OpenCL oder: Berechnungen optimieren
-
Nein, geht um meine 2D Library.
Und keine Partikel sondern ordinäre Sprites oder auch Quads, das sind 6 Vertices pro Sprite, 2 Triangles.
Und um diese Berechnung:void NLBoundingBox::applyTransform(NLVertexData* vertices) { if ( needsTransform() ) { // Apply Matrix for ( int i=0; i<6; i++ ) { glm::vec4 transformed = m_rotation * m_translation * glm::vec4(vertices[i].x, vertices[i].y, 0, 1.0f); vertices[i].x = transformed.x; vertices[i].y = transformed.y; } m_translation = glm::mat4(1); m_rotation = glm::mat4(1); m_needsTransform = false; } }
-
lohnt sich vermutlich nicht sowas zu optimieren, wenn man beim zeichnen von denen nicht gpu und nicht memory-transfer bound is, dann muss man schon was falsch machen.
btw. scheint als ob du 4x4 matrizen zusammenmultiplizierst und dann noch einen 4d vector transformierst, diese 80mul und 48 adds waeren low hanging fruites im vergleich zur gpu optimierung.
-
Scorcher24 schrieb:
Und keine Partikel sondern ordinäre Sprites oder auch Quads, das sind 6 Vertices pro Sprite, 2 Triangles.
Wie gesagt: GeometryShader oder Instancing. OpenCL würd sich auf die Performance da vermutlich sogar noch eher negativ auswirken...
-
rapso schrieb:
lohnt sich vermutlich nicht sowas zu optimieren, wenn man beim zeichnen von denen nicht gpu und nicht memory-transfer bound is, dann muss man schon was falsch machen.
btw. scheint als ob du 4x4 matrizen zusammenmultiplizierst und dann noch einen 4d vector transformierst, diese 80mul und 48 adds waeren low hanging fruites im vergleich zur gpu optimierung.
Hmm, ja da tue ich mich ehrlich gesagt noch schwer das zu erkennen woran es hapert. Bei 50.000 dieser Sprites ist momentan absolut schluss, da gibts schon Frameprobleme. Im gDebugger ist aber nicht wirklich ersichtlich woran es liegt. CPU ist aber nicht ausgelastet. Viele Vertices sind es auch nicht. 50.000 * 6 = 300.000 Vertices. Das ist eigentlich lächerlich^^. Heutige Spiele präsentieren weit mehr.
Und ich arbeite auch mit glMapBuffer und es wird kein Speicher angefordert während des Renderings, solange keine neuen Objekte erzeugt werden.void NLSpriteBatcher::update(u32 delta, u32 time) { if ( m_vao == 0 || m_vbo == 0 ) this->createBatch(); // Bind glBindBuffer(GL_ARRAY_BUFFER, m_vbo); if (m_vboNeedsRefresh) { // Update data NLVertexData* data = createData(delta, time); // Send Vertex data glBufferData(GL_ARRAY_BUFFER, 6*m_list.size()*sizeof(NLVertexData), data, GL_DYNAMIC_DRAW); m_vboNeedsRefresh = false; } else { // Map VRAM to virtual NLVertexData* map = static_cast<NLVertexData*>(glMapBuffer(GL_ARRAY_BUFFER, GL_WRITE_ONLY)); if ( map == NULL ) { throw NLException("Cannot map VBO!", true); return; } u32 i = 0; TSpriteList::iterator it = m_list.begin(); for ( it; it != m_list.end(); it++ ) { NLBaseSprite& sprite = (*it); // Tell the sprite its offset sprite.tellMapPtr(&map[i]); // Update Sprites sprite.update(delta, time); // Reset offset. sprite.tellMapPtr(NULL); // Increase Counter i += 6; } // Unmap Buffer if ( glUnmapBuffer(GL_ARRAY_BUFFER) == GL_FALSE ) { throw NLException("Error unmapping Buffer!"); } } // Unbind glBindBuffer(GL_ARRAY_BUFFER, 0); }
-
Scorcher24 schrieb:
Hmm, ja da tue ich mich ehrlich gesagt noch schwer das zu erkennen woran es hapert. Bei 50.000 dieser Sprites ist momentan absolut schluss, da gibts schon Frameprobleme.
wieviel fps?
Im gDebugger ist aber nicht wirklich ersichtlich woran es liegt. CPU ist aber nicht ausgelastet. Viele Vertices sind es auch nicht. 50.000 * 6 = 300.000 Vertices.
wie gross ist ein vertex? ich rate mal es sind 24byte.
du hast also realistisch eventuel 1GB/s upstream zur GPU, nur fuer die vertex daten waere es also
1GB/24Byte/300000 -> 150fps
(du musst bedenken, dass du auch eine gewisse zeit brauchst um die 1GB an daten zur zu ziehen und danach rauszuschreiben, 150fps also wenn du nichts anderes machen wuerdest als transfer via PCIe).sagen wir mal du hast eine GPU mit 20GigaPixel fillrate und jedes sprite ist 64x64 pixel?
20G/64/64/300000 -> 16fpswenn ich mich nicht verrechnet habe.
-
Wenn du (wie ich) den Mathe-Teil (Matrizen, Vektoren, ...) selbst programmierst, kannst du mit der Sprache C++ ein wenig spielen:
Wenn bei meinem Framework eine Matrix (die nur transliert wurde) mit einem Vektor multiplizierst, führt der Operator genau zwei Additionen durch. Im Gegenzug dafür ist jede Matrix-Klasse ein Byte grösser als die "traditionelle" Implementierung.
-
rapso schrieb:
Scorcher24 schrieb:
Hmm, ja da tue ich mich ehrlich gesagt noch schwer das zu erkennen woran es hapert. Bei 50.000 dieser Sprites ist momentan absolut schluss, da gibts schon Frameprobleme.
wieviel fps?
Im gDebugger ist aber nicht wirklich ersichtlich woran es liegt. CPU ist aber nicht ausgelastet. Viele Vertices sind es auch nicht. 50.000 * 6 = 300.000 Vertices.
wie gross ist ein vertex? ich rate mal es sind 24byte.
du hast also realistisch eventuel 1GB/s upstream zur GPU, nur fuer die vertex daten waere es also
1GB/24Byte/300000 -> 150fps
(du musst bedenken, dass du auch eine gewisse zeit brauchst um die 1GB an daten zur zu ziehen und danach rauszuschreiben, 150fps also wenn du nichts anderes machen wuerdest als transfer via PCIe).sagen wir mal du hast eine GPU mit 20GigaPixel fillrate und jedes sprite ist 64x64 pixel?
20G/64/64/300000 -> 16fpswenn ich mich nicht verrechnet habe.
Sind 36 bytes, 9 floats.
xyz Vertices
rgba Farbe
st TexturcoordsUnd es sind 5 frames atm bei 50.000.
Meine Grafikkarte ist eine HD4890.
Aber ich denke für massen brauche ich PointSprites.
Ich finde momentan nur iwie keinen guten Artikel dazu, der die versch. nötigen Funktionen dazu beleuchtet.EOutOfResources schrieb:
Wenn du (wie ich) den Mathe-Teil (Matrizen, Vektoren, ...) selbst programmierst, kannst du mit der Sprache C++ ein wenig spielen:
Wenn bei meinem Framework eine Matrix (die nur transliert wurde) mit einem Vektor multiplizierst, führt der Operator genau zwei Additionen durch. Im Gegenzug dafür ist jede Matrix-Klasse ein Byte grösser als die "traditionelle" Implementierung.Wie ich oben bereits schrieb: Ich nutze glm, das ist gegen den GLSL Spec geschrieben und warum soll ich mir die arbyte machen die sich wer anders schon gemacht hat?
-
Verwendest du auf deinen Sprites Alphatesting/blending oder sonstigen Kram? Ich denke was rapso mit seiner Rechnung zeigen wollte war dass die Transformation auf der CPU garnicht unbedingt dein Problem ist...
-
dot schrieb:
Verwendest du auf deinen Sprites Alphatesting/blending oder sonstigen Kram? Ich denke was rapso mit seiner Rechnung zeigen wollte war dass die Transformation auf der CPU garnicht unbedingt dein Problem ist...
Blending verwende ich für Text, aber wennn ich den in der Testszene rausnehme ändert sich auch nicht viel an den FPS.
Alphatesting im Shader:#version 330 //---------------------------------------------- // Layout Vars //---------------------------------------------- layout(location = 0) in vec3 NL_Vertex; layout(location = 1) in vec4 NL_Color; layout(location = 2) in vec2 NL_TextureCoord; //---------------------------------------------- // Uniforms from NightLight //---------------------------------------------- uniform mat4 NL_ProjectionMatrix; //---------------------------------------------- // Output to fragment shader //---------------------------------------------- smooth out vec4 theColor; smooth out vec2 theTextureCoord; void main() { //---------------------------------------------- // Applying position //---------------------------------------------- gl_Position = NL_ProjectionMatrix*vec4(NL_Vertex, 1.0); //---------------------------------------------- // Output //---------------------------------------------- theColor = NL_Color; theTextureCoord = NL_TextureCoord; }#version 330 uniform sampler2D NL_TextureID; smooth in vec4 theColor; smooth in vec2 theTextureCoord; out vec4 outputColor; void main() { vec4 value = texture2D(NL_TextureID, theTextureCoord); if ( value.a <= 0.01 ){ discard; } outputColor = value; }Ich denke was rapso mit seiner Rechnung zeigen wollte war dass die Transformation auf der CPU garnicht unbedingt dein Problem ist...
Das habe ich schon verstanden :).
-
D.h. du verwendest diesen Alphatestingshader auf sämtlichen Sprites? Render mal ohne Alphatesting und schau dir die Performance dann an
")
-
Also aktuell transformiere ich 640x480 Punkte zweimal mit libEigen auf der CPU und zeichne sie danach als GL_POINT mit OpenGL und das 10-15 mal pro Sekunde. Zeichne ich nur ein Viertel der transformierten Punkte läuft das sogar mit 60fps und recht geringer CPU Auslastung.
von http://eigen.tuxfamily.org/index.php?title=Main_Page
Eigen is fast.
* Expression templates allow to intelligently remove temporaries and enable lazy evaluation, when that is appropriate.
* Explicit vectorization is performed for SSE 2/3/4, ARM NEON, and AltiVec instruction sets, with graceful fallback to non-vectorized code.
* Fixed-size matrices are fully optimized: dynamic memory allocation is avoided, and the loops are unrolled when that makes sense.
* For large matrices, special attention is paid to cache-friendliness.
-
Scorcher24 schrieb:
Sind 36 bytes, 9 floats.
xyz Vertices
rgba Farbe
st Texturcoords99fps
")
falls du nicht gerade in HDR renderst, kannst du rgba auch in ein int packen, falls das das bottleneck waere, wuerde es helfen.sagen wir mal du hast eine GPU mit 20GigaPixel fillrate und jedes sprite ist 64x64 pixel?
20G/64/64/300000 -> 16fps
Und es sind 5 frames atm bei 50.000.
Meine Grafikkarte ist eine HD4890.13.6G/64/64/300000/2 wegen alphatest -> 5.53385416fps
(kommt natuerlich noch auf die sprite groesse an, ich denke du wirst ein wenig kleinere als 64x64 haben, weil 5.53 rein theoretischer peak ist.wie dot sagt, versuch mal ohne alphatest zu rendern, ob du dann auf 8 bis 10fps kommst, dann koennte man relativ sicher sein, dass du fillrate limitiert bist und du waerst dir sicher, wofuer du optimieren musst.
du koenntest auch backface culling einschalten und all deine sprites als backfaces submitten. wenn du dann auf 100fps kommst, waere es ziemlich sicher dass das eine fillrate sache ist.
-
Nein, bin nicht Fillrate bound. Ein Shader ohne Alphatesting ergab auch 5FPS. Hätte mich nun stark gewundert, wenn das wirklich sooo viel Performance fressen würde.
Anyway, ich hab mir mal den AMD Code Analyst geladen:
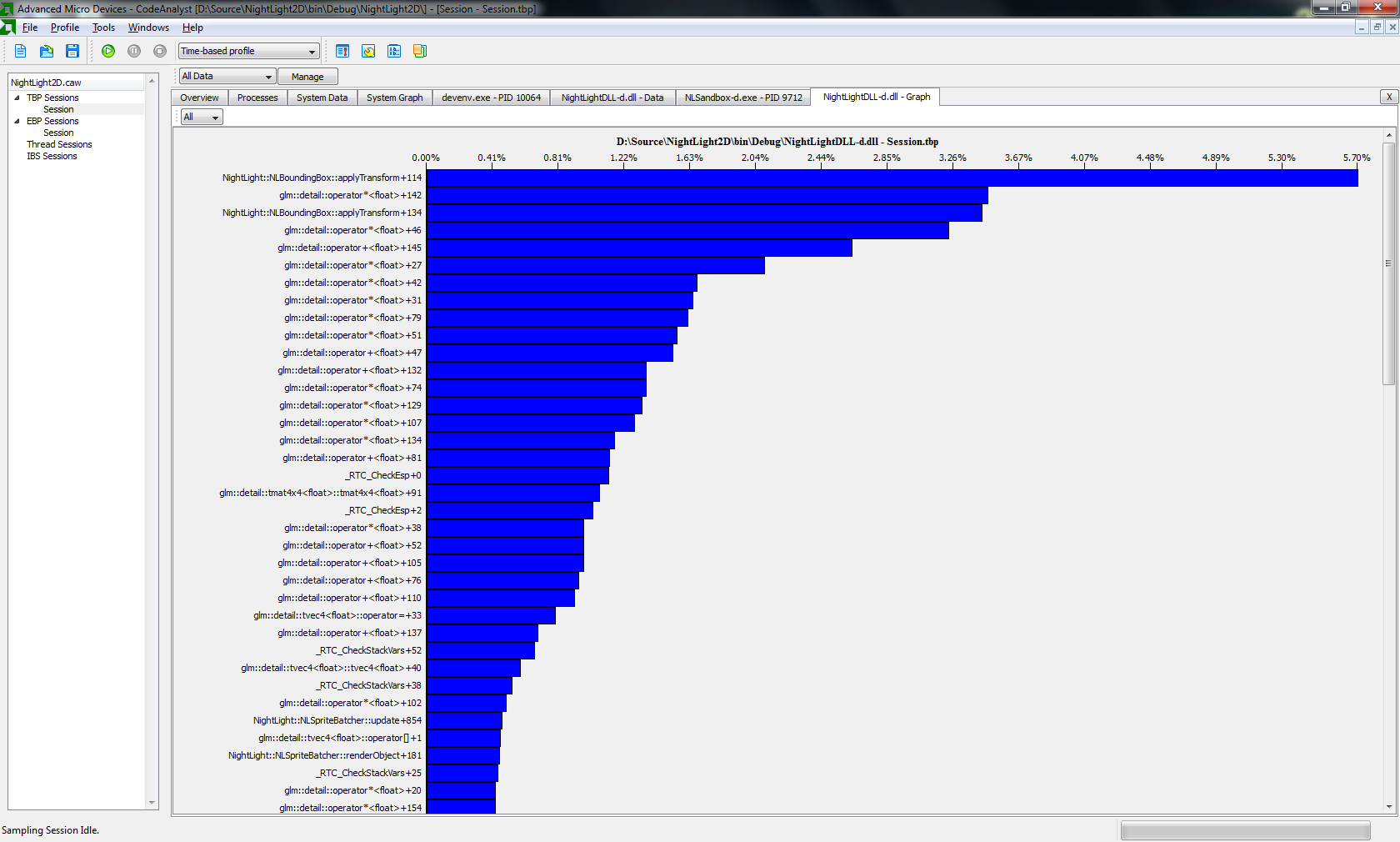
http://developer.amd.com/tools/CodeAnalyst/codeanalystwindows/Pages/default.aspx#downloadDemzufolge ist meine Funktion "applyTransform" tatsächlich die teuerste, wie ich vermutete:
http://h7.abload.de/img/profilerausa.pngWenn ich die Daten richtig interpretiere, nutze das Tool erst seit einigen Stunden.
Hier ein CSV-Export:
http://www41.zippyshare.com/v/22463671/file.htmlhttp://code.google.com/p/nightlight2d/source/browse/NightLightDLL/NLBoundingBox.cpp#130
Hmm, ich denke hier muss was gemacht werden.
Bevor ich OpenCL einbaue, wäre ja noch ne Möglichkeit Threading zu nutzen.
Mein (Test-)Programm nutzt 8 Threads, ich hab keinen einzigen davon explizit angelegt :D. Hab nen Dualcore btw.
Die globale update funktion wird nach dem rendering ausgeführt:
http://code.google.com/p/nightlight2d/source/browse/NightLightDLL/NLSpriteBatcher.cpp#166Dort werden die Sprites updated und eben auch die Transformation gemacht. Die Framerate ist, verständlicherweise, etwas besser ohne VSync. Mit VSync totaler Horror, weil eben SwapBuffers blockiert und in der Zeit nix gemacht wird. Erst nach SwapBuffers läuft die Update-Loop.
Sehe ich das so richtig, dass das Problem ist?
Und wie immer: Vielen Dank für die Hilfe.Edit:
Ich hab hier mal eine Demo hochgeladen:
http://www63.zippyshare.com/v/45025690/file.htmlMan braucht die Visual C++ 2008 Debug Runtime dafür. Debug deswegen, damit mans Profilen kann evtl. Ist aber natürlich kein muss^^.
Wenn ihr den Shader wechseln wollt:
Ihr könnt im Ordner xml in der example.xml den Shader von TestShader austauschen gegen einen der im Ordner Shader ist. Das Format dürfte selbsterklärend sein^^.
-
Ich würde die Transformationen manuell machen. Ich kenne mich mit glm nicht aus, aber 4x4 Matrizen im 2D-Umfeld zu benutzen scheint für mich Verschwendung zu sein.
Das sind ein riesiger Haufen Additionen und Multiplikationen die du schlichtweg nicht brauchst.
Pro Operation (Rotation, Translation) brauchst du 4muls und 4adds in Matrizenform (2x2 Matrizen).
Das sind 8 muls und 8 adds im Vergleich zu deinen.... vielen? Multiplikationen und Additionen die du bisher hast.
Und das kannst du auch noch runterdrücken, wenn du z.B. für die Translation einfach eine Vektoraddition durchführst (mehr brauchst du ja nicht - allerdings bin ich mir grad nicht im klaren, ob du aus irgendwelchen Gründen die Matrizen trotzdem brauchst).
Du schreibst zwar schon, dass du dir die "Arbeit" (die selbstgebauten Vektor und Matrixklassen sind in ner halben Stunde bis Stunde runtergeschrieben, wenn du die Mathematik dahinter kennst - was du tun solltest) nicht machen willst, wenn es schon jemand anderes gemacht hat, aber wenn du starke Optimierungen durchführen willst, dann kommst du da einfach nicht drum rum.
Das sind, wie rapso schon geschrieben hat, wirklich "low hanging fruits".
Außerdem: m_rotation * m_translation solltest du vor die Schleife packen, aber ich denke nicht, dass da im Release-Modus viel dabei rumkommen wird (ich glaube, das können Compiler wegoptimieren).
edit: Haha, grade gesehen: http://stackoverflow.com/questions/6917206/speeding-up-transform-calculations .
Ich schreib das da auch nochmal rein, in Englisch. Falls du meine Antwort aktzeptierst, danke dir für die 15 Punkte

-
TravisG schrieb:
Ich würde die Transformationen manuell machen. Ich kenne mich mit glm nicht aus, aber 4x4 Matrizen im 2D-Umfeld zu benutzen scheint für mich Verschwendung zu sein.
Das sind ein riesiger Haufen Additionen und Multiplikationen die du schlichtweg nicht brauchst.
Pro Operation (Rotation, Translation) brauchst du 4muls und 4adds in Matrizenform (2x2 Matrizen).
Das sind 8 muls und 8 adds im Vergleich zu deinen.... vielen? Multiplikationen und Additionen die du bisher hast.
Und das kannst du auch noch runterdrücken, wenn du z.B. für die Translation einfach eine Vektoraddition durchführst (mehr brauchst du ja nicht - allerdings bin ich mir grad nicht im klaren, ob du aus irgendwelchen Gründen die Matrizen trotzdem brauchst).
Du schreibst zwar schon, dass du dir die "Arbeit" (die selbstgebauten Vektor und Matrixklassen sind in ner halben Stunde bis Stunde runtergeschrieben, wenn du die Mathematik dahinter kennst - was du tun solltest) nicht machen willst, wenn es schon jemand anderes gemacht hat, aber wenn du starke Optimierungen durchführen willst, dann kommst du da einfach nicht drum rum.
Das sind, wie rapso schon geschrieben hat, wirklich "low hanging fruits".
Außerdem: m_rotation * m_translation solltest du vor die Schleife packen, aber ich denke nicht, dass da im Release-Modus viel dabei rumkommen wird (ich glaube, das können Compiler wegoptimieren).
edit: Haha, grade gesehen: http://stackoverflow.com/questions/6917206/speeding-up-transform-calculations .
Ich schreib das da auch nochmal rein, in Englisch. Falls du meine Antwort aktzeptierst, danke dir für die 15 Punkte
You earned a badge:
Stalker :D.Man muss sich auch mal ne 2te Meinung holen :p.
Also glm ist auf SSE optimiert und das kann ich nun wirklich nicht.
4x4 brauch ich, weil ich auch mit z-koordinaten rummache.
Wobei für die z-position eigentlich ne addition reicht. Hmm.
Mal probieren.
Desweitere werde ich mal branchen (dank meinem neuen git ja nun ohne probleme möglich :D) und probieren was passiert wenn ich die Matrizen als Vertex-Attribut mitschicke.
Aber erstmal werde ich 0.0.3 auf den Weg bringen. Nur stürzt mein Shader Editor momentan im Release Modus ab beim starten und im DebugModus nicht -.-.
Gnahh
edit:
Achja, wenn ich Additionen mache zur Positionsveränderung, dann zerhauts mir meine Rotation. Deswegen mache ich beides mit Matrizen, das ist schmerzloser.
-
Ich kann mich nur wiederholen:
dot schrieb:
GeometryShader oder Instancing.
{kind=link}