Intel ISTEP 2011 Software Conference (Teil I)
-
Intel ISTEP Software Conference: Dubrovnik, 12. April 2011

Auch in diesem Jahr veranstaltete Intel seine Software Conference zur Vorstellung der aktuellen Entwicklungstools und –tendenzen auf den Intel-Prozessoren. 70 Teilnehmer (Reseller, einige Fachzeitschriften und technische Blogger) trafen dabei auf ungefähr 10 Intel-Spezialisten. In diesem Artikel fasse ich einige der Vorträge ( http://www.softwareproductconference.com/Dubrovnik_press.aspx?page=agenda1 ) zusammen.
Wenig verwunderlich, das Vorjahr deutete es schon an, es bleibt alles weiter parallel. Intel setzt bei seinen Entwicklungstools stark auf C++ als Programmiersprache (obwohl ihnen Fortran ebenfalls sehr wichtig ist). Und ein Compiler alleine macht noch keinen Sommer, bei den Debugging- und Profiling-Tools tut sich wirklich einiges, um parallele Programmierung einfacher nutzbar zu machen.
 Intels Aaron Coday stellte in zunächst noch einmal den aktuellen Stand der Intel-Prozessor-Hardware zusammenfassend dar, wie er in der 2nd Generation Intel Processor Family abgebildet ist. Aus Sicht der Parallelprogrammierung besonders interessant sind die Advanced Vector Extensions (AVX), die als Erweiterung von SSE nun mit 256 Bit großen Vektoren umgehen kann, Datenmaskierung und –permutation anbietet und 3-Operanden-Operationen auf diesen Vektoren anbietet. Wer sich mit Signalprozessoren auskennt wird hier das „Multiply and Accumulate“ wiedererkennen.
Intels Aaron Coday stellte in zunächst noch einmal den aktuellen Stand der Intel-Prozessor-Hardware zusammenfassend dar, wie er in der 2nd Generation Intel Processor Family abgebildet ist. Aus Sicht der Parallelprogrammierung besonders interessant sind die Advanced Vector Extensions (AVX), die als Erweiterung von SSE nun mit 256 Bit großen Vektoren umgehen kann, Datenmaskierung und –permutation anbietet und 3-Operanden-Operationen auf diesen Vektoren anbietet. Wer sich mit Signalprozessoren auskennt wird hier das „Multiply and Accumulate“ wiedererkennen.Die Intel-Compiler erzeugen natürlich für AVX passenden Code, allerdings beherrschen auch die Microsoft Compiler diese Möglichkeit bereits.
In den Prozessoren ist auch eine GPU integriert. Für Highend-Anwendungen und Spiele ist diese nicht geeignet, aber für viele gängige Desktop-Systeme reicht sie aus. Da sie im inneren Kern des Prozessors integriert ist, kann sie gemeinsam mit der CPU auf den L3-Cache zugreifen und mit ihr Daten austauschen. Damit ergeben sich natürlich noch einmal neue Möglichkeiten der Hardwarebeschleunigung. Dafür stellt Intel eine Schnittstelle mit den Namen Intel Media SDK zur Verfügung. Ein Vorteil davon soll sein, daß unter der gleichen Schnittstelle auch künftige CPUs automatisch nutzbar sein werden.Dualcore wird bald schon abgelöst
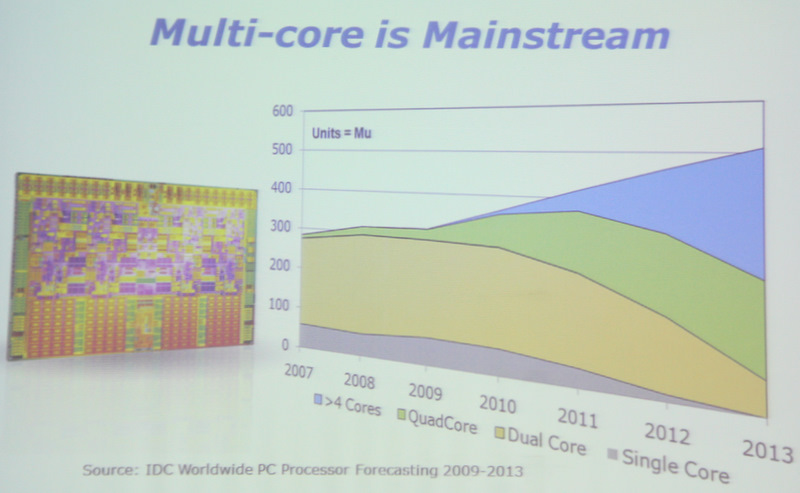
Basierend auf den im Bild gezeigten Zahlen sind in 2011 bereits 50% der insgesamt gelieferten 430 Millionen Prozessoren Dualcore-Systeme, Singlecore verschwindet. Das gleiche Schicksal soll demnach bis 2013 auch Dualcore erfahren, man geht dann von 30-35% Quadcore- und rund 50% „Mehr als Quadcore“-Systemen aus.
Intel hat letztes Jahr seinem Parallel Studio ein Facelift verpasst und brachte im November die Version 2011 ins Rennen –
 wie James Reinders, Chief Evangelist für Intels Softwareprodukte, im Anschluß erläuterte. Besonders stolz ist Reinders auf die Performance des Fortran-Compilers, der den schnellsten Fortran-Code erzeuge, den man jemals gesehen habe. Für uns C++-ler schwer vorstellbar, aber in der Fortran-Welt gibt es eine große Anzahl an (funktionierenden) mathematischen Bibliotheken, die niemand mehr portieren will. Oder sich traut. Um hier zu beschleunigen, geht der Weg nur über bessere Compiler, die aus dem alten Code schnellere Programme übersetzen.
wie James Reinders, Chief Evangelist für Intels Softwareprodukte, im Anschluß erläuterte. Besonders stolz ist Reinders auf die Performance des Fortran-Compilers, der den schnellsten Fortran-Code erzeuge, den man jemals gesehen habe. Für uns C++-ler schwer vorstellbar, aber in der Fortran-Welt gibt es eine große Anzahl an (funktionierenden) mathematischen Bibliotheken, die niemand mehr portieren will. Oder sich traut. Um hier zu beschleunigen, geht der Weg nur über bessere Compiler, die aus dem alten Code schnellere Programme übersetzen.Das Parallel Studio 2011 von Intel gibt es in 3 unterschiedlichen Versionen:
Zum einen die normale Version für C- und C++-Entwickler, die eine verbesserte Unterstützung der Multicore-Entwicklung und des parallelen Profilings bietet. Das Parallel Studio 2011 XE enthält zusätzlich auch die Fortran-Unterstützung und Optimierungstools wie den Intel VTune Analyzer XE, um Optimierungspotentiale für Parallelprogrammierung in Programmen zu analysieren. Das Intel Cluster Toolkit dient der Entwicklung von verteilten Anwendungen auf HPC-Systemen (HPC = High Performance Cluster). Die Tools sind für Windows und Linux erhältlich, und die C- und C++-Compiler – übrigens mit der Versionsnummer 12 - lassen sich unter Windows auch in Microsofts Visual Studio 2010 integrieren. Natürlich ebenso auch in die Version 2008.
AMD und Intel
Bekanntermaßen sind AMD und Intel Konkurrenten. Da Reinders aber zur Softwareabteilung von Intel gehört, steht bei ihm weniger der Konkurrenzgedanke bei der Hardware im Vordergrund, sondern mehr die Frage, wie gut „seine“ Software-Tools mit der AMD-Hardware klarkommen.
Dem Aspekt „Benchmarks“ widmete Reinders daher viel Aufmerksamkeit Ein Geschwindigkeitsgewinn bei Benchmarks (SPECfp_base2006 und SPECint_base2006) gegenüber den nächstbesten C++-Compilern von Microsofts Visual C++ und dem gcc von 70% beziehungsweise 20% soll erzielbar sein – selbst gegenüber der Intel-Vorgängerversion 11.1 ergeben sich noch einmal Zuwächse von 10 bis 30%. Das sollte nicht unbedingt verwunden, wenn der Prozessorhersteller selbst Entwicklungstools erstellt. Überraschend waren dagegen die vorgestellten Zahlen, wie sich Intels Compiler auf AMD-Systemen bewährt.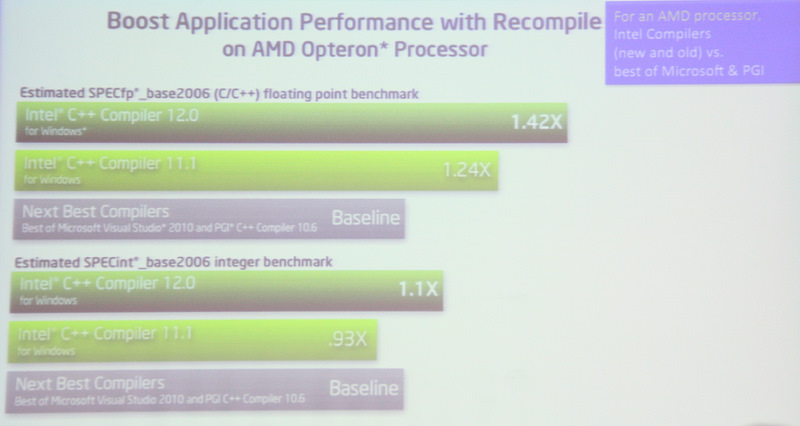
Zwar erreicht der Intel-Compiler auf AMD-Plattformen nicht ganz den Geschwindigkeitsvorteil gegenüber den Wettbewerbern Microsoft und gcc wie auf einer Intel-Plattform, trotzdem wären nach Reinders mit dem aktuellen Intel-Compiler immer noch rund 40% bei den Fließkomma- und 10% bei den Integer-Benchmarks festzustellen. Laut Reinders sollte man also auch auf AMD-Plattformen besser mit dem Intel-Compiler entwickeln.
C++, Templates, Multi-Threading
Auch in Bezug auf die Bibliotheken für Parallelprogrammierung gibt es laut Reinders zahlreiche Änderungen. Die bereits früher eingeführte Technologie Cilk (in „Parallelism is here to stay“) ist als Cilk Plus im aktuellen Parallel Studio enthalten, und Threading Building Blocks (TBB) kletterte inzwischen auf Version 3.0.
TBB 3.0 ist eine Bibliothek für Parallelprogrammierung unter C++, die sich stark auf Templates abstützt. Seit der Version 3.0 können auch Sprachfeatures von C++0x eingesetzt werden – speziell hier die Lambda-Ausdrücke. Die Bibliothek liegt als Open Source-Version vor und kann für Linux und Windows eingesetzt werden, wobei sie sich auch in Microsofts Visual Studio integrieren lässt.
Unter dem Arbeitstitel „Ct“ hat Intel bereits im Vorjahr eine Bibliothek für parallelisierte Daten vorgestellt, diese liegt nun als Intel Array Building Blocks vor. Diese hat allerdings wohl noch einige kleine Hacken, so arbeitet sie in bestimmten Fällen wohl extrem performant, wenn man aber dann im Code kleine Umstellungen vornimmt kann sie in der Geschwindigkeit zusammenbrechen. Hier ein gutmütigeres Verhalten zu erreichen ist wohl ein wesentliches Entwicklungsziel der nächsten Monate laut Reinders.
Zum Jahreswechsel soll dies dann zusammen mit einer Version von TBB 4.0 zu Intel Parallel Building Blocks (PBB) zusammengefasst sein. Intel Threading Building Blocks | ISBN: 0596514808Zu diesem Zeitpunkt wird dann auch wieder ein Buch von Reinders erscheinen, zu Threading Building Blocks gibt es ja bereits einen Titel im O’Reily-Verlag.
Eine wichtige Aussage gab James Reinders den Zuhörern noch mit auf den Weg, warum sie bei der Parallelprogrammierung besser Bibliotheken einsetzen und nicht auf native Lösungen ausweichen sollen- egal ob POSIX oder Winthreads: nur bei Bibliotheken, deren Komponenten in sich abgestimmt sind, wird man auch geeignete Profiling- oder Analysetools finden, um die Programme zu verbessern. Das ist natürlich ein guter Punkt, trotz des Marketingarguments, denn wenn man Parallelprogrammierung aus diversen Einzelteilen von Hand zusammensetzt, kann leicht eine Überbestimmtheit herauskommen: wer garantiert, daß der Threadpool und das
parallel_forund der Algorithmus für parallele Datenverarbeitung auf der Multicore-CPU sich nicht gegenseitig die Ressourcen streitig machen? Und daß das Programm im Endeffekt langsamer läuft? Hier sieht Reinders einen Vorteil bei Intel, egal wie man Intel-Bibliotheken mischt, sollen diese im Hintergrund mit all diesen Lastanforderungen ausgewogen umgehen.Trotzdem arbeitete und arbeitet Intel anscheinend auch hart daran, daß seine Komponenten kompatibel zu anderen Compilern, Herstellerbibliotheken und Laufzeitumgebungen sind. Ein Beispiel ist die Austauschbarkeit von OpenMP zwischen Intel, dem gcc und Microsofts Implementierung. Ebenfalls gab es in der Vergangenheit immer wieder Probleme mit multithreadingfähigen Laufzeitbibliotheken der unterschiedlichen Compiler, wenn diese Laufzeitbibliothek zur Synchronisation unterschiedliche Mechanismen einsetzt, kann es zu Fehlern oder Programmabstürzen kommen. Angeblich wurden hier beim gcc und Microsofts Visual C++ hier entscheidende Fortschritte bei der „Durchmischbarkeit“ gemacht.