Microsoft tech ed 2010 in Berlin - Tag 2 (C++)
-
Microsoft tech ed 2010 in Berlin

Tag 2 – Donnerstag, 11.11.2010 – die C++-Themen
Zusammenfassung
Da die Zusammenfassung des 2. Tags zu lang geworden wäre, habe ich die C++-Themen und die Themen rund um Agile/Scrum in zwei verschiedene Artikel getrennt.
DEV208 – The Future of Parallel Programming in Visual Studio
Was bringen die künftigen Versionen des Visual Studio für die Parallel-Programmierung mit C# und C++? Bald kann C++ die GPU programmieren – erfahren Sie wie.
DEV311 - Modern Programming with C++0x in Microsoft Visual C++ 2010
Welche Neuerungen von C++0x werden bereits heute im Visual Studio unterstützt? Von Lambda und
parallel_for…Einleitung
Nicht näher zugeordnete Fotos zu der Veranstaltung findet Ihr unter http://www.c-plusplus.net/misc/teched2010 .
Der Bericht zu Tag 1
Der Bericht zu Tag 2 (Agile/Scrum)DEV208 – The Future of Parallel Programming in Visual Studio
Stephen Toub, Parallel Computing Platform, Microsoft Corporation
Dieser Vortrag zeigt auf, welche Entwicklungen es zur Zeit im Visual Studio in Bezug auf die Parallel-Programmierung gibt, was demnächst kommt und wie man dann die GPU der Grafikkarte für die Programmbeschleunigung nutzen kann.
Gleich zu Beginn weist Stephen darauf hin, daß es hier um die Zukunft geht – alles kann sich noch ändern. „Everything is subject to change, folks!“
Die Tools
Die Concurrency Runtime von C++ wird übrigens als „Conc(e)rt“ ausgesprochen – wußte das jemand?
Bei den Tools gibt es vor allem den Trend, nicht nur die einzelne CPU betrachten, sondern auch die GPU. Es wird also einen GPU Profiler und einen GPU Debugger geben. Auch MPI – für größere Multi-Prozessor-Systeme – wird mit einem eigenen Profiler und Debugger unterstützt werden.
In naher Zukunft soll es ebenfalls ein Watch-Fenster geben, das die Variableninhalte über diverse Threads hinweg zeigen kann. Ein Beispiel kann eine Funktion mit lokalen Variablen sein, die von diversen Threads aufgerufen wird – in jedem Thread hat eine solche Variable einen eigenen Wert. In künftigen Visual Studio-Versionen kann man dann diese unterschiedlichen Werte pro Thread sehen.
.NET
In der Zukunft soll bei .NET die asynchrone Programmierung einfacher werden.
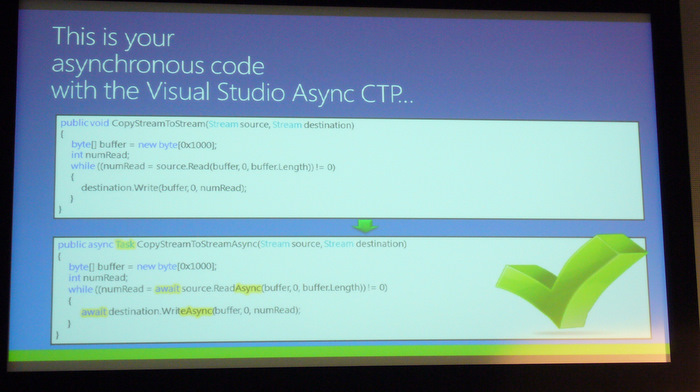
Mit dem
Async-Suffix erzeugt der Compiler entsprechenden Code, damit die Funktion asynchron aufgerufen werden kann, und die SchlüsselwörterTaskundawaitsorgen für die Synchronisation.Im Beispiel zeigt Stephen eine Excel-Applikation, die mit der Monte Carlo Methode einen Options-Preis berechnet. Verwendet man die neuen Schlüsselwörter reagiert Excel weiterhin während gerechnet wird, da dies im Hintergrund in einem separaten Thread geschieht.
Für eigene Experiment: http://msdn.com/vstudio/async (Beispiel Option Pricing)
Folgende Spracherweiterungen wird es dazu geben:
async: damit wird eine Methode oder Lambda-Ausdruck als asynchron markiert
await-Operator: halt den Fluß auf bis davon abhängige Tasks ausgeführt sindIn den Demos gibt es das Beispiel
Boids– hier werden Vogelschwärme mit Tasks realisiert, auch sind einige Regeln für einen Schwarmalgorithmus implementiert. Ein Doppelklick in das Bild sorgt für eine Invertierung der Schwarmregeln und die Vögel fliegen auseinander.Die Programmierung wird einfacher, da im asynchronen Task einfach Timer und Wartezeiten enthalten sein können, nach deren Ablauf etwas geschieht. Der Programmfluß innerhalb der asynchronen Aufgabe wird wesentlich übersichtlicher.
Auch wird es künftig bei asynchronen Aufgaben möglich, nach einer gewissen Wartezeit einen Task automatisch zu beenden.
Weiterhin führt der Scheduler Limitierungen ein, um zum Beispiel parallele Vorgänge in der Anzahl der gleichzeitigen Vorgänge zu steuern.
Die neue TPL Dataflow-Bibliothek erlaubt die Implementierung von agentenbasierten Abläufen, die über Messages miteinander kommunizieren. Die Konzepte stammen aus der Asychnronous Agents Library von Visual C++ 2010 und der CCR vom Microsoft Robotics SDK. Diese Steuerungs- und Interaktionskonzepte sollen nun in die normale Programmierung einfließen.

Im Beispiel können der Funktion Werte zur Verarbeitung übergeben werden, diese warten in einer Queue auf die Verarbeitung.
Damit wird es auf einfache Weise möglich einer Funktion eine Verarbeitungsqueue zu verschaffen, ohne diese explizit zu programmieren. Auch Verkettungen zwischen den Dataflows werden unterstützt, so daß ganze Aufrufkaskaden möglich sind: wenn die erste Funktion mit der Berechnung eines Werts aus der Queue fertig ist, wird das Ergebnis in die nächste Queue einer Funktion eingehängt.
Ein Beispiel dafür ist die
Real Estate Simulationaus dem oben angesprochenen Download.C++ - die Parallel Pattern Library (PPL)
Es werden weitere Container und Algorithmen für Concurrency ergänzt, und direkte Unterstützung von Tasks.
concurrent_unordered_mapconcurrent_unordered_multimapconcurrent_unordered_setconcurrent_unordered_multisetparallel_transformparallel_reduceparallel_sortparallel_radixsortparallel_buffered_sort
Auch wird in C++ die Unterstützung von Tasks erweitert.
Diese Beispiele werden bereits in den nächsten Wochen veröffentlicht, so daß man mit ihnen „spielen“ kann.
Parallele Daten und GPU-Beschleunigung
Letztlich geht es darum die enorme Geschwindigkeit von GPUs zu nutzen, wenn man Verarbeitungen hat, die ähnlichen Regeln folgen: schnelle Verarbeitung und Verkettung von gleichartigen Daten.
Für C++ werden Erweiterungen für parallele Daten eingeführt, damit können C++-Funktionen innerhalb von Kernel-Funktionen benutzt werden, allerdings mit einem eingeschränkten Funktionsumfang. Mit diesen Änderungen wird es dann möglich, eine Operation auf der GPU auszführen:

Links im Bild der klassische Weg wie man zwei Arrays addiert, in der Mitte unter Verwendung von
parallel_for– immer noch auf der CPU basiert. Rechts im Kasten sieht man dann die Einbeziehung der GPU, wie der C++-Code aussehen würde (wobei sich das in den Details noch etwas ändern wird).Ein kleines Fazit: es wird der Trend erkennbar, daß ganz neue Funktionen und Möglichkeiten im Umfeld der parallelen Programmierung zunächst in C++ realisiert und erprobt werden, bevor sie dann in den Folgeschritten auch im .NET-Framework verfügbar werden.
DEV311 - Modern Programming with C++0x in Microsoft Visual C++ 2010
Kate Gregory, Gregory Consulting
Obwohl der neue C++-Standard noch nicht endgültig verabschiedet ist, erlaubt Visual Studio die Nutzung einiger Features von C++0x. Dieser Vortrag stellt vor, was Visual C++ heute schon kann und was noch kommen soll. Kate geht nicht auf MFC- oder Windows 7-Unterstützung ein – es dreht sich wirklich nur um C++.
Die Features des TR1, des Technical Report 1 des C++-Kommitees aus dem Jahr 2005 sind zum Teil bereits im VC++ 2008 SP1 verfügbar gewesen, weitere Dinge kamen nun im Visual C++ 2010.
Lambda-Ausdrücke
Eine wesentliche Ergänzung ist die Nutzung von Lambda-Ausdrücken. Dabei handelt es sich um anonyme Funktionsobjekte.
Die klassische Schreibweise führt dazu, daß man lästigerweise irgendwelche Funktionen anlegen muß, die nur ein einziges Mal benutzt werden.
void print_square(int i) { cout << i*i << endl; } int main() { vector<int> v; for_each(v.begin(), v.end(), print_square); }mit einem Lambda-Ausdruck ändert sich zu
int main() { vector<int> v; for_each(v.begin(), v.end(), [](int i) { cout << i*i << endl; } ); }Die eckigen Klammern sind dabei der Platzhalter oder Kennzeichner für Lambda-Ausdrücke.
Wenn ein Lamba-Ausdruck Parameter hat oder einen Wert als Ergebnis liefern soll, wird dies entsprechend der normalen Funktionsschreibweise an die eckigen Klammern angehängt. Im folgenden Beispiel übernimmt die Funktion einen
int-Parameter und liefert eindouble-Ergebnis. Wenn die Zahl gerade ist, wird sie mit 3 potenziert, andernfalls durch 2 geteilt.vector<int> v; deque<int> d; transform(v.begin(), v.end(), front_inserter(d), [](int n) { return n * n * n; }); transform(v.begin(), v.end(), front_inserter(d), [](int n) -> double { if (n % 2 == 0) {return n * n * n;} else {return n / 2.0;} });Die Variablen aus der Umgebung, in der der Lambda-Ausdruck aufgerufen wird, sind nicht automatisch sichtbar. Diese müssen explizit innerhalb der Funktion sichtbar gemacht werden. Dazu werden die entsprechenden Variablen innerhalb der eckigen Klammern angegeben, ein
=führt dazu, daß alle Variablen sichtbar sind. Um Variablen innerhalb des Lambda-Ausdrucks zu verändern, kann man ein „Capture by reference“ einsetzen. Die Verantwortung, daß die Referenzen auf gültige Variablen zeigen, liegt allerdings beim Programmierer. So ist das eben in C++.v.erase(remove_if(v.begin(), v.end(), [x, y](int n) { return x < n && n < y; }),v.end()); v.erase(remove_if(v.begin(), v.end(), [=](int n) { return x < n && n < y; }), v.end()); for_each(v.begin(), v.end(), [&x, &y](int& r) { const int old = r; r *= 2; x = y; y = old; });Mit dem schon bekannten – aber vorher ganz anders verwendeten – Schlüsselwort
mutablewird die Veränderung der Variablen erlaubt.
Welchen Typ hat eine solche Lambda-Funktion eigentlich? Man kann sich vorstellen, daß dies nicht mehr einfach ermittelbar ist, es ist auf jeden Fall kein
intoder eine Klasse mehr. Der Programmierer weiß es nicht, aber es gibt jemanden, der es weiß – der Compiler. Mittels des Schlüsselwortsautoüberlässt man die Wahl des richtigen Typs dem Compiler, damit lassen sich dann auch Lambda-Ausdrücke an Funktionen zuweisen.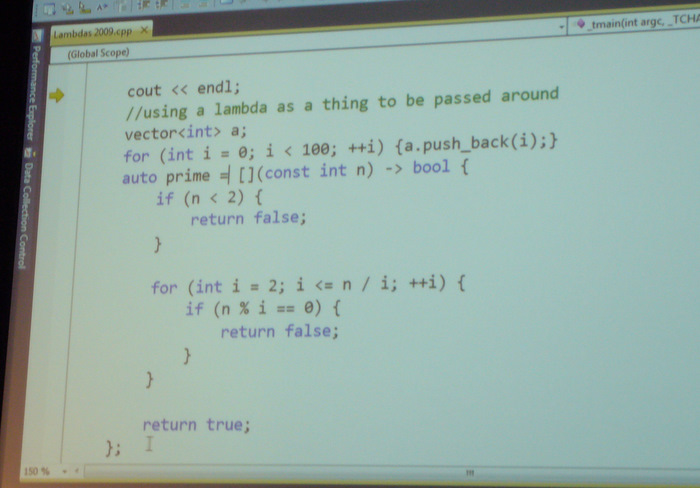
Aber
autoerlaubt auch weitere Vereinfachungen beinewoder bei Iteratoren:auto x = new HugeObject(42); for (auto it = v.begin(); it != v.end(); ++it) const auto* p = new foo and const auto& r = bar workBesonders interessant sind natürlich Kombinationen aus Templates und
auto, da man hier die Auswahl des richtigen Typs bis zum Zeitpunkt der Instanziierung aufschiebt.Smart-Pointer
Weitere Erweiterungen sind bei den Smart-Pointern zu finden – die alten Smart-Pointer waren nicht so smart – es gibt im VC nun
shared_ptrundunique_ptr. Um einenshared_ptranzulegen kann manmake_shared<T>verwenden.// VC9 SP1: shared_ptr<T> sp(new T(args)); shared_ptr<T> sp(new T(args), del, alloc); // VC10: auto sp = make_shared<T>(args); auto sp = allocate_shared<T>(alloc, args);Der
unique_ptrersetzt den altenauto_ptrund ist nicht kopierbar, sondern nur „bewegbar“ (movable).Wer damit noch nicht zu tun hatte sollte daran denken, daß diese Smart-Pointer nicht mehr mit
deletegelöscht werden, sondern daß sich „jemand“ im Hintergrund darum kümmert, daß der Speicher nur solange benutzt wird wie jemand mit den Daten arbeitet oder darauf zeigt.Als weitere Neuerung im VC wären die konstanten Iteratoren
cbeginundcendzu nennen.Änderungen im Visual Studio C++
Das Intellisense benutzt keine ncb-Dateien mehr, sondern speichert die Informationen nun in einer projekt-lokalen SQL-Datenbank. Damit wird ist Intellisense unter C++ deutlich schneller. Dies steht zur Zeit für C++/CLI noch nicht zur Verfügung, nur für natives C++.
Die Concurrency-Runtime erlaubt die Parallelisierung von C++-Code. Um die Ausführung (oder den Absturz
") zu überwachen gibt es im Visual Studio die Ansichten für Tasks-Stacks und die parallel ausgeführten Tasks.
zu überwachen gibt es im Visual Studio die Ansichten für Tasks-Stacks und die parallel ausgeführten Tasks.Lustig ist die Suchfunktion, die bei einer Suche nach
SerialFlipauchFlipSerialfindet – die Wörter werden bei der „Camel-Case-Schreibweise“ auch bei anderer Reihenfolge gefunden.Fallbeispiel: Parallelisierung mit der Parallel Performance Library PPL
Dies ist übrigens eine MFC-Applikation! Siehe auch http://msdn.microsoft.com/officeui
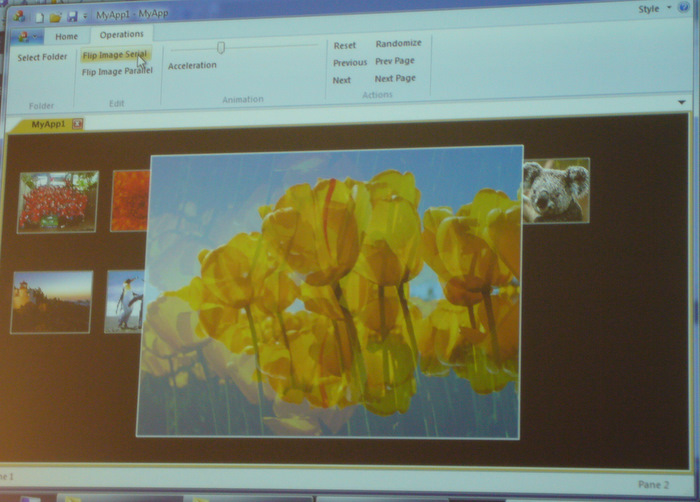
In dieser Beispielapplikation kann man sich Bilder ansehen und es gibt eine “Kipp-Funktion”, die ein Bild auf den Kopf stellt. Der Algorithmus mit sequentieller Ausführung ist bereits implementiert, es soll nun noch eine parallele Variante ergänzt werden. Offensichtlich ist das relativ einfach, da man beim Bild die Zeilen alle unabhängig voneinander bearbeiten kann.
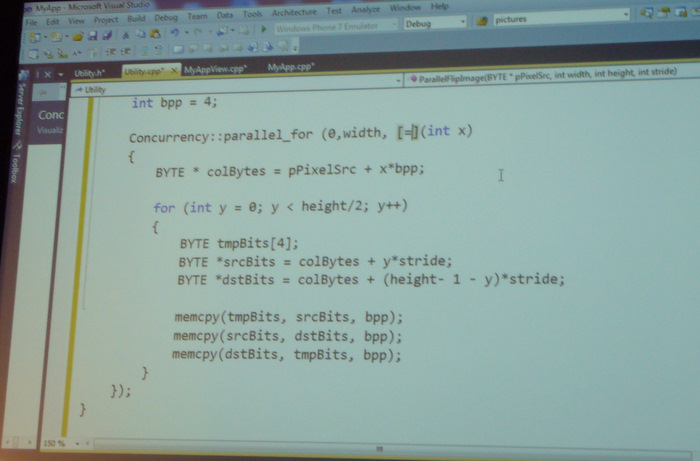
Die Verwendung des “parallelen for” aus dem Namespace
Concurrencyund die Umwandlung des ursprünglichen Schleifenrumpfs in einen Lambda-Ausdruck waren alle wesentlichen Änderungen, um die Schleife zu parallelisieren.Mit dem Performance Wizard kann man sich die parallele Ausführung ansehen – die Spikes links zeigen die sequentielle Version, bei der nur ein Kern benutzt wird. Rechts die Spikes sind die parallele Version, wo tatsächlich „die ganze CPU“ am arbeiten ist.
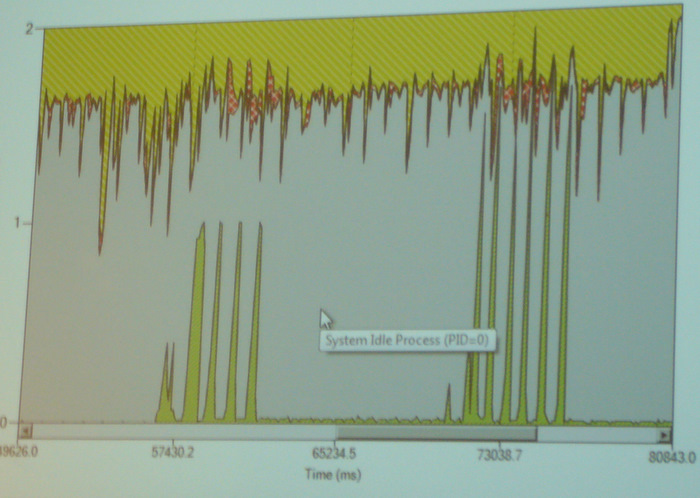
Die Parallelisierungsaktion dauerte im Code nur rund 5 Minuten und war mit der PPL sehr einfach – allerdings muß der Programmierer nach wie vor die Frage selbst beantworten, ob diese Aktion auch sicher ist oder ob man in Probleme laufen kann. Ohne Intelligenz und Erfahrung wird es auch in Zukunft mit immer besseren Tools nie gehen. Sehr beruhigend!?
C++ Is Very Much Alive

Kate sieht vor allem im Bereich des Interop ein großes Handlungsfeld für C++ und macht darauf aufmerksam, daß Generics langsamer sind als Templates. Eine gute Kombination kann sein aus Managed-Code heraus C++ aufzurufen. Auch sind neue Features des Betriebssystems früher in C++ nutzbar als unter .NET.
Es gibt aber natürlich manchmal Frustration, weil die Verbesserungen der IDE bei C# schneller umsetzbar sind als bei C++. Bei vielen Programmierern entsteht daher das Gefühl der Vernachlässigung von C++. Aber die Sprache entwickelt sich weiter und steht bei den Themen Geschwindigkeit und Parallelisierung weiter Vorne.
-
Danke für diese sehr interessanten Einsichten - als Linuxxer würde ich sonst ja nie was aus der MS-Welt mitkriegen
")
Aber was mich verwundert, ist das explizit auf C++ zu "Interop"-Zwecken herumgeritten wird. Ich denke, Interop von C++ mit anderen Sprachen geht fast überhaupt nicht, weil man keine DLLs zur Verfügung stellen kann, die andere Sprachen "einfach" callen können. Stichwort calling conventions und name mangling.
Was für ein Voodoo haben die Windowser denn erfunden, damit man C++ tatsächlich mit anderen Sprachen interoperabel bekommt? COM?
Philipp
-
printf ftw !!!!!11elf
-
PhilippM schrieb:
Was für ein Voodoo haben die Windowser denn erfunden, damit man C++ tatsächlich mit anderen Sprachen interoperabel bekommt? COM?
Das Thema wurde tatsächlich in einer Diskussion zum Vortrag angesprochen.
Die Antwort war:
- Bei lokalen Abhängigkeiten: COM; C++/CLI, wobei auf den Laufzeitverlust bei Typkonversion hingewiesen wurde
- Bei Austausch via Netz: Webservices (DCOM wird nicht mehr so gerne gehört)
Man kann die grundsätzliche Frage stellen, wozu, aber ein Argument war eben "man bekommt mit C++ zur Zeit die Parallelisierung und Nutzung der CPUs besser in den Griff als mit .NET und damit ist der Zeitverlust durch Interop geringer als der Gewinn durch C++-Optimierung". Interessanterweise hat Intel das auf der ISTEP auch so gesagt.
-
Wann kommt der neue VC++ raus?
-
Die neuen Features in Bezug auf Parallelisierung, die in dem Vortrag angesprochen wurden, kann man als Betas teilweise schon laden, das wird sich noch mal ändern, aber Previews gibt es teilweise.
Nachdem aber das VC2010 erst auf den Markt kam, wird sich wohl vor 2012 nichts tun.