Microsoft tech ed 2010 in Berlin - Tag 1
-
Microsoft tech ed 2010 in Berlin
Die tech ed begann schon am Montag, 08.11.2010, ich konnte leider erst am Mittwoch anreisen, der Terminkalender hat es nicht anders erlaubt.

Tag 1 – Mittwoch, 10.11.2010
Zusammenfassung
DEV305 –Introducing Parallel Programming with .NET 4.0. Why is it important and how to get started!
Die Unterstützung paralleler Programmierung in .NET 4.0.
WCL302 - The Black Art of Fixing Busted Applications Part 1: Win32 App Compat
Warum laufen ältere Applikationen oftmals nicht unter Windows 7 und wie löst man das Problem?
DPR201 – IS - An Agile Talk on Agility
Eine erste Einführung in Agile Softwareentwicklung am Beispiel eines nach agilen Grundsätzen aufgebauten Vortrags.
WCL322 - The Windows API Code Pack – add Windows 7 features to your application
Laufbalken im Taskbar? Sich selbst neu startende Applikationen unter Windows 7? Dazu verwendet man den Windows API Code Pack.
Einleitung
Zur Microsoft tech ed – es handelt sich hierbei um eine einwöchige Konferenz, die jährlich in Europa, Asien, USA, Afrika und anderen Orten veranstaltet wird. Die Veranstaltung ist stark besucht, und es gibt eine schier unglaubliche Anzahl an Vorträgen, Workshops, Laboren, zu allen bekannten und weniger bekannten Microsoft Technologien und Produkten.
Die Organisation ist hervorragend, alles beschildert, organisiert, an jeder Ecke stehen Getränke und Essen, selbst das WLAN hält der Unzahl an eingeloggten Teilnehmern einigermaßen stand – siehe dazu auch die Fotos. Eine Herausforderung für jeden Administrator... lustige Bemerkung am Rande, dies ist vermutlich eine der wenigen Veranstaltungen, wo bei den Herren-Toiletten in den Pausen eine längere Schlange ansteht als an den Damen-Toiletten.
Sehr lobenswert ist das Zeitmanagement der Referenten – jeder Vortrag begann pünktlich auf die Minute, und endete pünktlich auf die Minute. Es gab keinerlei Überziehungen. Falls die Organisatoren die Referenten teilweise gebremst haben, hat man davon wirklich nichts gemerkt.
Nicht näher zugeordnete Fotos zu der Veranstaltung findet Ihr unter http://www.c-plusplus.net/misc/teched2010 .
DEV305 –Introducing Parallel Programming with .NET 4.0. Why is it important and how to get started!
Mario Szpuszta, Senior Architect Microsoft Corporation
Warum brauchen wir überhaupt Parallel-Programmierung?
 Die Einleitungsfolie greift einen Satz auf, den man schon vor einiger Zeit von Herb Sutter hören konnte: “The free lunch is over”. Darunter ist zu verstehen, daß heutzutage neue CPUs nicht mehr automatisch zu schnelleren Programmen führen, wie man das noch bis vor einigen Jahren gewohnt war. Damals ging das nach dem Prinzip „Programm zu langsam – schnellere CPU!“. Durch die Multi- und Many-Core-Architekturen der CPUs funktioniert dieses Prinzip nicht mehr so zwangsläufig, eine Applikation wird nur dann schneller, wenn sie wirklich alle Kerne und Parallel-Features der CPU ausnutzt. Wie man dies mit .NET 4.0 programmiert, ist Thema von Marios Vortrag. Das Foto zeigt einen eindrucksvollen Screenshot einer solchen Maschine... das ist mehr als ein Duo-Core!
Die Einleitungsfolie greift einen Satz auf, den man schon vor einiger Zeit von Herb Sutter hören konnte: “The free lunch is over”. Darunter ist zu verstehen, daß heutzutage neue CPUs nicht mehr automatisch zu schnelleren Programmen führen, wie man das noch bis vor einigen Jahren gewohnt war. Damals ging das nach dem Prinzip „Programm zu langsam – schnellere CPU!“. Durch die Multi- und Many-Core-Architekturen der CPUs funktioniert dieses Prinzip nicht mehr so zwangsläufig, eine Applikation wird nur dann schneller, wenn sie wirklich alle Kerne und Parallel-Features der CPU ausnutzt. Wie man dies mit .NET 4.0 programmiert, ist Thema von Marios Vortrag. Das Foto zeigt einen eindrucksvollen Screenshot einer solchen Maschine... das ist mehr als ein Duo-Core!
Dazu auch: http://www.gotw.ca/publications/concurrency-ddj.htmDie im Vortrag vorgestellten Beispiele stammen alle aus dem Parallel Samples Framework:
http://code.msdn.microsoft.com/ParExtSamplesMario führte zunächst auf recht humorvolle Art und Weise das Codebeispiel „Sudoku“ in der Single- und Multithread-Variante aus, um den Zeitunterscheid deutlich zu machen.
Was sind die Voraussetzungen für den Anfang?
Wesentlich ist, daß man das Problem in getrennt bearbeitbare Arbeitspakete zerlegen kann. Die Kunst an der Sache ist, wie man das Problem in diese unabhängigen Teile zerlegt. Dafür gibt es letztlich zwei Ansätze:
Data Driven
Die Daten werden geteilt, und diese geteilten Daten werden jeweils in einem Job bearbeitet. In der realen Welt entspricht das dem Problem, daß ein Mitarbeiter die Rechnungen von A bis L bearbeitet, der andere die Rechnungen von M bis Z.Functional Splitting
Verschiedene Aufgaben werden jeweils in verschiedenen Jobs erledigt, eine Arbeitsteilung nach Einzeltätigkeiten. Ein Thread greift die Daten von der Datei ab, ein anderer Thread erledigt die Berechnungen.Dazu auch: https://computing.llnl.gov/tutorials/parallel_comp/
Welche Tools und Möglichkeiten haben wir?
Funktionale Sprachen haben aus ähnlichen Gründen ein Comeback, da diese Sprachen per Definition keine Variablenabhängigkeit haben. Dadurch vermeidet man typische Concurrency-Probleme bei der Parallel-Programmierung. Dies ist auch der Grund, warum Microsoft mit F# eine funktionale Sprache auf den Markt gebracht hat – es soll möglich sein auf der .NET-Plattform Programme mit funktionalen Sprachen zu realisieren und gleichzeitig auch die Effizienz von Multi-Core-Programmierung zu nutzen
Der ThreadPool
Der ThreadPool funktioniert nach dem Prinzip Fire-and-forget, der Programmierer muß sich selbsts darum kümmern, daß das Endergebnis synchronisiert ist.
Es ist zu beachten, daß die Aufteilung in Aufgaben einen Verwaltungsaufwand erzeugt, der ebenfalls bearbeitet werden muß. Bei einer zu starken Aufteilung nimmt der Verwaltungsaufwand stärker zu als der Gewinn durch die Aufteilung. Ob dies noch akzeptabel ist hängt ganz wesentlich vom Umfang der zu verarbeitenden Daten ab – und von den gemachten Zeitmessungen.
Das Programmbeispiel zeigt die Anwendung eines Thread-Pools, einschließlich einer Synchronisation mit Hilfe von
CountdownEvent.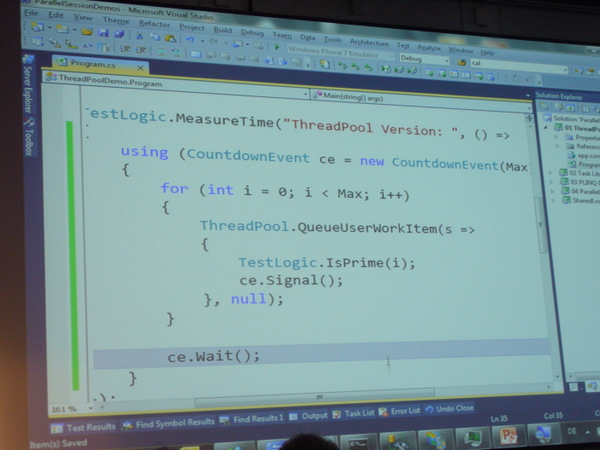
Lustigerweise war ein Programmfehler in der Demo, weswegen die Primzahlen nicht mehr korrekt berechnet wurden: Mario hat den Funktionen immer
iübergeben, so daß die Funktion jeweils mit dem Wert aufgerufen wurde, den diefor-Schleife gerade enthielt. Große Werte voniwurden gar nicht mehr bearbeitet, da diefor-Schleife schneller fertig war. Durch die Erzeugung einer lokalen Kopie voniin der Variableperzeugt das Programm dann den gewünschten Ablauf.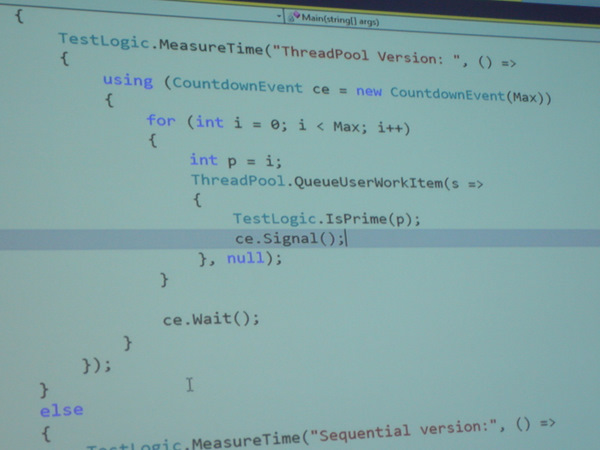
Das Problem in einer Anwendung wie hier ist, daß die Funktionen nicht gleiche Zeit benötigen, für große
pist die Berechnung langsamer.Die Task Parallel-Library
Als Beispiel nun die Verwendung der Task-Parallel-Library, wo mehrere Tasks miteinander verknüpft werden.
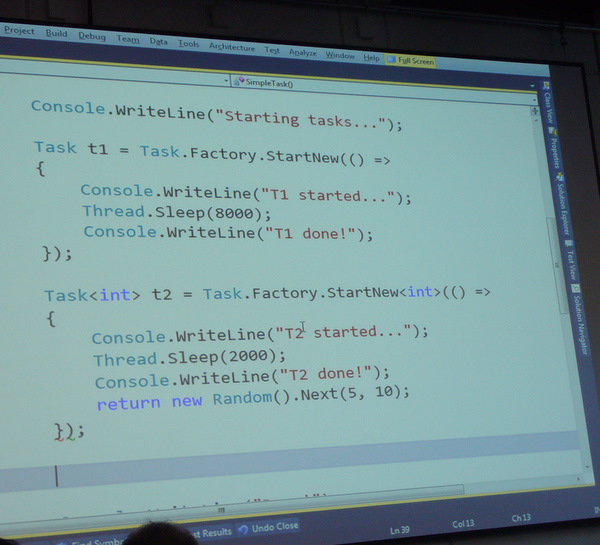

Der Task
t3startet erst, wennt2beendet ist und liefert dann dessen Ergebnis.Ein ThreadPool kann auch erschöpft sein, wenn die Anzahl der möglichen Tasks limitiert ist und die Jobs nie ihr Ende zurückmelden – das Programm bleibt dann defakto stehen.
Die Task Parallel Library gibt dagegen den Thread automatisch frei, wenn nichts mehr zu tun ist.
Parallele Schleifen
Parallel Loops sind ein weiteres Hilfsmittel für einfache Parallelisierung, wie
Parallel.For,Parallel.ForEachundParallel.Invoke. Diese haben den Vorteil, daß man sehr rasch erste Erfolge für einfache Anwendungen erzielt, als Programmierer muß man keinerlei Initialisierungen durchführen. Dafür sind auch die Anwendungsfälle beschränkt auf voneinander unabhängige Vorgänge, die idealerweise alle gleich lange dauern.Parallel.For(0, n, i=> { work(i); }); Parallel.ForEach(data, item=> { work(item); }); Parallel.Invoke( () => StatementA(), () => StatementB, () => StatementC());Parallel Language Integrated Query (PLINQ)
PLINQ ist ein weiterer Ansatz zur Parallelisierung. Dies wird erreicht durch eine Ergänzung von Attributen wie
AsParallel(), im einfachsten Fall.int[] output = arr .Select(x => Foo(x)) .ToArray(); int[] output = arr.AsParallel() .Select(x => Foo(x)) .ToArray();Die Logik der PLINQ-Abfrage muß bereits berücksichtigen, daß die Ausführung parallel ist, andernfalls wird z.B. bei einem Arraydurchlauf die Reihenfolge der Elemente nicht wie erwartet ausgegeben.
Tools zur Fehlersuche im parallelen Umfeld
Software funktioniert gewöhnlich immer, aber in gaaanz seltenen Fällen muß man auch nach Fehlern suchen. Im parallelen Umfeld wird dies nicht einfacher, da zusätzliche Fehlerquellen wie Synchronisation oder Deadlocks auftreten, zum anderen weil die Logik des Programms nicht für Parallelisierung geeignet sein kann. Im Visual Studio 2010 Professional oder Premium sind dafür die Sichten für Parallel Stacks – zeigt die Stacks der Threads grafisch an – und Parallel Tasks – zeigt den Status der Threads an – enthalten.
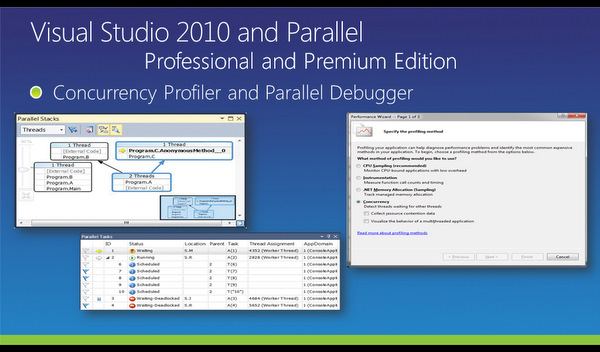
Man kann aus einem Task-Status heraus direkt in den Code an die Stelle springen, wo der entsprechende Task gerade wartet. Damit kann Code debuggt werden, der nicht Threadsafe sondern Threatsafe ist.
") Die Stelle zu finden, wo ein paralleles Programm „hängt“ – zum Beispiel auf eine fehlende Synchronisation oder einen Lock – ist eine Notwendigkeit bei dieser Art der Programmierung.
Die Stelle zu finden, wo ein paralleles Programm „hängt“ – zum Beispiel auf eine fehlende Synchronisation oder einen Lock – ist eine Notwendigkeit bei dieser Art der Programmierung.WCL302 - The Black Art of Fixing Busted Applications Part 1: Win32 App Compat
Chris Jackson, Principal Consultant Microsoft Corporation
http://www.appcompatguy.comChris besucht im Jahr ungefähr 40 Kunden, um deren Applikationen auf Schwierigkeiten mit dem jeweils neuesten Betriebssystem zu untersuchen – zur Zeit geht es also um Win32-Applikationen, die unter Windows 7 laufen sollen. Oftmals dann auch noch unter 64-Bit.
Die häufigsten Fragen zu 64-Bit, was läuft nicht?
- 16-Bit Binärdateien laufen nicht – es sind immer noch viele Bibliotheken und Programme im Umlauf, die von Kunden tatsächlich benutzt werden („solche Applikationen waren ihr Geld wirklich wert“).
- 32-Bit-Treiber verursachen immer noch Probleme, allerdings nicht mehr so oft wie unter Vista.
- Managed Code / InterOp verursacht interessanterweise ebenfalls Probleme, wenn die Binärdateien 32-Bit sind und das Gesamtprojekt als „run on any CPU“ compiliert wird.
- Pfadunterschiede - der kleine Unterschied mit
Program FilesundProgram Files (x86)– solche fest codierten Abhängigkeiten führen zu Problemen, man kann dies vermeiden wenn man die API für solche Aufgaben verwendet. Eigentlich kennt man diese Mahnung ja schon länger, offensichtlich ist sie aber immer noch nicht angekommen. Wann wurde das erstmalig als wichtig genannt? Ich glaube bei Win95...
Abgesehen davon sollten im Alltag wenige Probleme bei der Portierung auftreten – sagt Chris.
Was ist eigentlich mit VB6 (Visual Basic 6)?
Die IDE von VB6 läuft noch auf 64 Bit Win7 – trotz des Alters von 12 Jahren. Auf de MSDN-Seiten gibt es eine genaue Support-Anleitung, auch welche Binärdateien man heute mitliefern muß, falls man eine VB6-Applikation ausrollen will (oder muß). Früher waren die VB6-DLLs noch im Lieferumfang von Windows, darum muß man sich inzwischen aber selbst kümmern.
http://msdn.microsoft.com/en-us/vbasic/ms788708.aspx
Für die Dateien auf dieser Seite, die als „unsupported“ gelistet sind, gibt es teilweise keinen Quellcode mehr – es handelte sich um zugekauften Code von Fremdfirmen, die teilweise übernommen wurden oder pleite sind, und der Quellcode hat sich buchstäblich in Luft aufgelöst.
Fallbeispiele und typische Probleme in der Praxis
Ein Beispiel für solche Probleme: wenn ein Programm unter Admin-Level läuft, können Programme auf normalem User-Level keine Nachrichten schicken – dies ist aber bei einer Bildschirmtastatur notwendig. Solche Probleme ergeben sich durch die zunehmend stringentere Rechteverwaltung von Windows. In solchen Fällen muß zum Beispiel das Manifest angepasst werden, um den Zugriff zu erlauben.
Shims
Shims überbrücken viele Kompatibilitätsprobleme, es handelt sich hier letztlich um eine Übersetzung von bestimmten Aufrufen und Abläufen durch modifizierte Aufrufe und Parameter, um für ein bestimmtes Programm einen anderen Ablauf zu erzwingen.
Microsoft will mit den Shims das bereits seit Win 3.11-Zeiten bekannte Problem umschiffen, daß bestimmte Programme auf neuen Betriebssystemen nicht mehr laufen – bisher wurde dann in der API für bestimmte Anwendungen ein Workaround abgelegt, was auf Dauer schlechten Code mit zahlreichen Fallunterscheidungen erzeugt. Mit Shims kann das ausgelagert werden, die API verhält sich immer korrekt, und wenn eine bestimmte Applikation ein anderes Verhalten benötigt, kann man den Shim als „Puffer“ dazwischen schieben.
In einem weiteren Beispiel zeigte Chris eine Applikation, die scheinbar unter Win7 nicht mehr startete – der Process Monitor (von sysinternals) zeigt aber, daß die Applikation durchaus startet, aber ein Fehler durch falsche Rechte auftritt. Die Applikation hängt an dieser Stelle. Mit einem Shim und dem Compatibility Administrator kann in diesem Fall der Pfadzugriff umgebogen werden, so daß der Zugriff nicht mehr scheitert und die Applikation starten kann.
Weiterhin zeigte Chris, wie man mit dem Debugger Funktionsparameter eines API-Aufrufes herausfischt, es gibt dazu einen Blog-Beitrag von ihm.
http://blogs.msdn.com/b/cjacks/archive/2008/02/22/discovering-the-arguments-passed-to-windows-api-functions-with-public-symbols.aspxIn einem anderen Fallbeispiel wurde Chris zu einer großen Firma gerufen, weil bei einem Fenster der Applikation die Farben falsch waren. Nach einer Debug-Session stellte sich heraus, daß es der Monitor war – er war kaputt, und stellte eine Farbe falsch dar. Tja. Nicht immer ist Software verantwortlich.
Andere Probleme können dadurch entstehen, weil sich Titelfarben und Kontexte der Darstellung änderten – zum Beispiel war die Titelfensterschriftfarbe beim aktiven Fenster früher weiß, bei Win7 ist sie schwarz. Nimmt man nun diese Farbe und schreibt auf dunklem Hintergrund, ist der Text nicht mehr lesbar. Man könnte sowas natürlich lösen, indem man das Farbschema global(!) ändert wenn die eigene Applikation läuft – aber auch hier lässt sich mit einem Shim ein Zwischenpuffer realisieren, der die Farbkonstante modifiziert.
Zusammenfassung
Als wichtigstes Debugging-Tool für solche Fälle nannte Chris – den Webbrowser – denn die Suche nach verwandten oder ähnlichen Fehlerbildern ist der Einstieg um derartig verzwickte Probleme zu lösen. Oftmals sind die Lösungen gar nicht so schwierig, allerdings ist es nicht mehr trivial unter den vielen Möglichkeiten den richtigen Lösungsweg herauszuahnen.
DPR201 – IS - An Agile Talk on Agility
Peter Provost, Program Manager Visual Studio Microsoft Corporation
Aaron Bjork, Program Manager Team Foundation Server Microsoft Corporation
Mitch Lacey, Mitch Lacey & Associates, Inc.Im Gegensatz zu den Vorträgen handelt es sich hier um einen interaktiven Workshop, der auch die Teilnehmer einbezieht.
Zunächst die Definition einiger Begriffe, die zum Verständnis des Vortrags wichtig sind:
Story – eine Anforderung an das Projekt
Backlog – die Sammlung der Storys mit einer Priorisierung
Sprint – die Bearbeitung einer Menge von Stories innerhalb eines festgelegten ZeitintervallsDer Vortrag wurde in 4 Sprints zu 10 Minuten eingeteilt, die beiden Referenten hatten vom Vortag bereits ein Backlog mit wichtigen Fragen zu Agilen Methoden, die hier die Rolle der Storys spielten. Die Zuhörer des Vortrags konnten eine Story durch die Lautstärke des Klatschens priorisieren.
Die Story des 1. Sprints: Wann ist Agile falsch?
Agile heißt den Weg finden, ohne daß das Endprodukt exakt in allen Features feststeht. Aber auch bei komplett spezifizierten Projekten lohnt sich Agile, um die Dynamik der Methode zu nutzen. Wenn ganz genau feststeht was zu tun ist, und keine Änderungen zu erwarten sind, ist eine agile Methode Overkill. Je unschärfer die Spezifikation ist und je mehr Änderungen zu erwarten sind, desto sinnvoller sind agile Methoden.
Bei großen Projekten ist eine Mischform durchaus zu finden, wo „an der Spitze“ des Projekts klassisch mit dem Wasserfallmodell gearbeitet wird, aber die Teams ihre Aufgaben „agil“ erledigen.
In diesem Zusammenhang ein tolles Zitat von Peter „I am completely honest to my management when I lie to them!”
Nun beginnt der 2. Sprint, erneut mit einer Priorisierung der Storys. Als Teilnehmer bemerkt man bereits, daß die vielen Anfangsfragen unmöglich alle zu beantworten sind und man klatscht nur noch bei Themen, die einem wirklich wichtig sind.
Übrigens, alle Dinge, die nach dem 2. Sprint nicht wieder erwähnt wurden, werden aus dem Backlog gelöscht.
Der 2. Sprint - Wie geht man damit um, wenn einige Teammitglieder nicht zu 100% zum Team gehören?
Man kann die Mitglieder in ein Basis-Team teilen, das zu 100% am Projekt arbeitet, und die „Teilzeit“-Mitarbeiter werden zu Beratern, die nur zeitweise für spezielle Problemlösungen mitwirken. Besonders gut funktioniert das, wenn diese Mitglieder Expertenwissen zu bestimmten Themen besitzen.
Wenn Mitarbeiter abgezogen werden oder kurzfristig ausfallen, ändert sich ständig die Teamgeschwindigkeit. Dies ist unvermeidbar. Die daraus entstehenden Probleme kann man teilweise kompensieren, wenn man sicherstellt, daß jeweils die wichtigsten Aufgaben erledigt und tatsächlich abgeschlossen sind, bevor das nächste Thema bearbeitet wird. Auf diese Weise verringert man das Risiko, daß plötzlich viele Aufgaben unerledigt im Raum stehen.
Da die Planung ohnehin auf kurzfristige Zwischenziele abstellt ist es bei dringenden Problemen einfacher dieses Problem in den Backlog zu schieben und im Rahmen des Projekts in einem der nächsten Sprints zu bearbeiten. Weiterhin ist zu vermeiden, daß Teammitglieder über das Management oder andere operative Aufgaben (ein Problem an einem alten Produkt fixen) direkt angesteuert werden und plötzlich Aufgaben bearbeiten, die nicht im Backlog stehen. D.h. alle Aufgaben des Teams werden über das Backlog gesteuert.
Der Lerneffekt für die Teilnehmer war plakativ: es standen zu Beginn zwar 20 Fragen im Backlog, aber durch die Diskussion wurde pro Sprint bisher jeweils nur 1 Story bearbeitet. Aus dieser Teamgeschwindigkeit ergibt sich dann zur Mitte der Session auch die Erkenntnis, daß die Vortragenden letztlich nur 5-6 Fragen beantworten können in 40 Minuten.
Der 3. Sprint - Wie viel Architektur und Design soll am Anfang durchgeführt werden?
Nicht mehr als notwendig. Architektur wird nur soweit vorbereitet, daß die nächsten Ziele erreichbar sind. Bleibt die technische Fortsetzung an einer Architekturfrage stecken, wird die Architektur diesbezüglich im Team überarbeitet und sobald das Programm lösbar ist befasst man sich nicht mehr mit der Architektur. Es wird also nur konstruiert und geplant, was in den nächsten Sprints auch tatsächlich benutzt und benötigt wird. Es ist kein Widerspruch zur Agilen Methode, daß sich die ersten Sprints komplett nur mit Architektur und Design befassen.
Wie behandelt man geänderte Anforderungen während eines Sprints?
Die offizielle Antwort wäre, den Sprint abzubrechen und neu zu planen. Da dies aber der Normalfall ist, ist die praxisgerechtere Lösung die Sprints nur auf Dauer von einer Woche abzustellen – in diesem Fall können geänderte Anforderungen bereits bei der nächsten Wochenplanung berücksichtigt werden und es ist nicht notwendig einen Sprint abzubrechen.
Erleichtert wird dies natürlich, wenn die Firmenkultur die Vorgehensweise unterstützt – in diesem Fall sind die Stakeholder mit ihren geänderten Anforderungen besser integrierbar.
Der 4. Sprint - wie kann man dem Kunden sagen, was er am Ende eigentlich überhaupt bekommt?
Dies ergibt sich – wie im Vortrag – aus der tatsächlichen Teamgeschwindigkeit und der Anzahl der priorisierten Storys im Backlog. Durch die entsprechende Hochrechnung lassen sich über die Laufzeit die erreichbaren Ziele kommunizieren. Exemplarisch wurde das an einem Wasserglas gezeigt – entweder ist Wasser drin, oder Bier. Man kann nicht beides zur gleichen Zeit haben, eine Priorisierung und Festlegung auf die wichtigsten Ziele ist essentiell.
Wenn bei einer Hochrechnung für ein gewisses Feature die Unsicherheit der Erreichung bestimmter Ziele zu hoch ist, kann durch Managementmaßnahmen gegengesteuert werden (größeres Team, Verzicht auf andere Features, Zulieferung der Arbeiten, etc.).
Wie geht man mit nicht-funktionalen Anforderungen um (Geschwindigkeit, Performance, etc)?
Dafür werden „Done-Lists“ für die Stories geführt, und es wird bei der Beendigung einer jeden Story geprüft, ob die Done-List diesbezüglich erfüllt ist.
Zusammenfassung
Der Vortrag war in zweierlei Hinsicht lehrreich, zum einen natürlich inhaltlich, aber zum anderen auch, weil man am eigenen Leib als „Stakeholder“ erfahren konnte, wie man aus einer zu Beginn bestehenden riesigen Wunschliste mehr und mehr die wirklich essentiellen Punkte fokussieren muß, damit man innerhalb der Laufzeit zu definierten Ergebnissen kommt.
WCL322 - The Windows API Code Pack – add Windows 7 features to your application
Kate Gregory, Gregory Consulting
Was ist bei Windows 7 eigentlich anders?
- Optische Eigenschaften und User-Features wie Sprunglisten in der Taskleiste, Overlays und Thumbnails
- Grundlagen wie Einfluss von Netzwerk- und Energiemanagement, sowie Recovery.
Der Zugriff aus Managed-Code erfolgt dazu überwiegend durch Interop-Mechanismen zu nativem Code (Win32 oder COM).
Das Windows API Code Pack ist eine Managed-Bibliothek, damit man von .NET auf diese Windows-Features direkt zugreifen kann.
http://code.msdn.microsoft.com/WindowsAPICodePack
Alle hier vorgestellten Samples stammen aus dem CodePack und sind damit direkt nachvollziehbar. Da die Quelltexte vorliegen, kann man diese auch gut für das Selbst-Studium von Interop-Code und den Zugriff auf die WinAPI aus .NET heraus verwenden.
Spielereien mit der Taskbar
Die Anwendung
TaskbarDemostellt mittels einer Sprungliste eine Liste der zuletzt geöffneten Dateien zur Verfügung, sowie eine Task-Liste. Tasks in einem Taskbar sind dafür gedacht andere Exe-Dateien zu starten.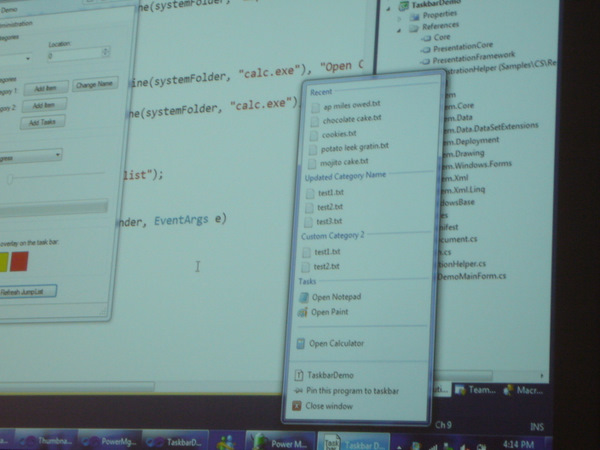
Mit relativ simplem Code lässt sich das erreichen:
private JumpListCustomCategory category1 = new JumpListCustomCategory("Custom Category 1"); private JumpListCustomCategory category2 = new JumpListCustomCategory("Custom Category 2"); ... // create a new taskbar jump list for the main window jumpList = JumpList.CreateJumpList(); // Add custom categories jumpList.AddCustomCategories(category1, category2);Um Overlays zu nutzen ist es notwendig, in der Taskleiste von Windows 7 große Icons zu nutzen. Durch Overlays kann man den Fortschritt von Aktionen darstellen, wie ebenfalls in der
TaskbarDemozu finden ist.
In der Taskbar zeigt ein roter Balken den Fortschritt an, und ein Icon wird zusätzlich als Overlay eingeblendet. Achten Sie bei der Namensgebung der Icons in den Ressourcen übrigens darauf, daß Sie sinnvolle Namen verwenden: wenn ein Nutzer Windows 7 in einem Modus für Sehbehinderte fährt, bekommt er den Namen des Icons angezeigt – ein schlichtes
Icon1.icowäre dann etwas seltsam.In einigen Applikationen machen auch Taskbar-Buttons Sinn, es handelt sich hier um klickbare Buttons direkt in der Taskbar. Damit kann man z.B. ein Programm direkt stoppen oder etwas umschalten, ohne das Fenster zu vergrößern. Ein Beispiel könnte ein Audioplayer sein, den man sofort anhalten kann. Die Applikation Image Viewer Winforms Demo zeigt dies.
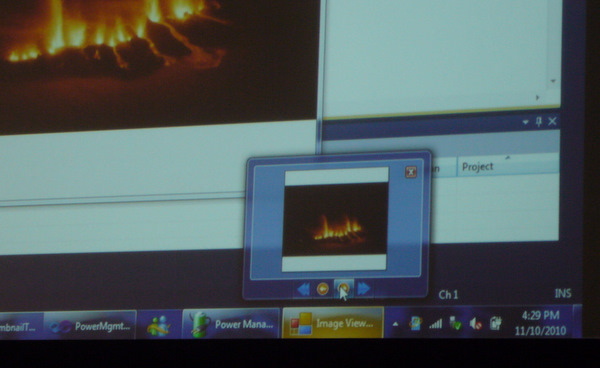
Technisch gesehen wird der Eventhandler des „normalen“ Buttons der Applikation einfach auch als Eventhandler der Thumbnail-Buttons verwendet.
Von vielen Applikationen kennt man das Thumbnail als Miniatur des „großen“ Applikationsfensters. Allerdings muß das nicht so sein, das Thumbnail kann aus einem Ausschnitt des Applikationsfensters gebildet werden. Dazu wird ein Rectangle über die GUI der Applikation gelegt, und dieses Rechteck wird zur Erstellung des Thumbnails verwendet.
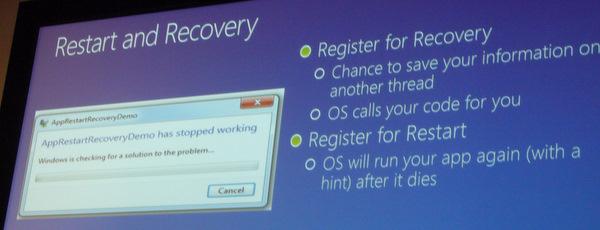
Restart and Recovery
Durch Restart and Recovery kann man erreichen, daß eine hängende Applikation ihre Daten nicht verliert, da durch das OS ein neuer Thread gestartet wird, der die Daten noch sichert. Das Bild hat jeder Windows 7-Anwender schon einmal gesehen.
Die Applikation
AppRestartRecoveryDemoimplementiert eine solche Vorgehensweise. Ein Tipp: wenn man Recovery testet, sollte man dies außerhalb des Debuggers tun – denn sonst springt der Debugger ein und fängt das abstürzende Programm, und das OS ruft die Notfallfunktion nie auf.Beachten Sie aber, daß sie sich innerhalb einer solchen Recovery-Funktion nicht mehr in dem ursprünglichen Thread-Kontext befinden – der Zugriff auf die GUI-Elemente ist nicht mehr möglich. Entsprechend müssen die Daten außerhalb der Forms liegen, damit der Mechanismus funktioniert.
Was man in diesem Recovery-Handler tut ist letztlich eine Entscheidung des Programmierers, aber man sollte beachten, daß das Programm gerade abgestürzt ist. Sinnvollerweise sollten so schnell wie möglich die Daten auf der Festplatte abgeladen und die Applikation neu gestartet werden. Sollte der Recovery-Code selbst wiederum abstürzen, ist man dann aber wirklich am Ende des Programms angekommen.
Power-Management
Da immer mehr Maschinen mobil sind, wird die Frage ob ein System auf Batterie oder Netz läuft auch für Applikationen immer wichtiger. Bei Batterie-Betrieb kann man darauf reagieren, zum Beispiel kann man seltener pollen, man speichert seltener die Daten oder man schraubt die grafische Darstellung zurück. Auch kann eine Reduktion der Anzahl verwendeter Threads zur Reduktion der Leistungsaufnahme beitragen.
Übrigens, wenn man ständig aktiv nachschaut ob man auf Batterie läuft, verbraucht man die Batterie schneller – eine böse Falle. Man sollte sich stattdessen durch ein Event über das CodePack informieren lassen, daß man nun mit einer anderen Spannungsversorgung läuft. Die
PowerMgmtDemozeigt, wie man auf diese Betriebsarten oder auch auf einen Wechsel des Powermanagement-Profils durch den User reagiert. Im Batteriebetrieb kann man zum Beispiel Aufräumthreads (z.B. in einer Datenbank) zurückstellen, bis der Rechner wieder auf Netz läuft.Startet ein Programm, das den Code Pack verwendet, unter WindowsXP, so sollte es üblicherweise nicht abstürzen, da die Bibliothek durch Exception-Handler die fehlenden Funktionseinstiegspunkte abfängt. Allerdings... es wurde deutlich empfohlen das einmal auszuprobieren, bevor das Programm verteilt wird.
Unter dem Strich stellt diese Bibliothek auch eine Antwort auf die Frage dar, ob die WinAPI oder C++ tot sind – neue Features der Windows-Betriebssysteme oder Bibliotheken sind zunächst immer nur nativ (oder unmanaged) ansprechbar. Durch entsprechende Wrapper werden diese dann auch den .NET-Sprachen zur Verfügung gestellt, damit sie dort nutzbar sind. Offensichtlich arbeitet selbst Microsoft nach diesem Muster, was vielleicht eine Beruhigung für den einen oder anderen Leser darstellen dürfte.
WCL307 - Windows Processes, Threads and Jobs all around
Maral Topalia, Solution Specialist Midware Data Systems
Maral erklärt das Zusammenspiel von Prozessen, Threads und Jobs und welche Datenstrukturen daran hängen. Ein technisch komplexer Vortrag, der leider ohne Folien nicht wiedergebbar ist – zu viele Details, Abläufe und Strukturen tauchen hier auf.