ich glaube, ich habe alles verstanden, bis auf diese Homogenität. Ich dachte, um ein Bild zu rastern, müssen die x sowie die y koordinaten eines Positionsvektor durch die z koordinate dividiert werden? Aber wofür braucht es dann nocht w? Welchen Zweck erfüllt es?Ach ja, eines noch. Wo findet dieses Mapping statt? Offenbar nicht im Vertexshader, sondern erst hinterher vom Rasterizer?
Mein Problem ist, dass ich ja die Daten wieder aus dem Rendertarget rauslesen will und ich dachte mir, der 1ste Pixel ist das Resultat der ersten Berchnung, der zweiter Pixel das Resultat der 2ten Berechnung usw.
Auf diese Weise kann ich ja aber nie genau wissen, an welcher Position im Rendertarget denn nun mein Punkt des Vertex liegt, oder sehe ich das falsch?
-
Ishildur schrieb:
Ich dachte, um ein Bild zu rastern, müssen die x sowie die y koordinaten eines Positionsvektor durch die z koordinate dividiert werden? Aber wofür braucht es dann nocht w? Welchen Zweck erfüllt es?
Genau diesen;) Wenn du einen Vektor v=(x,y,z,1) im View Space mit der Projektionsmatrix transformierst, ergibt das einen Vektor v'z=(x'z, y'z, z'z, z) im Projection Space. Schau dir mal die Matrix an, die D3DXMatrixPerspectiveFovLH ( http://msdn.microsoft.com/en-us/library/bb205350(VS.85).aspx ) liefert. Der letzte Spaltenvektor ist (0,0,1,0)^T, ergo wird w von v' lediglich auf z gesetzt. Bei der perspektivischen Division (alias Homogeneous Division) wird nun durch w geteilt (sprich: durch z), um aus v'z Vektor v' zu machen.
Ishildur schrieb:
Ach ja, eines noch. Wo findet dieses Mapping statt? Offenbar nicht im Vertexshader, sondern erst hinterher vom Rasterizer?
Nach dem VS und vor dem Triangle Setup (also auch vorm PS).
Ishildur schrieb:
Mein Problem ist, dass ich ja die Daten wieder aus dem Rendertarget rauslesen will und ich dachte mir, der 1ste Pixel ist das Resultat der ersten Berchnung, der zweiter Pixel das Resultat der 2ten Berechnung usw.
Was meinst du genau mit "Berechnung"? Der Pixelshader wird für jedes Fragment eines sichtbaren Polygons aufgerufen.
-
Auf diese Weise kann ich ja aber nie genau wissen, an welcher Position im Rendertarget denn nun mein Punkt des Vertex liegt, oder sehe ich das falsch?
Du beschreibst einen Teilbereich eines 2D-Arrays (Framebuffer) indem Du diesen mit einem Polygon fuellst - die Vertexpositionen legen also lediglich das Ausmass dieses Bereiches fest. Die eigentlichen zur Berechnung notwendigen Parameter musst Du zb als zusaetzliche Vertexattribute bereitstellen.
Es nuetzt Dir ja nichts eine Berechnung durchzufuehren deren Ergebnis dann an einer unbekannten Speicherstelle abgelegt wird...
-
@hellihjb
Zwei fragen:
1. Als welchen D3DDECLUSAGE soll ich meine "zusätzlichen" Daten deklarieren?
2. Wie kann ich im Vertex Shader definieren, welchen Wert im Pixel 0,0 des Rendertargets gespeichert wird? Ist dies überhaupt möglich? Wenn nicht, wäre es möglicherweise mit dem Pixelshader möglich?
-
Ishildur schrieb:
1. Als welchen D3DDECLUSAGE soll ich meine "zusätzlichen" Daten deklarieren?
D3DDECLUSAGE_TEXCOORD
Ishildur schrieb:
2. Wie kann ich im Vertex Shader definieren, welchen Wert im Pixel 0,0 des Rendertargets gespeichert wird? Ist dies überhaupt möglich? Wenn nicht, wäre es möglicherweise mit dem Pixelshader möglich?
Das machst du indirekt über die Vertexattribute, die dann über das Polygon interpoliert werden. Wenn du ein Rechteck definierst mit einer Position und Farbe, wobei die oberen 2 Eckpunkte grün sind und die unteren rot, dann wird im Rechteck von oben nach unten von grün nach rot interpoliert.
Wenn du beliebige Eingabewerte verarbeiten willst, kannst du die einfach in einer Textur speichern und dann im PS auslesen/samplen.
{kind=link}