Microsoft tech ed 2010 in Berlin - Tag 3 (Scrum/Use Cases)
-
Microsoft tech ed 2010 in Berlin

Tag 3 – Freitag, 12.11.2010
Einleitung
Nicht näher zugeordnete Fotos zu der Veranstaltung findet Ihr unter http://www.c-plusplus.net/misc/teched2010 .
Der Bericht zu Tag 1
Der Bericht zu Tag 2 (C++)
Der Bericht zu Tag 2 (Scrum/Agile)Ein paar Anmerkungen
Auf dieser Veranstaltung trat übrigens ein bestimmter Typus Mensch sehr häufig auf: der iPhone-Zombie. Es handelt sich hierbei um einen Menschen, der mit gesenktem Kopf durch die Gegend läuft und auf ein kleines Gerät schaut, das er in Bauch- bis Brusthöhe vor seinen Körper hält. Der Zombie ist dadurch zu erkennen, daß er um Ecken läuft und in andere Menschen rennt, daß er plötzlich aufsiehtt und überrascht um sich schaut wohin er gehen will, und daß er wenig von der Außenwelt mitbekommt. Während der Vorträge ist er daran zu erkennen, daß er wild mit dem Daumen oder Zeigefinger auf einem kleinen Glasstück reibt und eigentlich nur durch das Klatschen mitbekommt, daß der Vortrag zu Ende ist.
In der modifizierten Variante gibt es den tauben iPhone-Zombie, der zusätzlich noch Gehörstopfen trägt, die mit einem weißen (TM) Kabel mit diesem Kästchen vor dem Bauch verbunden sind. Erkennbar ist diese Form dadurch, daß sie noch hilfloser und verwirrter durch die Gegend irrt und noch öfter gegen Personen oder Gegenstände rennt.
ARC208 - Architecture in Agile Projects – How to do it right
Mitch Lacey, Mitch Lacey & Associates, Inc.
Was heißt Agile – bedeutet das keine Dokumentation? Keine Architektur? Chaos?
Das agile Abwicklungsmodell
Die meisten Firmen arbeiten nach wie vor mit einem klassischen Microsoft Project-Ansatz, wo die Projekte sequentiell durchgeführt werden. Der Fokus liegt auf der Zeitachse, die dadurch aber bereits zu einem Projektrisiko wird: während der Bearbeitung der Arbeitsschritte ist kein Feedback möglich, und Abweichungen vom ursprünglichen Plan und aktuellen Anforderungen summieren sich sukzessive auf.
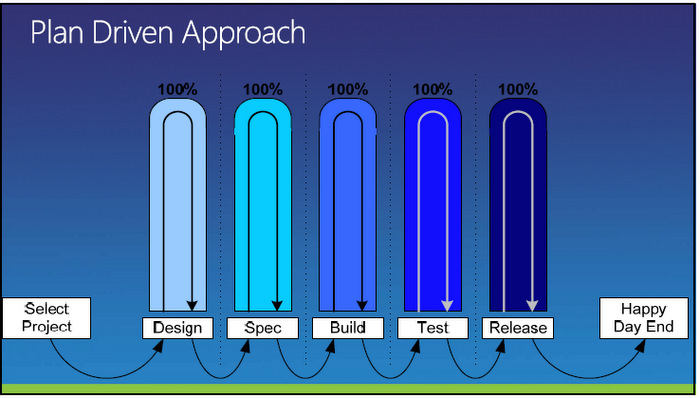
Längere Planungszeit führt zwar zu mehr Details und verringert scheinbar das Risiko, paradoxerweise erhöht sich aber das Projektrisiko, weil die Summe der kleinen Abweichungen über der Planungszeit stärker wächst. Das Risiko für ein Scheitern des Projekts wächst.
Beim adaptiven Ansatz nach einer agilen Methode wie Scrum wird das Projekt bekanntlich in kleine in sich geschlossene Schritte geteilt. Da nach jedem Sprint Produkte geliefert werden, ist ein frühes Feedback und eine Korrektur der Zielrichtung möglich. Auch wird es möglich dadurch ein „fail early“ zu erzielen, also das Projekt vielleicht sogar abzubrechen und weitere Geldvernichtung zu vermeiden.

Auswirkungen auf die Architektur
Damit man bereits frühzeitig ein irgendwie verwendbares Produkt nach einem Sprint liefern muß, wirkt sich das auch entsprechend auf die Architektur aus. Auch unterlegte komplexe Hardware steht im 1. Sprint noch vollständig nicht zur Verfügung, die Architektur der Software und ihre Verteilung auf die Systeme wächst mit dem Projekt mit.
Als Fallbeispiel stellte Mitch das Falcon Project vor. Es handelte sich um ein Authentifizierungssystem für das MSN-Netzwerk mit geplanten 15 Millionen Usern. Wie kann man nach dem 1. Sprint (der bei 4 Wochen lag) bereits etwas liefern?
Die Lösung lag darin, zunächst alle Daten nicht in den verteilten SQL-Datenbanken abgelegt wurden, sondern in Textdateien. Und es wurden nicht 15 Millionen User unterstützt – sondern genau einer. Allerdings erreichte das System bereits die nötige Performance-Anforderung.
Offensichtlich ist aber natürlich, daß hierbei der Code der frühen Sprints fast reiner Wegwerf-Code ist – nach Mitchs Aussagen sogar zu 90%. Es entspann sich eine Diskussion, ob man sowas aus Kostengründen akzeptieren könne – die meisten Projektleiter und Kunden haben damit ein Problem. Auf der anderen Seite gab Mitch zu bedenken, daß zum einen die ganzen Testcases dieser frühen Sprints erhalten blieben – sie waren stabil und konnten in späteren Sprints als Testfall benutzt werden. Man konnte messen, ob das erweiterte System qualitativ schlechter wurde.
Ebenso blieb auch die Erfahrung bei der Entwicklung erhalten, die Lerneffekte und die Risikominimierung. Bei jedem Sprint nahm die Zahl der zulässigen User um den Faktor 10 zu.
Minimal Feature Produkt
Um die Architekturanforderungen für den frühen Sprint anzupassen, ist es sinnvoll ein sogenanntes Minimal Feature Produkt zu definieren. Ein schönes Praxisbeispiel war ein Car-Configurator-Projekt für eine amerikanische Firma.
Es wurde analysiert, welches Modell am häufigsten verkauft wurde – in Bezug auf Motorisierung, Ausstattung und Farbwahl. Der Configurator unterstützte nach dem 1. Sprint genau nur diese Modellwahl. Alle anderen Optionen waren nicht wählbar. Diese waren erst in Folgesprints schrittweise ergänzt worden.

Die Idee dahinter ist, eine dünne Schicht durch alle Stufen zu realisieren, dann danach die Erweiterung um Features (z.B. Farbwahl, Reporting zu bestimmten Modellen). Jedes Feature wird angestreift und dann sukzessive ausgebaut.
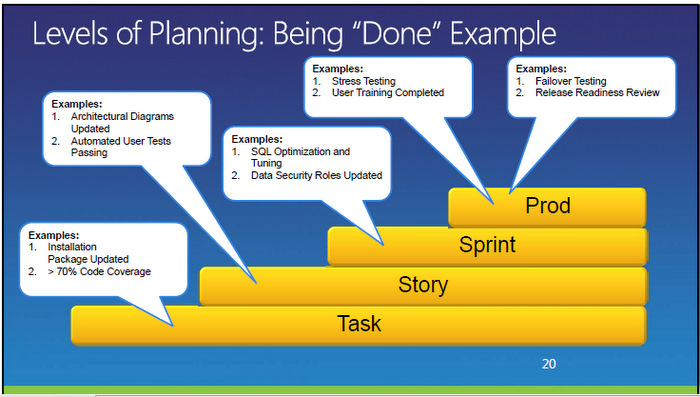
Was heißt eigentlich fertig?
Die Abarbeitung einer User Story wird mittels der Erledigung aller Merkmale der Done-List verfolgt. Aber was heißt „done“? Es compiliert? Es läuft bei mir? Mit Dokumentation? Wie schnell?
Die Definition von „done“ muß vorher für die Tasks, Storys, Sprints und das Produkt festgelegt sein.
Auch die Dokumentation erfolgt zusammen mit dem Sprint. Die Inhalte der Done-List müssen zum Problemfall passen und abgestimmt sein, auch im Team. Das bedeutet auch, daß es für die User Storys, die Aufgaben im Product Backlog und letztlich für das Produkt unterschiedliche „Done“-Merkmale gibt.
Questions & Answers
Am Ende des Vortrags gab es noch Zeit für einige Fragen. Interessant dabei:
Ein Zuhörer erwähnte, daß in seiner Firma Methoden wie Scrum von der Projektleitung abgelehnt würden, es handelte sich hierbei um einen Six Sigma Black Belt. Für ihn war nicht verständlich, warum es dem Team nicht auf Anhieb gelingt innerhalb gewisser Unsicherheitsschranken die richtige Software zu erstellen.
Softwareentwicklung ist aber letztlich ein Lernprozess, es geht darum ein komplexes Gebilde „aus dem Hirn in den Schirm“ zu bringen. Der Lernprozess selbst besteht darin, gewisse Dinge mehrfach zu tun, bis sie richtig sind.
Ein anderer Aspekt war das Thema verteilte Teams – agile Methoden leben davon, daß das Projektteam sich räumlich nahe ist. Das gelingt bei verteilten Teams nicht. Als Abhilfe können direkte Telefonstandleitungen und ständig verfügbare Videokonferenzen dienen. Oder eben Reisen. Wer aus Kostengründen darauf verzichtet, verliert die Kommunikation und damit auch die Vorteile der Methoden.
ARC205 – How Smart Use Cases Can Shape Web Software Development
Sander Hoogendoorn, Principal Technology Officer, Capgemini
http://www.accelerateddeliveryplatform.com/SmartUseCase.ashx
Anforderungen ermitteln
Bei der Anforderungsermittlung werden typischerweise heute entweder Use Cases, User Storys oder das gute alte Word eingesetzt. Wobei letzteres die große Hypthothek mit sich herumträgt, daß es fast unmöglich ist in diesen Dokumenten die gegenseitigen Abhängigkeiten zu überblicken und konsistent zu halten.
Laut Sanders Aussage tendieren User Storys dazu, daß sie oftmals zu unstrukturiert für komplexe Umgebungen sind. Unter einer komplexen Umgebung ist hier eine heterogene Systemlandschaft mit einer Abdeckung von Desktop-Clients, Webanwendungen bis hin zum ERP-System zu verstehen.
Use Cases
Der Vorteil eines Use Cases ist, daß es sich um eine Beschreibung mit Vorbedingungen, Nachbedingungen und Inhalt handelt. Die Beschreibung des Use Cases enthält die Schrittfolge, wie man von der Vorbedingung zur Nachbedingung kommt - einschließlich der alternativen Wege, falls der „typische“ Ablauf einmal fehlschlägt.
Traditionell werden die Use Cases sehr umfangreich und sind kaum noch testbar, wenn Beschreibungen über mehrere Seiten gehen. Bei den alternativen Flows ist die Konsistenz und der Dualismus von gleichen Abläufen nur sehr schwierig zu kontrollieren.
Trotzdem kann sich hinter einem solchen 20-seitigen Use Case nur eine einfache Aufgabe wie „Kundenadresse ändern“ verbergen, wenn die Umgebung sehr komplex ist.
Außerdem kommt dazu, daß Use Cases auf unterschiedlichen Abstraktionsebenen exisitieren.
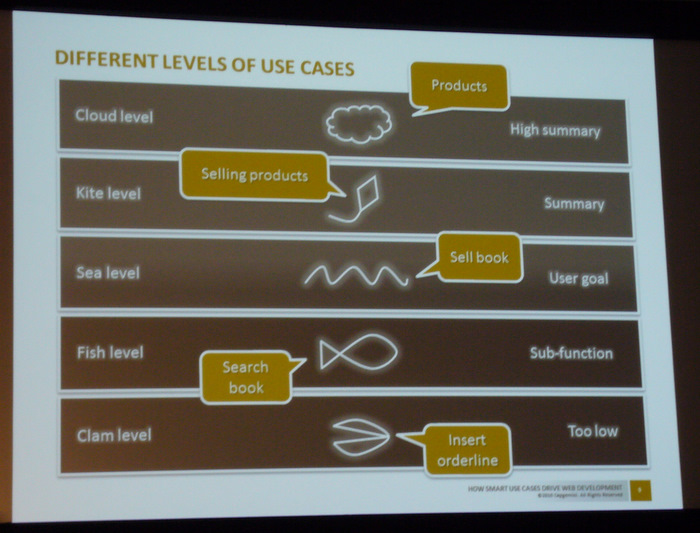
Use Cases werden oft auf dem „Sea Level“ geschrieben, können aber bis runter auf den „Clam Level“ gehen.
Smart Use Cases
Im Unterschied dazu setzen sich Smart Use Cases aus untergeordneten Use Cases zusammen, z.B. für die Registrierung eines Service-Calls gibt es dabei mitwirkende Use Cases wie Kundennamen suchen, Kunden anlegen, etc. Die Dokumente werden kleiner und zahlreicher, verwenden aber immer die gleichen Subdokumente (kleineren Use Cases).
Durch die geringere Größe eigenen sich Smart Use Cases besser für die Implementierung, man kann sie sogar als Input für das Product Backlog bei Scrum verwenden. Da die „kleinen“ Smart Use Cases in größeren Szenarien immer wieder auftauchen, wird zudem die Testbarkeit erleichtert.
Traditionell wird bereits auf dem „Cloud-Level“ das Start-Dokument begonnen, aber gerade das Wasserfall-Modell erzeugt oft viel zu detaillierte Dokumente, die nicht mehr prüf- und testbar sind.
Die Prozesse werden daher zerlegt in Reihenfolge von Prozessen oder hierarchische Abläufe. In der Zerlegung tauchen erstmalig die elementaren Businessprozesse auf, die der Regel „one time one place one person“ (OTOPOP) folgen.
Diese können in Use Cases übersetzt werden – traditionell. Diese untersetzen sich dann in Smart Use Cases.
Guideline
Folgende Unterteilungsregeln für die Use Cases können in der Praxis helfen.
- Wiederverwendung von Abläufen
- Ein Formular pro Use Case
- Ein Use Case pro Web Part
- Komplexe oder unbekannte Funktionalität wird isoliert
- Komplexe Berechnungen werden abgebildet
- Reporte und Analysen erkennen und isolieren
- Interaktion mit anderen Parteien isolieren
- Dienste modellieren bei Service orientierter Software
- Vermeidung von technischen Details (Datenbankanbindung, Interfaces)
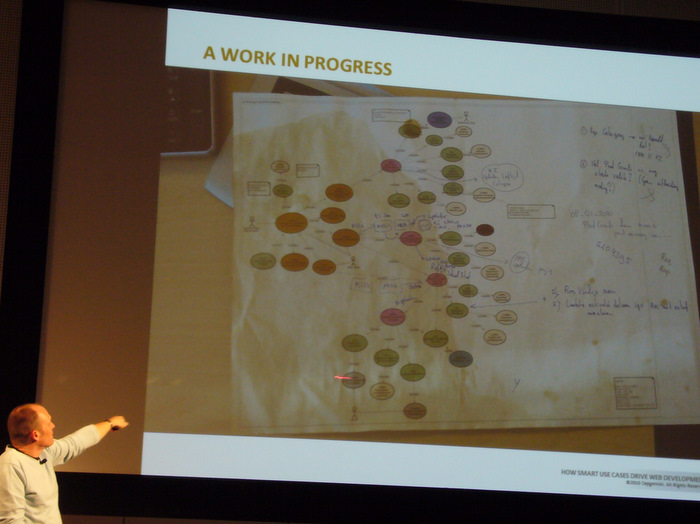
Im Bild zeigt die Farbe die Zugehörigkeit zum Abstraktions-Level und die Zerlegung, vom eigentlichen Prozess runter über den Workflow bis zu unterstützenden Prozessen.
Die Beschreibung der entstehenden Use Cases wird kleiner, in der Größe von 3-4 Seiten.
Stereotypen und Use-Case-Implementierung
Die Stereotypen fassen den Typ der Use Cases zusammen. Unter
http://www.accelerateddeliveryplatform.com/stereotypes.ashx
befindet sich eine Liste mit gängigen Mustern.
Jeder Use Case wird zu einer Klasse im Programm. Dazu gibt es auf der Webseite www.smartusecases.com ebenfalls ein Codegenerator. Die unterschiedlichen Level und Elemente der Architektur spiegeln sich im Code.
Das Task-Pattern
Wie implementiert man den Use Case im Programm?
Der Use Case ist verantwortlich für den Ablauf, zum Beispiel zunächst ein Bildschirmfenster für Dateneingabe öffnen, danach die Daten aus dem Datenlayer holen, in einer Ausgabe wieder darstellen. Die Uses Cases sehen sich nicht, sondern werden nur von dem Task Manager gesteuert.

Das Pattern evaluiert zunächst die Vorbedingungen und führt dann die Aufgabe aus. Ein Klick im Webformular ruft direkt den Use Case auf.
Testing
Test Cases werden ebenso zu Beginn erzeugt, für jeden Smart Use Case ein Test. Die Methoden des Smart Use Case werden vom Test ausgeführt und die Ergebnisse geprüft. Besonders vorteilhaft ist zudem, daß für jeden Smart Use Case bereits zu Beginn auch eine Nachbedingung definiert war, diese lässt sich vom Test prüfen.
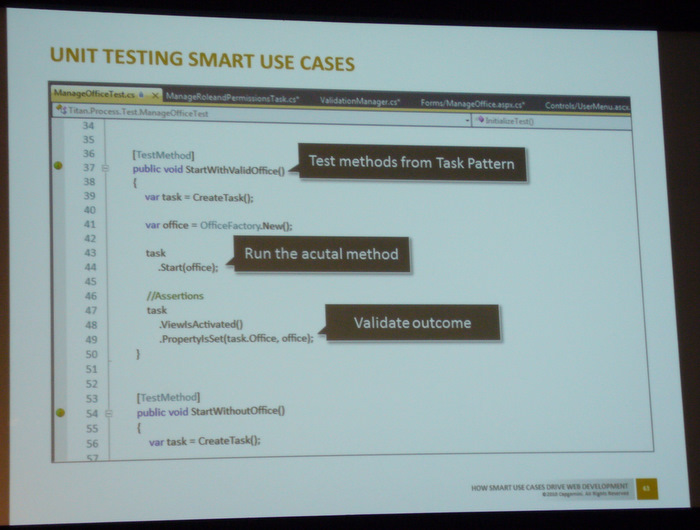
Der Vortrag hatte für die Zeitdauer ein bißchen viel Material, deswegen war es ein wenig hektisch beim Galopp durch die Themen. Allerdings enthält die Webseite noch einiges andere interessante Material, so daß sich hier eine kleine Webrecherche lohnt.
Die Veranstaltung ist beendet
Tja, letzter Vortrag. Das war’s dann mit 3 Tagen teched, mit zudem relativ langen Tagen – die erste Session begann um 09:00 und Ende der letzten Session war um 19:00. Das Programm ist sehr vielseitig, sowohl dem Office-Administrator als auch einem SQL-interessierten fällt es hier sehr leicht 3-4 Tage zu verbringen und viele Informationen zu sammeln. Die Gesprächsmöglichkeiten mit Entwicklern und Produkt-Verantwortlichen für individuelle Fragen seien an dieser Stelle ebenfalls noch mal erwähnt.
Es ist Zeit, mein Zug nach Frankfurt fährt gleich ab - um 13:37.
-
Marc++us schrieb:
um 13:37.
