Intel Software Conference 2010 (Teil IV)
-
Intel ISTEP 2010 Software Conference: Barcelona April 13th

Wie jedes Jahr lud Intel auch in 2010 zur Software Conference ein, die diesmal in Barcelona stattfand. Wie bereits 2009 stand alles im Zeichen der Parallelisierung.
In dieser kleinen Artikelserie fasse ich einige Vorträge zusammen, soweit die Themen für die Programmierung mit C++ von Relevanz sein könnten.
Don’t Assume Programming for Multicore Is Easy
 David Norfolk, Practice Leader Development and Governance, Bloor Research
David Norfolk, Practice Leader Development and Governance, Bloor Research*Nothing makes you sadder than buying a new top-of-the-range PC and discovering that your apps run more slowly. But that’s what may happen soon if your new powerhouse gets its power from slower, more energy-efficient chips running in parallel and your applications only run on one chip for much of the time. This is a real issue for developers because there is no automatic way to turn an application optimized for a single CPU into one optimized for a multiprocessor. There are several solutions, each with its own problems.
Split out parts of the program (e.g., graphics) to run on another processor. It probably works now with four or nine processors, but doesn’t scale well; if you have 128 or 256 processors, your program may not split into that many parts. Use a framework such Pervasive Datarush, which is inherently parallelizable and doesn’t require the programmer to understand parallel programming. This works well, but only for a certain class of application. Use Intel
 tools to rewrite programs so that they parallelize well. This works for new programs, although there is the rewriting overhead for legacy; the devil may be in the regression testing of the application ― have you changed its behavior? And this is really only suitable for skilled programmers. Think about buying packaged applications known to run well on parallel architectures. This is great if you don’t mind making programmers redundant and can find packaged apps that meet your requirements, more or less, out of the box (customizing packaged apps is very expensive).
tools to rewrite programs so that they parallelize well. This works for new programs, although there is the rewriting overhead for legacy; the devil may be in the regression testing of the application ― have you changed its behavior? And this is really only suitable for skilled programmers. Think about buying packaged applications known to run well on parallel architectures. This is great if you don’t mind making programmers redundant and can find packaged apps that meet your requirements, more or less, out of the box (customizing packaged apps is very expensive).Whatever approach you take, it is vital that you have tools that help you visualize exactly how your applications behave on parallel architectures. Well-written legacy apps, built from small components with maximum cohesion and minimal coupling, may parallelize well enough. If they’re slow, perhaps something else is wrong. But note that an application written with the latest tools to exploit parallel architectures may only run on a single CPU for much of its execution due to a non-obvious programming error. The brave new world of multiprocessor architectures hasn't changed everything we know about programming, and if you want to optimize anything, it is essential that you first find out where the real bottlenecks are before you jump in and waste time optimizing the wrong stuff. You need tools to help you visualize the way your program actually turns on a multicore architecture. That said, soon the only place you'll be able to find a (virtual) high-speed, single-processor PC is on the latest generation z series mainframe. You can’t buy single-core PCs anymore, and if you want to sell applications, they’ll have to use multicore efficiently. This doesn’t mean coding for four or eight cores, but rather coding for as many cores as might be available. Think in terms of 512 or 1024 cores or more if you don’t want to build in early obsolescence. Now, the compiler can’t do this for you; you have to think parallel, which means taking good practice seriously and getting yourself some training. Don’t assume programming for multicore is easy - it isn’t. It comes with interesting new bugs (e.g., race conditions and deadlocks), which often don’t show up in lightly loaded test environments. So, get the best tools you can, including those to help you visualize the counter-intuitive ways programs often run on multicore architectures.*
Für David Norfolk heißt Thinking Parallel:
- Man sollte nicht in neuen Limits denken, also wieso setzt man bereits wieder Limits wie Quadcore? Besser man setzt gleich das Limit auf n Kerne.
- Verlassen Sie sich nicht auf den Compiler.
- Komponenten, die klein und zusammenhängend sind, und nur geringe Kopplung zu anderen Komponenten besitzen, helfen bei der parallelen Optimierung.
Allerdings sollte man – sozusagen in der anti-parallelen Denkweise – auch bedenken, dass es sehr viele Single-Prozessor-Applikationen in der Welt gibt und die Migration könnte oftmals schwieriger sein als alles gleich neu zu schreiben.
Im Allgemeinen haben zur Zeit neue PCs einen geringeren Geschwindigkeitszuwachs als früher, was dazu führen kann, dass vorhandene Applikationen auf neuen Systemen langsamer laufen.
Weiterhin können bei Multithreading-Applikationen seltsame Fehler oder Laufzeitverhalten auftreten, unter Last, wie Deadlocks oder Race Conditions. Und das, obwohl Tests vorher fehlerfrei waren. Das reine Mitschreiben von Datenlogs – wie in der Vergangenheit – reicht nicht mehr zwangsläufig aus um Fehler zu reproduzieren. Die Lastbedingungen und die konkrete Verteilung der Bearbeitung auf die Kerne zum Zeitpunkt eines Fehlers ist ebenso wichtig.
Außer den Schwierigkeiten gibt es natürlich auch Vorteile: Multicore erlaubt eine bessere Energieausnutzung, oder kann auch die GUI-Erlebnisse der User verbessern, wenn sich ein Core um die "elegante" Darstellung kümmert, während der Rest arbeitet.
Bei der Toolauswahl sind visuelle Darstellungen wichtig, die Abläufe und Verteilungen entsprechend visualisieren. Die Informationen sind zu komplex, um nur mit Zahlen oder Codezeilen dargestellt zu werden. Eine optische Darstellung des Prozessflusses und dessen Verteilung auf die Cores und Threads erlaubt es den Überblick zu behalten.
Eine konkrete Warnung hat David: ein Programm sollte erst funktionieren (in der seriellen Form), bevor man parallelisiert – und für die serielle Version sollte eine Zeitmessung existieren, um konkrete Verbesserungen der Parallelisierung überhaupt beurteilen zu können.
Die üblichen Ratschläge zur verfrühten Optimierung gelten bei der Parallelisierung also erst recht, man sollte nicht zu früh optimieren, und nur dort wo es auch hängt, aber nicht aus Spaß, Interesse oder der Fehlannahme "hier könnte es eng werden".
Eigentlich sind das keine neuen Ratschläge, aber bisher konnte man sich als Programmierer es oft erlauben das zu ignorieren, nur in Zukunft – so sieht das David Norfolk – wird die zusätzliche Fehlerdimension der Parallelisierung in diesen Fällen dem Programmierer das Genick brechen.
Pragmatic Multithreading
 Alexandre Jenny, Founder and CEO, Kolor
Alexandre Jenny, Founder and CEO, KolorThe free lunch is over. As a developer, you don’t get any more speed up of your code with the new CPU generation, at least not as much as before. Today, you need to cope with multithreading. In our image stitching products, we are using multithreading patterns since the first version. Nothing is really simple in this area, but with some guidelines, you can manage to create some good solutions which are practical and usable. You'll see which guidelines we use, how we applied them in our product and what the results are.
Alexandre Jenny, der CEO der Firma Kolor, stellte einige Fallbeispiele für konkrete Optimierung an realen Produkten seiner Firma vor. Kolor entwickelt Software ("AutoPano") für Foto-Stitching. Stitching benötigt außer Bildverarbeitung auch Matrixoperationen, Strukturanalyse und große Vektoren und ist damit sehr rechenaufwendig, vor allem auch wenn Bilder nicht mehr komplett in den Speicher passen.
Um Parallelisierung einzuführen, hat Kolor einige Multithreading Guidelines aufgestellt (die sich kontinuierlich weiterentwickeln):
- KISS 1: falls es bereits eine Multithreading-Version der benötigten Funktion von Intel gibt, dann diese benutzen (z.B. IPP).
- KISS 2: Falls Intel einen Compiler hat, zumindest ausprobieren.
- KISS 3: Jetzt wird es Zeit am Code zu arbeiten
Für mathematische Berechnungen wird MKL in der Multithreading-Version benutzt und Intel IPP für Bildtransformationen (ohne Multithreading, da die Zerlegung bereits auf der oberen Ebene Applikationsebene durchgeführt wird). Für die Überprüfung der Skalierung werden Intel Thread Checker und Profiler benutzt.
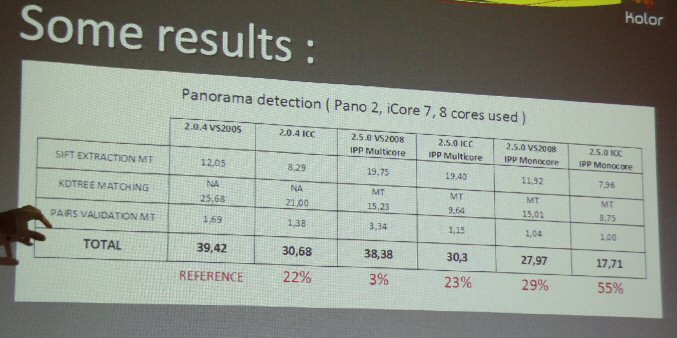
Wie man bereits sehen kann, beschleunigt bereits die Verwendung des Intel Compilers das Programm um 22%, nur durch reine erneute Compilierung. Bei 64 Bit ist der Unterschied sogar noch deutlicher.

Kolor hat als besonders eindrucksvolle Demonstration ihrer Fotostitching-Algorithmen das Projekt "Paris in 26 Gigapixel" als Benchmark ausgewählt, mit mehr als 2346 Einzelbildern, die mit einer Roboterkamera aufgenommen wurden. Die Demonstration und das "reinzoomen" aus der Totale bis auf einzelne Gesichter hat einiges an "A" und "O" im Zuschauerraum hervorgerufen.

Eine Flash-Demo ist online unter
http://www.paris-26-gigapixels.com
zu finden.