Binärdaten aus Datei einlesen
-
Hi(gh)!
So ist das halt, wenn man nur alle paar Monate mal für ein oder zwei Tage dazu kommt, sich mit einer Programmiersprache zu beschäftigen...
Ich will aus einer kleinen (40 Bytes) Test-Datei mit unkomprimierten headerlosen Audiodaten 10 Sample-Werte im Format signed int (Little-Endian) auslesen... leider finde ich nirgendwo die dazu passende Methode von ifstream!
get() ist es jedenfalls nicht, da dürfen nur char-Variablen verwendet werden, dieser Code hier:
bool loadRAW(vector<int> &smp, string filename) { ifstream Source; int val; Source.open(filename.c_str(), ios::binary); if (!Source) { cerr << filename << " cannot be opened!\n"; return false; } while (Source.get(val)) smp.push_back(val); return true; }produziert beim Versuch, ihn zu kompilieren jedenfalls nur eine furchterregend riesenlange Latte von Fehlermeldungen, die mir wie schon ungezählte Male zuvor vor Augen führen, was für ein komplett ahnungsloser Trottel ich doch bin...
Bis bald im Khyberspace!
Yadgar
-
Was ist denn die Compiler Fehlermeldung?
Ohne das jetzt testen zu können, würde ich sowas versuchen:bool loadRAW(vector<int> &smp, string filename) { ifstream Source; int val; Source.open(filename.c_str(), ios::binary); if (!Source) { cerr << filename << " cannot be opened!\n"; return false; } std::copy(std::istream_iterator<int>(Source), std::istream_iterator<int>(), std::back_inserter(smp)); return true; }Wenn das nicht geht, würde ich versuchen mich hier dran http://www.cplusplus.com/forum/general/122330/#msg666557 zu orientieren.
-
Dazu gibt es read, z.B.
Source.read(reinterpret_cast<char*>(&val), 1); // edit: 1 ist falsch, s.u.
-
@Schlangenmensch sagte in Binärdaten aus Datei einlesen:
std::copy(std::istream_iterator<int>(Source), std::istream_iterator<int>(),
std::back_inserter(smp));Das liest aber Klartext, keine Binärdaten.
@Th69 sagte in Binärdaten aus Datei einlesen:
Source.read(reinterpet_cast<char*>(&val), 1);
Wieso 1? Ein LE-int (ich nehme mal int32 an) ist 4 Bytes groß. Außerdem habe ich vor reinterpret_cast Angst.
int32_t value; unsigned char data[sizeof(int32_t)]; while (source.read(data, sizeof(data))) { memcpy(&value, data, sizeof(value)); // das memcpy geht, wenn deine Maschine auch LE ist, // ansonsten mit sowas wie value = data[0] | (data[1]<<8) | (data[2]<<16) | (uint32_t(data[3])<<24); arbeiten* std::cout << "Gelesen: " << value << "\n"; }* ich weiß nicht, ob das letzte unsigned da nötig ist, aber sicher ist sicher
") - wobei, wenn ichs mit recht überlege, müsste man doch bei den anderen Shifts auch zumindest sicherstellen, dass sie in einen int passen - falls deine Maschine int=int16_t hat, ginge data[2]<<16 ohne Cast schon nicht.
- wobei, wenn ichs mit recht überlege, müsste man doch bei den anderen Shifts auch zumindest sicherstellen, dass sie in einen int passen - falls deine Maschine int=int16_t hat, ginge data[2]<<16 ohne Cast schon nicht.Noch was:
ifstream Source; (...) Source.open(filename.c_str(), ios::binary);Warum nicht einfach
ifstream sourcefile(filename, ios::binary);- kein nutzloses.c_str()und alles in einer Zeile.
-
@wob, da hast du Recht, muß natürlich
Source.read(reinterpret_cast<char*>(&val), sizeof(int));lauten (man kann auch einen einfachen C-Cast hier benutzen, aber in C++ Code sollte man diesen ja vermeiden).
Und dein Code ist ja noch umständlicher (warum erst einen anderen Puffer verwenden und dann umkopieren?).
PS: Und bzgl. Endianess bin ich davon ausgegangen, daß LE (x32, x64) verwendet wird.
Ansonsten kann man ja auch noch nachträglich die Bytes swappen (z.B.htonl).
-
@Th69 sagte in Binärdaten aus Datei einlesen:
Und dein Code ist ja noch umständlicher (warum erst einen anderen Puffer verwenden und dann umkopieren?).
Damit ich sicher bin, dass ich kein undefiniertes Verhalten habe.
-
Bei meinem Code gibt es kein UB, das gibt es ja auch als Beispiel im Link.
-
Hi(gh)!
@Th69 sagte in Binärdaten aus Datei einlesen:
@wob, da hast du Recht, muß natürlich
Source.read(reinterpret_cast<char*>(&val), sizeof(int));Das hat perfekt funktioniert! Danke, Th69 und wob... rechnet schonmal damit, dass demnächst im Khyberspace zwei bislang namenlose Viertausender im Mittleren Hindukusch nach euch benannt werden! Koh-e Wob, das klingt doch cool, oder?
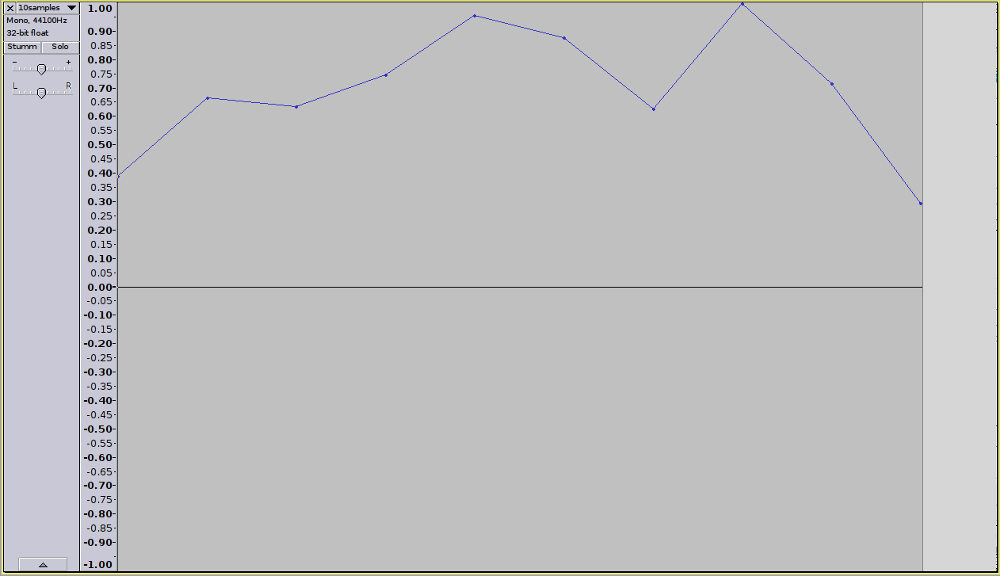
Auch die Ausgabe fördert ziemlich genau das zutage, was ich erwartet habe:
Value #0: 834527424 Value #1: 1426715008 Value #2: 1363809664 Value #3: 1600095488 Value #4: 2050849408 Value #5: 1882493696 Value #6: 1344495744 Value #7: 2143818880 Value #8: 1536834176 Value #9: 632175360Zum Vergleich die Darstellung der Testdatei in Audacity...
Bis bald im Khyberspace!
Yadgar
-
@Yadgar sagte in Binärdaten aus Datei einlesen:
Hi(gh)!
rechnet schonmal damit, dass demnächst im Khyberspace zwei bislang namenlose Viertausender im Mittleren Hindukusch nach euch benannt werden! Koh-e Wob, das klingt doch cool, oder?
Bis bald im Khyberspace!Boah, was ein Schwachsinn.
-
Source.read(reinterpret_cast<char*>(&val), sizeof(int));Damit ich sicher bin, dass ich kein undefiniertes Verhalten habe.
Wenn val nicht vom Typ
char signed char unsigned char voidist, ist es UB;
da helfen auch keine obskuren C++ Typecasts mehr.
-
@Wutz Du redest Blödsinn. Wieder.
-
@Swordfish
Und du kennst den C Standard nicht - redest aber trotzdem immer wieder darüber.
-
@Wutz sagte in Binärdaten aus Datei einlesen:
Und du kennst den C Standard nicht
Der ist hier in der C++-Gruppe irrelevant. Hier gilt C++-Standard. Dennoch!
Ich hatte das in C++ auch so in Erinnerung wie @Wutz es sagt und habe daher in ein char-Array gelesen. Das ist nämlich auf jeden Fall erlaubt.
Interessant ist aber, dass cppreference den reinterpret_cast hier https://en.cppreference.com/w/cpp/io/basic_istream/read im Beispiel verwendet. Daher habe ich mich gefragt, ob es irgendwo eine Spezialregel gibt, die das dennoch erlaubt.
Aber egal, habe ich mir gedacht, ich lese einfach in das char-Array und bin damit auf der sicheren Seite.
-
@Wutz sagte in Binärdaten aus Datei einlesen:
Source.read(reinterpret_cast<char*>(&val), sizeof(int));Damit ich sicher bin, dass ich kein undefiniertes Verhalten habe.
Wenn val nicht vom Typ
char signed char unsigned char voidist, ist es UB;
Stimme ich nicht zu. Weil wir hier die object representation eines (gueltigen) int Werts in ein neues int Objekt "kopieren". [basic]:
For any object (other than a potentially-overlapping subobject) of trivially copyable type
T, whether or not the object holds a valid value of typeT, the underlying bytes ([intro.memory]) making up the object can be copied into an array ofchar,unsigned char, orstd::byte([cstddef.syn]). If the content of that array is copied back into the object, the object shall subsequently hold its original value.Der "juristische" Knackpunkt liegt eben darin, ob
istream::readals Kopierfunktion betrachtet wird, oder nicht. P0593 scheint hier anzudeuten, dass memcpy und memmove, die beide in Bezug auf den obigen Paragraph parenthetisch erwaehnt werden, eine Sonderrolle einnehmen (wobei das 100%-ig noch weiter gelockert wird). Das aendert aber nichts an der Praxis, in der solcher Code gerne auch mal seine eigenen Funktionen einsetzt. Und 'juristisch' betrachtet wird eben in diesem Paragraphen von keiner konkreten Funktion gesprochen.Eine sauberere Variante waere sicherlich,
readauf einstd::byteArray anzuwenden, und dieses permemcpyin einenintzu kopieren. Da wird jeder Compiler auch den gleichen Code erzeugen.
-
@Columbo
Ich glaube das mitmemmove& Co in P0593 ist für Fälle gedacht wo im Ziel der Kopieroperation noch keinTexistiert und auch keine Operation vorangeht die implizit Objekte erzeugen würde.Also z.B. sowas
void fun(void* t, void* u) { unsigned char buf[1234]; memcpy(buf, t, sizeof(T); T* t2 = reinterpret_cast<T*>(buf); t2->foo(); // OK ohne die Spezialregel weil das Erzeugen des Arrays "buf" hier implizit Objekte erzeugt memcpy(buf, u, sizeof(U); U* u2 = reinterpret_cast<T*>(buf); u2->zooStation(); // ohne die Spezialregel nicht OK - das Erzeugen von "buf" hat hier implizit // magisch ein für oben passendes T erzeugt, aber halt kein U }Wenn ein passendes Objekt schon existiert, dann sollte der von dir zitierte Paragraph ausreichend sein. Die Frage ist dann wirklich nur noch was man unter Kopieren von Speicher versteht. MMn. sollte da auch das "manuelle" Kopieren mittels
char/unsigned char/std::byteZeiger gelten. Denn sonst hat einfach verdammt viel Code undefiniertes Verhalten.
-
@hustbaer sagte in Binärdaten aus Datei einlesen:
Denn sonst hat einfach verdammt viel Code undefiniertes Verhalten.
Genau. P0593/P0137 sind auch lediglich ein Versuch des Komitees, die Luecke zwischen Standard und de facto Praxis zu schliessen. Das geschieht aber unweigerlich ausgehend von der Praxis, weshalb @Wutz's Kommentar hier doppelt falsch ist (sowohl von der juristischen als anwendenden Perspektive). Der Standard dient primaer als Abstraktion etablierter Praxis, welche im Falle von object lifetime semantics so vielgestaltig ist. Gerade weil C++ eben als maschinennahe Sprache angewandt wird, das Typsystem so leicht zu umgehen ist, und Compiler in vielen Faellen tun was man erwartet (auch wenn diese Faelle ggf. nicht definiert sind oder intendiert sind), war es ja von vornherein klar, dass jeder herumcastet und macht was er will, und die standardisierte Sprache das 20 Jahre spaeter ausbuegeln darf.
-
Ich hab mal ausprobiert was aktuelle Compiler sich da an Optimierungen wirklich trauen.
#include <stddef.h> struct Foo { int x; }; struct EightBits { unsigned char bits : 8; }; #if 1 using X = char; #else using X = EightBits; #endif void fun(int* arr, Foo* foo, void* mightAliasFoo) { arr[0] = foo->x; X* f = static_cast<X*>(mightAliasFoo); for (int i = 0; i < sizeof(Foo)/sizeof(X); i++) f[i] = {}; arr[1] = foo->x; }https://godbolt.org/z/E4jK1qdW8
MSVC, ICC, ICX und Clang sind feige, und erzeugen in beiden Fällen ein 2. Load für
arr[1] = foo->x. GCC 10 ist mutiger und erzeugt das 2. Load nur mitX = charaber nicht mitX = EightBits.Auf jeden Fall erzeugen alle Code der funktioniert so lange man halt
char(oderunsigned charoderstd::byte) zum Kopieren/Überschreiben verwendet.
{kind=link}