[gelöst] Vector ist wesentlich langsamer als Array?
-
zeusosc schrieb:
STL vectoren springen häufig durch verschiedene Unterfunktionen,
die die Länge prüfen, ob der Zeiger richtig ist und und und,..
hier wird alloziiert und über maximal zwei ptrs beim zugriff
dereferenziert (und auf das dritte dan referenziert)...
sollte also relativ flink laufen,..Ein std::vector macht genau das gleiche. (Im Releasemodus). Nein, warte, er ist viel schneller als deine Version, weil er den Index nicht testet.
zeusosc schrieb:
* Zum new: ich vermeide es wo ich kann! (hier nutze ich es exakt 1x)
Wird der new operator nicht über den source definiert, so findet
eine (Compiler spezifische) Ersetzung statt, die ich erst zur Laufzeit
sehe. Das will ich nicht!Bitte was?
zeusosc schrieb:
* Cast von 0 nach T* : 0 ist kein Typ.
Sind verschiedene konvertierungsvorschrifften vorhanden,
wird die erste passende vom Compiler genommen. (Meistens basistypen).
Ich will das der Compiler "explizit" 0 als T* behandelt.Ja.. dann nimm nullptr.
")
zeusosc schrieb:
* Cast nach void*: sehe ich jetzt nicht,.. wo?
In Zeile 58.
zeusosc schrieb:
* Index operator [] nicht unsigned: Ja,.. kann man so und so sehen,
"ist übergebene uint > size dann gib referenz" wäre hier wohl
bessere wahl gewesen, da hast du recht...Nein, die bessere Wahl wäre gewesen, den Test einfach nicht zu machen.
zeusosc schrieb:
* this-> bleibt definitiv !!! es ist ein unterschied ob ich eine
Methode der Instanz aufrufe oder eine gleichnamige Funktion aus
dem gleichen Namensraum, geschweige denn Member.
Da der Compiler das so oder so die addy's der Member aus der
Referenzierung des this holt (in asm schön sichtbar), dann
kann ich es auch gleich richtig machen.Was heißt hier "richtig", es macht halt keinen Unterschied, aber das this wegzulassen ist übersichtlicher.
zeusosc schrieb:
Ausserdem ist dann
IMMER klar, WANN ich eine Methode oder Member innerhalb einer
Methode aufrufe,...
(Macht sich besonders bemerkbar wenn intellisense spinnt)Das ist auch so klar. Mehr noch, this-> impliziert, dass diese explizite Schreibweise nötig ist, weil sonst etwas Anderes gemeint wäre. Daher sollte man es meiden, wenn dem nicht so ist.
zeusosc schrieb:
* Einrückung: hä? wie was? wo?
Es gibt ja mal wohl mehrere Varianten von einrückungen...Das hat nichts mehr mit Stil zu tun, das ist einfach falsch bzw. teilweise gar nicht eingerückt.
zeusosc schrieb:
* ";" ?? Meines wissens hat nach jeder abgeschlossenen Anweisung ein ";"
zu folgen. Auch wenn manchen Compilern das wurscht ist....Nein, keinem Compiler ist das egal. Aber leere ; sind jedem Compiler egal, deswegen kompiliert der Code überhaupt. Auf einen Scope muss kein ; folgen. (Und sollte dadurch auch nicht.)
zeusosc schrieb:
nicht viele hauerdrinn,...
Doch, das malloc Gefrickel ist eines der übelsten Sachen die ich seit Langem gesehen habe. Und wenn der Index nicht mehr gültig ist gibt man einfach einen *new T() zurück der nie mehr freigegeben wird?

zeusosc schrieb:
gleich n template mit variabler dim anzahl
basteln. Er nutzt ja mehrere 1d 2d und 3d arrays.,...Das funktioniert nicht. Die Dimensionen sind erst zur Laufzeit bekannt, wären sie zur Compilezeit bekannt, könnte man auch einen std::vector<std::array<...>> nehmen. Daher fällt jegliches Templategezauber weg.
-
Ich hoffe, du schaust nochmal in den Thread rein, auch wenn du das als (warum auch immer) gelöst markiert hast.
Ich habe mal ein wenig Code aus meinem aktuellen Projekt extrahiert und soweit vereinfacht, dass du es mit deinem Kenntnisstand verstehen müsstest. Das ist natürlich so minimal wie möglich, aber es sollte dir schon mal einen deutlichen Speedup geben. Aber du musst noch eine Menge Code hinzufügen, damit das für dein neuronales Netz passt.
Syntaxfehler könnten drin sein, und eventuell hab ich beim Umbauen auch igendwelche variablen vertauscht. Aber diese Fehler dienen dann nur dazu, dass du versuchst, den Code zu verstehen
(jaja, ich bin gerade zu faul zum testen)//stores a matrix in row major format. //as minimal as possible, so it offers only element access via op(): //matrix(i,j)= 10; //and a constructor which takes the dimensionality and a method which returns //the internal block of memory class Matrix{ private: std::vector<float> data; std::size_t rows; std::size_t columns; public: Matrix(std::size_t nRows,std::size_t nColumns) :data(rows*columns),rows(nRows),columns(nColumns){} float& operator()(std::size_t row, std::size_t col){ return data[row*columns+col]; } float operator()(std::size_t row, std::size_t col)const{ return data[row*columns+col]; } std::size_t numRows()const{ return rows; } std::size_t numColumns()const{ return columns; } float const* storage()const{ return &data[0]; } }; //prod(A,b,c) computes c+=A*b //where b,c are vectors and A is a matrix void prod( Matrix const & matA, std::vector<float> const& vecB, std::vector<float& vecC, ){ std::size_t n = matA.numRows(); std::size_t k = matA.numColumns(); //calculate 4 rows at the same time until the remaining number of columns is lower than 4. This saves memory accesses by a factor of 4. std::size_t maxRow=(n/4)*4; std::size_t row=0; while(row!= maxRow){ float* A0 = matA.storage()+row*k; float* A1 = A0+k; float* A2 = A1+k; float* A3 = A2+k; float c0=0; float c1=0; float c2=0; float c3=0; for(std::size_t i = 0; i != k; ++i){ c0+=A0[i]*vecB[i]; c1+=A1[i]*vecB[i]; c2+=A2[i]*vecB[i]; c3+=A3[i]*vecB[i]; } vecC[row]+=c0; vecC[row+1]+=c1; vecC[row+2]+=c2; vecC[row+3]+=c3; row+=4; } //calculate the remaining rows of the result for(;row!=n; ++row){ float* A = matA.storage()+row*k; float c0=0; for(std::size_t i = 0; i != k; ++i){ c0+=A[i]*vecB[i]; } vecC[row]+=c0; } } //benutzung: Matrix m(20,10); std::vector<float> argument(10); std::vector<float> result(20); //some initialization skipped here prod(m,argument,result);hat bei mir im Test mit 512er quadratischen Matrizen ATLAS geschlagen. Aber ich gebe zu, dass ein Datenpunkt alleine da nicht wirklich ausschlaggebend ist
-
@Otze:
Für Matrixprodukt gibt es doch auch ne SSE2 Variante!??@cooky451:
Hi, danke erst einmal das du Dich, auch wenn es etwas Threadfremd ist,
damit beschäftigts... sieh bitte meine antworten nicht als lernunwillig,
sondern als debattenbeitrag...cooky451 schrieb:
zeusosc schrieb:
STL vectoren springen häufig durch verschiedene Unterfunktionen,
die die Länge prüfen, ob der Zeiger richtig ist und und und,..
hier wird alloziiert und über maximal zwei ptrs beim zugriff
dereferenziert (und auf das dritte dan referenziert)...
sollte also relativ flink laufen,..Ein std::vector macht genau das gleiche. (Im Releasemodus). Nein, warte, er ist viel schneller als deine Version, weil er den Index nicht testet.
echt? is natürlich doof (für mich). Ich werde das nachher mal testen...
cooky451 schrieb:
zeusosc schrieb:
* Zum new: ich vermeide es wo ich kann! (hier nutze ich es exakt 1x)
Wird der new operator nicht über den source definiert, so findet
eine (Compiler spezifische) Ersetzung statt, die ich erst zur Laufzeit
sehe. Das will ich nicht!Bitte was?
Ja, new ist ein operator den man gerne überladen kann. Wird im Fall x
kein new operator gefunden, z.b. bei einem Basistyp, nimmt der Compiler
"seine" variante. Das sieht man im trivialsten Fall auch bei
Zuweisungsoperatoren. Die definition solcher sind im sinne eigentlich
überladungen....cooky451 schrieb:
zeusosc schrieb:
* Cast von 0 nach T* : 0 ist kein Typ.
Sind verschiedene konvertierungsvorschrifften vorhanden,
wird die erste passende vom Compiler genommen. (Meistens basistypen).
Ich will das der Compiler "explizit" 0 als T* behandelt.Ja.. dann nimm nullptr.
hmm ja
")
cooky451 schrieb:
zeusosc schrieb:
* Cast nach void*: sehe ich jetzt nicht,.. wo?
In Zeile 58.
//siehe void free ( void * ptr );cooky451 schrieb:
zeusosc schrieb:
* Index operator [] nicht unsigned: Ja,.. kann man so und so sehen,
"ist übergebene uint > size dann gib referenz" wäre hier wohl
bessere wahl gewesen, da hast du recht...Nein, die bessere Wahl wäre gewesen, den Test einfach nicht zu machen.
gut,.. wenn es dem aufrufer obligt diesen test zu machen um eine access
exception zu umgehen...cooky451 schrieb:
zeusosc schrieb:
* this-> bleibt definitiv !!! es ist ein unterschied ob ich eine
Methode der Instanz aufrufe oder eine gleichnamige Funktion aus
dem gleichen Namensraum, geschweige denn Member.
Da der Compiler das so oder so die addy's der Member aus der
Referenzierung des this holt (in asm schön sichtbar), dann
kann ich es auch gleich richtig machen.Was heißt hier "richtig", es macht halt keinen Unterschied, aber das this wegzulassen ist übersichtlicher.
zeusosc schrieb:
Ausserdem ist dann
IMMER klar, WANN ich eine Methode oder Member innerhalb einer
Methode aufrufe,...
(Macht sich besonders bemerkbar wenn intellisense spinnt)Das ist auch so klar. Mehr noch, this-> impliziert, dass diese explizite Schreibweise nötig ist, weil sonst etwas Anderes gemeint wäre. Daher sollte man es meiden, wenn dem nicht so ist.
Also letzendlich wäre das also nur eine Stilfrage? Du sagst: Nutze wenn muss,
lasse wenn kann wegen leserlichkeit...cooky451 schrieb:
zeusosc schrieb:
* Einrückung: hä? wie was? wo?
Es gibt ja mal wohl mehrere Varianten von einrückungen...Das hat nichts mehr mit Stil zu tun, das ist einfach falsch bzw. teilweise gar nicht eingerückt.
sry, aber pro tiefe ein tab,.. für mich ist das eine entsprechende einrückung..
cooky451 schrieb:
zeusosc schrieb:
* ";" ?? Meines wissens hat nach jeder abgeschlossenen Anweisung ein ";"
zu folgen. Auch wenn manchen Compilern das wurscht ist....Nein, keinem Compiler ist das egal. Aber leere ; sind jedem Compiler egal, deswegen kompiliert der Code überhaupt. Auf einen Scope muss kein ; folgen. (Und sollte dadurch auch nicht.)
Da kann ich Dir gerade nicht folgen... Hast Du einen entsprechenden Link?
cooky451 schrieb:
zeusosc schrieb:
nicht viele hauerdrinn,...
Doch, das malloc Gefrickel ist eines der übelsten Sachen die ich seit Langem gesehen habe. Und wenn der Index nicht mehr gültig ist gibt man einfach einen *new T() zurück der nie mehr freigegeben wird?
Da muss ich Dir wiedersprechen:
{ T& foo(void) { return *(new T()); }; void blub(void) { T t; t=foo(); }Was passiert denn am ende der fkt blub? Det Dtor wird aufgerufen und das Objekt
zerstört,...
Das malloc "gefrickel" ist, wie oben erwähnt, die folge das ich kaum ein new benutze,..cooky451 schrieb:
zeusosc schrieb:
gleich n template mit variabler dim anzahl
basteln. Er nutzt ja mehrere 1d 2d und 3d arrays.,...Das funktioniert nicht. Die Dimensionen sind erst zur Laufzeit bekannt, wären sie zur Compilezeit bekannt, könnte man auch einen std::vector<std::array<...>> nehmen. Daher fällt jegliches Templategezauber weg.
[/quote]
Die Dimensionen sind maximal 3-> Schicht, Neuron, gewichte,.. Dynamisch sind
die Anzahl der Schichten, Neuronen und entsprechend Gewichte,...Fazit: ich werde mal n geschwindigkeitsvergleich machen, Vector vs meine Implementation..
grüße
-
zeusosc schrieb:
sieh bitte meine antworten nicht als lernunwillig,
sondern als debattenbeitrag...Ich versuche es, auch wenn es mir schwer fällt.
zeusosc schrieb:
Ja, new ist ein operator den man gerne überladen kann. Wird im Fall x
kein new operator gefunden, z.b. bei einem Basistyp, nimmt der Compiler
"seine" variante. Das sieht man im trivialsten Fall auch bei
Zuweisungsoperatoren. Die definition solcher sind im sinne eigentlich
überladungen....??? Ja, operator new kann man überladen. Das ist ja das tolle. Warum sollte das ein Argument sein new nicht zu benutzen? oO
zeusosc schrieb:
//siehe void free ( void * ptr );Sag ich ja.
Sei T* ein Zeiger auf ein Objekt. (Keine Funktion), dann ist
T* -> void* implizit, benötigt also keinen Cast. (Du nutzt reinterpret_cast.)
void* -> T* ein Fall für static_cast. (Auch hier verwendest du reinterpret_cast.)
Man sollte aber immer den "schwächsten" Cast nutzen, für den das Verhalten noch garantiert ist.
(Weil sich sonst natürlich jeder fragt, warum nutzt der jetzt reinterpret_cast, habe ich was übersehen?)
(Und weil man sonst den eigentlichen Sinn der C++ Casts unterdrückt, nämlich die Absicht mit der Art des Casts zu verbinden, um so viele Fehler wie möglich zur Compilezeit zu bekommen.)zeusosc schrieb:
gut,.. wenn es dem aufrufer obligt diesen test zu machen um eine access
exception zu umgehen...Du hast grundätzlich zwei Möglichkeiten bei einem Operator, oder einer Funktion die einen Fehler nicht durch den Rückgabewert ausdrückt, so etwas zu behandeln:
- Ignorieren und es halt drauf ankommen lassen
- Test und std::out_of_range werfen.
Siehe std::vector operator[] und .at().
Aber einfach ein neues Element zurückzugeben ist völliger Quatsch.zeusosc schrieb:
Also letzendlich wäre das also nur eine Stilfrage? Du sagst: Nutze wenn muss,
lasse wenn kann wegen leserlichkeit...Ja, eine Stilfrage. Aber keine besonders Kontroverse.
zeusosc schrieb:
sry, aber pro tiefe ein tab,.. für mich ist das eine entsprechende einrückung..
Wo ist bei den Zeilen 46, 50-67 bitte pro Ebene ein Tab? oO
zeusosc schrieb:
Da kann ich Dir gerade nicht folgen... Hast Du einen entsprechenden Link?
Die ; in den Zeilen 39, 47, 56, 62, 67, 74, 81, 87, 95, 101, 107, 116, 138, 147 und 158 sind sinnlos und damit sehr hässlich.
zeusosc schrieb:
Da muss ich Dir wiedersprechen:
[...]
Was passiert denn am ende der fkt blub? Det Dtor wird aufgerufen und das Objekt
zerstört,...Argh, du hast das mit der dynamischen Speicherverwaltung (oder dem Destruktor) völlig falsch verstanden. Zähl mal wie viele Objekte erstellt und wie viele zerstört werden: http://ideone.com/5YiqF
zeusosc schrieb:
Die Dimensionen sind maximal 3-> Schicht, Neuron, gewichte,.. Dynamisch sind
die Anzahl der Schichten, Neuronen und entsprechend Gewichte,...Die Größe der Dimensionen ist zur Compilezeit nicht bekannt. Vielleicht kannst du ein Template basteln, das immerhin für die Zahl der Dimensionen einen Parameter bereitstellt, der ist ja bekannt. Aber wie willst du dann den Zugriff gestallten? Du bräuchtest also so viele (normale) Argumente, wie Dimensionen. Das wäre also nur mit <cstdarg> möglich - sehr hässlich. Leider. (Oder aber mit variadic Templates. Da könnte was laufen. Aber mein Compiler mag die nicht :(, daher werde ich da jetzt nichts versuchen.)
-
zeusosc schrieb:
@Otze:
Für Matrixprodukt gibt es doch auch ne SSE2 Variante!??Ja. und eine parallele Variante und eine GPU Variante und eine Clustervariante und... Was ist der Punkt? Das Code, den ich auf ein für einen Anfänger verständliches Niveau runter gebrochen hab, nicht das absolute Performanceoptimum darstellt?
In der Tat wird jeder momentan übliche Compiler wenn man Optimierungen anschaltet den Code vektorisieren und SSE2-code erzeugen. Natürlich kann man besser als das werden. Viel besser. Aber das ist dann kein Code, den man hier im Forum posten könnte. Das fängt damit an, dass man dafür sorgen muss, dass der Speicher an 16 Byte Grenzen ausgerichtet sein muss und hört dann bei sicherlich 100 Zeilen unverständlichen SSE-Intrinsics auf.
Natürlich geht es schneller. Und ich würde jedem mit ein wenig Erfahrung empfehlen, sich mal eine explizite Vektorisierung anzutun. Aber SSE macht aus schlechtem Code keine Rakete. Und wie man hier im Thread - und auch bei dir - sieht, würden die Flaschenhälse bei den meisten Leuten einfach ganz woanders liegen. Das fängt schon mal damit an, dass du zum Beispiel die Laufzeit von tanh völlig überschätzt. 1 tanh kannst du auf double Präzision in weniger als 150 Takten berechnen. Das sind ganz schön viele tanh pro Sekunde. Und mal so nebenbei: wenn es eine so einfache Möglichkeit gäbe, tanh bei ähnlicher Präzision erheblich schneller zu berechnen, dann würden die Hersteller der Laufzeitbibliotheken diese mitliefern. Ähnliches gilt für std::vector (Bemerkenswerte Ausnahme ist std::complex, das kann nach den Vorgaben des Standards gar nicht schnell sein).
Wie du siehst, kann man da gar nicht so viel falsch machen, außer std::vector falsch zu verwenden, natürlich. Aber bei der linearen Algebra. Da kannst du richtig viel verlieren.
Es ist mal wieder Zeit für meinen liebsten Benchmark.
http://eigen.tuxfamily.org/index.php?title=BenchmarkDa kommt der Faktor 10 her.
-
otze schrieb:
Ich hoffe, du schaust nochmal in den Thread rein, auch wenn du das als (warum auch immer) gelöst markiert hast.
Ich habe mal ein wenig Code aus meinem aktuellen Projekt extrahiert und soweit vereinfacht, dass du es mit deinem Kenntnisstand verstehen müsstest.
Ja klar schau ich hier immer mal rein. Na ja und ich hab ihn als gelöst markiert, da ja recht einstimmig gesagt wurde, dass vectoren nicht allzu oft verschachtelt werden sollten. Ich habe mich deshalb einfach nur rangesetzt um meinen Code so wie die vorgeschlagene Matrix-Sache zu verbessern. Solche spezifischen Details wie sie jetzt zum Schluss besprochen worden, scheinen ja nicht mehr direkt meine Frage bezüglich der Geschwindigkeit zu beantworten.
Danke für den Code! Er ist wirklich mal gut zu verstehen und macht es mir als Nicht-Profi-Programmierer relativ leicht ihn umzusetzten.
-
... reicht mir zumindest nicht. Wo ist denn der Beleg, dass das Verschachteln von vector<> langsamer ist als ein C-Stil Feld? Erst messen, dann entscheiden.
Habe mir ein Testprogramm geschrieben mit folgenden Ergebnissen:
StdMatrix ist vector<vector<T>>
StdArray ist array<array<T, N>, M>
Flat ist T* mit new alloziertC:\work\learning\matrixPerformance\x64\Release>matrixPerformance.exe Measuring Matrix performance in different implementations StdMatrix = 0.0014709030 s StdArray = 0.0014882258 s FlatMatrix = 0.0021665119 s Speedups: --> | StdMatrix StdArray FlatMatrix ----------------+------------------------------------------------------ Std::Matrix |1.0000000000 1.0117770217 1.4729128500 Std::Array |0.9883600621 1.0000000000 1.4557682359 c_Matrix |0.6789267946 0.6869225302 1.0000000000 Benchmarking matrix multiplication... Time Flat = 81.0635421623s // "triviale Implementierung" Time Opt = 5.0158342457s // optimierte und parallelisierte Implementierung (auf mobile i5) Speedup = 16.1615273137 Benchmarking cache performance in transpose... Transpose time Flat = 0.0335489836s // transponieren der Matrix "triviale Implementierung" Transpose time Opt = 0.0005909019s // tranponieren auf cache optimiert und parallelisiert Speedup = 56.7758957655Habe im output noch ein paar Kommentare hinzu gefügt. vector und array sind nahezu gleich schnell, die C-Stil matrix ist in jedem Fall langsamer.
Zeitmessungen habe ich, der höheren Genauigkeit wegen, mit QueryPerformanceCounter (Win32) durchgeführt.
EDIT: Für unterschiedliche Datentypen variieren bei mir die Zeiten durchaus, aber nicht in Bereichen jenseits 30% (auf meinem Rechner)
-
Hier ist noch der Code zu meinem vorherigen Post:
#include <stdlib.h> // rand() #include <iostream> #include <iomanip> #include <vector> #include <array> #include <algorithm> #include <numeric> #include <limits> #include "PerformanceCounterWin32.h" extern void MatrixMultiplication(void); #ifdef max #undef max #endif using namespace std; const unsigned int rows = 1201; const unsigned int columns = 1201; typedef short elemType; elemType makeElem(void) { return static_cast<elemType>((double)rand()/(double)RAND_MAX*numeric_limits<elemType>::max()); } void initializeData(vector<vector<elemType>>& matrix) { matrix.resize(rows); for (auto it = matrix.begin(); it != matrix.end(); ++it) { (*it).resize(columns); generate((*it).begin(), (*it).end(), makeElem); } } void initializeData(array<array<elemType, columns>, rows>& matrix) { // just for demonstration purposes, that stl based matrices // can be syntactically addressed like vanilla arrays // the loops can also be replaced by the same code like in // the initialization function for the vector<vector<>> code for (unsigned int y = 0; y<matrix.size(); ++y) { for (unsigned int x = 0; x<matrix[y].size(); ++x) { matrix[y][x] = makeElem(); } } } void initializeData(elemType* data, elemType**& rat) { for(unsigned int i = 0; i<rows*columns; ++i) { data[i] = makeElem(); } // the row address table provides [][] addressing // syntax for(unsigned int i = 0; i<rows; ++i) { rat[i] = &data[i*columns]; } } __declspec(noinline) elemType benchStdMatrix(vector<vector<elemType>>& matrix) { volatile elemType sum = 0; for( unsigned int i = 0; i<matrix.size(); ++i) { // accumulate is the fastest approach for vector sum = accumulate(matrix[i].begin(), matrix[i].end(), elemType(0)); } return sum; } __declspec(noinline) elemType benchStdArray(array<array<elemType, columns>, rows>& matrix) { volatile elemType sum = 0; for(unsigned int i = 0; i<rows; ++i) { // accumulate is the fastest approach for array sum += accumulate(matrix[i].begin(), matrix[i].end(), elemType(0)); } return sum; } __declspec(noinline) elemType benchFlatMatrix(elemType**& rat) { volatile elemType sum = 0; // This is the fastest version using flat model // difficult to read and with pointer arithmetics elemType* line = rat[0]; unsigned int counter = rows*columns; do { sum = *line++; }while (counter--); //for( unsigned int i = 0; i<rows; ++i) //{ // for( unsigned int j = 0; j<columns; ++j) // { // sum += rat[i][j]; // } //} return sum; } void printResults( PerformanceCounterWin32& perfCounter, const elemType& sum0, const elemType& sum1, const elemType& sum2) { double timeStdMatrix = perfCounter.getDeltaInSeconds(0, 1); double timeStdArray = perfCounter.getDeltaInSeconds(1, 2); double timeFlatMatrix = perfCounter.getDeltaInSeconds(2, 3); cout << setprecision(10) << setfill(' '); cout.setf(ios_base::fixed|ios_base::showpoint); cout << "StdMatrix = " << timeStdMatrix << " s" << endl; cout << "StdArray = " << timeStdArray << " s" << endl; cout << "FlatMatrix = " << timeFlatMatrix << " s" << endl << endl; cout << "Speedups: " << endl; cout << "\t -->\t| StdMatrix\tStdArray\tFlatMatrix" << endl; cout << "----------------+------------------------------------------------------" << endl; cout << "Std::Matrix |" << setw(8) << timeStdMatrix/timeStdMatrix << "\t" << setw(8) << timeStdArray/timeStdMatrix << "\t" << setw(8) << timeFlatMatrix/timeStdMatrix << endl; cout << "Std::Array |" << setw(8) << timeStdMatrix/timeStdArray << "\t" << setw(8) << timeStdArray/timeStdArray << "\t" << setw(8) << timeFlatMatrix/timeStdArray << endl; cout << "c_Matrix |" << setw(8) << timeStdMatrix/timeFlatMatrix << "\t" << setw(8) << timeStdArray/timeFlatMatrix << "\t" << setw(8) << timeFlatMatrix/timeFlatMatrix << endl; cout << endl << endl; cout << "Sum0 = " << sum0 << endl; cout << "Sum1 = " << sum1 << endl; cout << "Sum2 = " << sum2 << endl; } int main(void) { vector<vector<elemType>> stdMatrix; array<array<elemType, columns>, rows>* stdArray = new array<array<elemType, columns>, rows>(); elemType* flatMatrix = new elemType[rows*columns]; elemType** flatMatrixRAT = new elemType*[rows]; elemType sum0 = static_cast<elemType>(0); elemType sum1 = static_cast<elemType>(0); elemType sum2 = static_cast<elemType>(0); PerformanceCounterWin32 perfCounter; initializeData(stdMatrix); initializeData(*stdArray); initializeData(flatMatrix, flatMatrixRAT); cout << endl << "Measuring Matrix performance in different implementations" << endl << endl; perfCounter.startMeasurement(); sum0 = benchStdMatrix(stdMatrix); perfCounter.queryCounter(); sum1 = benchStdArray(*stdArray); perfCounter.queryCounter(); sum2 = benchFlatMatrix(flatMatrixRAT); perfCounter.queryCounter(); printResults(perfCounter, sum0, sum1, sum2); // MatrixMultiplication(); }MatrixMultiplication habe ich erst mal außen vor gelassen um den Thread nicht zuzumüllen. Kann ich bei Bedarf gerne auch bereit stellen.
Sollten in obigem Code Fehler sein, bin ich für Korrekturen dankbar.
-
vector<vector<elemType>> stdMatrix; array<array<elemType, columns>, rows>* stdArray = new array<array<elemType, columns>, rows>(); elemType* flatMatrix = new elemType[rows*columns]; elemType** flatMatrixRAT = new elemType*[rows];- std::array ist hier völlig fehl am Platz, weil die Grösse erst zur Laufzeit bekannt ist. Ausserdem ist es immer sinnlos, es mit new zu allozieren.
- flatMatrix wäre richtig (im Gegensatz zu flatMatrixRAT), aber das diese testest du nie
- warum ein einfacher (nicht geschachtelter) std::vector<> langsamer sein sollte als ein dynamisches Array ist mir auch nicht klar. Warum es schneller sein sollte auch nicht.
- zeusosc hat einen Mist programmiert, den kannst du ignorieren. Aber schau auf den Code von otze, der benutzt auch std::vector. Stört dich nur der Threadtitel?
-
- std::array ist hier völlig fehl am Platz, weil die Grösse erst zur Laufzeit bekannt ist. Ausserdem ist es immer sinnlos, es mit new zu allozieren.
Das ist richtig. Ist nur der Vergleichbarkeit wegen drin, da array im Thread vorher schon mal erwähnt worden ist.
- flatMatrix wäre richtig (im Gegensatz zu flatMatrixRAT), aber das diese testest du nie
Doch, das wird getestet in benchFlatMatrix(), den Code mit der Row Adress Table habe ich auskommentiert, weil er in meiner Umgebung langsamer war, als das direkte Berechnen des Indexes. vector und array lösen das intern ja genau so.
- warum ein einfacher (nicht geschachtelter) std::vector<> langsamer sein sollte als ein dynamisches Array ist mir auch nicht klar. Warum es schneller sein sollte auch nicht.
Ich verstehe das auch nicht, insbesondere, wenn man in die Implementierung von vector rein schaut. Die Unterschiede liegen ja auch nur im Bereich zwischen 10% und 30%, je nach gewähltem elemType, wobei alleine die Messungenauigkeit bei verschiedenen Durchläufen schon bei 10% liegt.
Mein Fazit ist ja, dass die Laufzeitunterschiede nicht daher kommen, dass vector<> verwendet wird.
-
ogni42 schrieb:
Mein Fazit ist ja, dass die Laufzeitunterschiede nicht daher kommen, dass vector<> verwendet wird.
Du hast es nicht verstanden. vector<vector<vector<double>>> ist natürlich wesentlich langsamer, als vector<array<array<double, N>, N>>. Dieser Effekt wird stärker, je mehr du im Speicher herumspringst. Sprobier mal so eine Schleife:
for (int i = 0; i != sx; ++i) for (int j = 0; j != sy; ++j) for (int k = 0; k != sz; ++k) v[i][j][k] = v[k][j][i] = v[j][i][k] = std::rand();Hier bekommst du eine ~50%ige Laufzeitbeschleunigung für Speicher der Am Stück liegt. Wenn du öfter so zugreifst, dass die Elemente nebeneinander liegen, erhöht sich der Effekt noch.
Keine Ahnung was du da mit deinem C Zeugs beweisen willst, dass ein vector<double> nicht langsamer ist als manuelle Verwaltung sollte wohl jedem klar sein.
-
cooky451 schrieb:
Du hast es nicht verstanden.
Das ist möglich, aber nicht sehr wahrscheinlich

cooky451 schrieb:
vector<vector<vector<double>>> ist natürlich wesentlich langsamer, als vector<array<array<double, N>, N>>. Dieser Effekt wird stärker, je mehr du im Speicher herumspringst.
Nein, das stimmt so nicht. Du setzt nämlich voraus, dass bei vector der Speicher "natürlich" nicht zusammenhängend im Speicher liegt. Das ist aber z.B. bei der Standard Lib, die ich hier habe der Fall. Die Standard-Bibliothek verlangt das aber nicht von std::vector<> wohingegen std::array<> das zusichert.
-
ogni42 schrieb:
cooky451 schrieb:
Du hast es nicht verstanden.
Das ist möglich, aber nicht sehr wahrscheinlich
cooky451 schrieb:
vector<vector<vector<double>>> ist natürlich wesentlich langsamer, als vector<array<array<double, N>, N>>. Dieser Effekt wird stärker, je mehr du im Speicher herumspringst.
Nein, das stimmt so nicht. Du setzt nämlich voraus, dass bei vector der Speicher "natürlich" nicht zusammenhängend im Speicher liegt. Das ist aber z.B. bei der Standard Lib, die ich hier habe der Fall. Die Standard-Bibliothek verlangt das aber nicht von std::vector<> wohingegen std::array<> das zusichert.
Du hast es nicht verstanden und das ist sicher.
-
ogni42 schrieb:
Das ist aber z.B. bei der Standard Lib, die ich hier habe der Fall.
Okay, dann hast du eine ziemlich komische Lib. Hat die für vector<vector<T>> eine Spezialisierung oder wie funktioniert das?Hm.. wenn man mal drüber nachdenkt, dürfte so eine Implementierung eigentlich nicht funktionieren. Ich muss also annehmen, dass du hier Schwachfug verzfapst, bis du mir das Gegenteil zeigst.
-
Cooky, hier ist der Code mit dem ich jetzt noch mal getestet habe:
void benchAssignmentVector() { cout << "benchmarking vector and array..." << endl; const size_t sx = 256; const size_t sy = sx; const size_t sz = sx; vector<vector<vector<double>>> v; v.resize(sx); for (int i = 0; i < v.size(); i++) { v[i].resize(sy); for (int j = 0; j < v[i].size(); j++) { v[i][j].resize(sz); } } cout << "vector = \t"; double startTime = clock(); for (int i = 0; i != sx; ++i) for (int j = 0; j != sy; ++j) for (int k = 0; k != sz; ++k) v[i][j][k] = v[k][j][i] = v[j][i][k] = std::rand(); double expired = clock() - startTime; cout << "vector based = " << expired/CLOCKS_PER_SEC << endl << endl; vector<array<array<double, sz>, sy>> a; a.resize(sx); cout << "array = \t"; double startTime2 = clock(); for (int i = 0; i != sx; ++i) for (int j = 0; j != sy; ++j) for (int k = 0; k != sz; ++k) v[i][j][k] = v[k][j][i] = v[j][i][k] = std::rand(); double expired2 = clock() - startTime2; cout << "array based = " << expired/CLOCKS_PER_SEC << endl; }Heraus kommt:
benchmarking vector and array... vector = vector based = 1.4980000000 array = array based = 1.4980000000Und das ist die normale Standard Bibliothek von Visual Studio.
@Sepp: Mit ist schon klar, dass wenn die Daten fragmentiert im Speicher liegen, die Performance deutlich schlechter ist als wenn sie konsekutiv im Speicher liegen. Aber das war nicht die Aussage, sondern, dass vector<vector<vector<double>>> "natürlich" wesentlich langsamer ist, als vector<array<array<double, N>, N>>. Und das stimmt so nicht.
Oder hast Du was anderes gemeint?
-
ogni42 schrieb:
@Sepp: Mit ist schon klar, dass wenn die Daten fragmentiert im Speicher liegen, die Performance deutlich schlechter ist als wenn sie konsekutiv im Speicher liegen. Aber das war nicht die Aussage, sondern, dass vector<vector<vector<double>>> "natürlich" wesentlich langsamer ist, als vector<array<array<double, N>, N>>. Und das stimmt so nicht.
Oder hast Du was anderes gemeint?
Doch das habe ich schon gemeint. Aber wenn du denkst, das deine Standardbibliothek vector<vector<vector<double>>> am Stück im Speicher hat und somit gleich schnell wie vector<array<array<double, N>, N>> ist, dann hast du ganz sicher etwas nicht verstanden. Es ist nämlich unmöglich, dass alles am Stück liegt.
edit: Hah:
cout << "vector based = " << [b]expired[/b]/CLOCKS_PER_SEC << endl << endl; cout << "array based = " << [b]expired[/b]/CLOCKS_PER_SEC << endl;edit2: Und das heißt, du benutzt noch nicht einmal Compilerwarnungen, denn ich hoffe doch sehr, dass VS unbenutzte Variablen erkennnt.
-
Teste mal:
class Stopwatch { std::clock_t time_; public: Stopwatch() : time_(std::clock()) {} void reset() { time_ = std::clock(); } double time() { return (std::clock() - time_) / static_cast<double>(CLOCKS_PER_SEC); } }; int main() { const unsigned sx = 256, sy = 256, sz = 256; //DynamicArray<double> mem(sx, sy, sz); Stopwatch w; //for (int i = 0; i != sx; ++i) // for (int j = 0; j != sy; ++j) // for (int k = 0; k != sz; ++k) // mem(i, j, k) = mem(k, j, i) = mem(j, i, k) = std::rand(); //std::cout << "Time: " << w.time() << '\t' << mem(std::rand() % sx, std::rand() % sy, std::rand() % sz) << '\n'; std::vector<std::vector<std::vector<double>>> v(sx); for (int i = 0; i != sx; ++i) { v[i].resize(sy); for (int j = 0; j != sy; ++j) v[i][j].resize(sz); } w.reset(); for (int i = 0; i != sx; ++i) for (int j = 0; j != sy; ++j) for (int k = 0; k != sz; ++k) v[i][j][k] = v[k][j][i] = v[j][i][k] = std::rand(); std::cout << "Time: " << w.time() << '\t' << v[std::rand() % sx][std::rand() % sy][std::rand() % sz] << '\n'; std::vector<std::array<std::array<double, sz>, sy>> v2(sx); w.reset(); for (int i = 0; i != sx; ++i) for (int j = 0; j != sy; ++j) for (int k = 0; k != sz; ++k) v2[i][j][k] = v2[k][j][i] = v2[j][i][k] = std::rand(); std::cout << "Time: " << w.time() << '\t' << v2[std::rand() % sx][std::rand() % sy][std::rand() % sz] << '\n'; getchar(); }
-
@sepp: Ja, das war falsch. Hatte ich übersehen.
Bei mir kommt auch nach Korrektur dennoch was sehr komisches raus:
benchmarking vector and array... vector = vector based = 1.5040000000 array = array based = 1.5160000000 Cookybench Time: 1.4310000000 27227.0000000000 Time: 0.7100000000 3797.0000000000Ich nehme mal an, dass ich irgendwo noch einen Fehler habe. Ich find's nur nicht.
EDIT: OK. Copy Paste Dummheit. Jetzt kommen dieselben Werte. (also auch die 50%)
-
ogni42 schrieb:
Nein, das stimmt so nicht. Du setzt nämlich voraus, dass bei vector der Speicher "natürlich" nicht zusammenhängend im Speicher liegt. Das ist aber z.B. bei der Standard Lib, die ich hier habe der Fall. Die Standard-Bibliothek verlangt das aber nicht von std::vector<> wohingegen std::array<> das zusichert.
1. bei std::vector sichert der Standard das seit C++03 zu.
2. std:.vector<std::vector<double> > kann nicht zusammenhängend im Speicher liegen.
denn was ist ein vereinfachter std::vector?
template<class T> class vector{ T* data; std::size_t size; };und was ist damit vereinfacht ein vector<vector<double> >?
class vector<vector<double>{ vector<double>* data; std::size_t size; }; =>Einsetzen von def std::vector<double> unformern und vereinfachen: class vector<vector<double>{ double** data; std::size_t* sizeI; std::size_t size; };wenn man dann einen vector mit 100 Elementen konstruiert (die jeweils wieder 100 elemente enthalten), dann steht da im constructor vereinfacht wieder folgendes:
double** data = new double[100]; for(std::size_t i = 0; i != 100; ++i) data[i]=new double[100];und das ist 100% kein zusammenhängender Speicher. Du hast es also wirklich nicht verstanden.
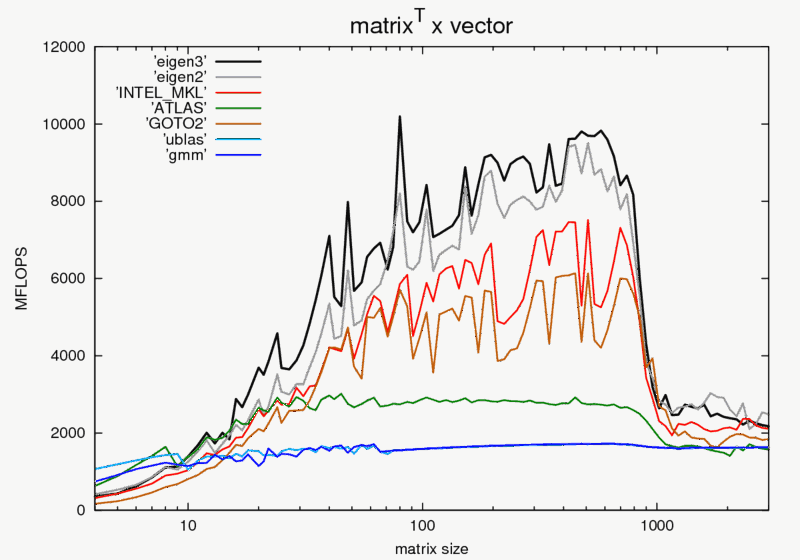
//edit ich psote nochmal das hier wichtigste Bild vom benchmark:
http://download.tuxfamily.org/eigen/btl-results-110323/atv.png
siehst du den performanceloss bei ca 800-1000? Das sind die einsetzen Cache-Misses, wenn der vector so groß ist, dass die CPU nicht mehr alle Daten sinnvoll gleichzeitig im Cache halten kann. Mit Fragmentiertem Speicher wie einem verschachtelten array hast du diese Misses direkt in der Struktur der Matrix eingebaut.
-
otze schrieb:
C/C++ Code:
double** data = new double[100];
for(std::size_t i = 0; i != 100; ++i)
data[i]=new double[100];Ich nehmen mal an, Du meinst
double** data = new double* [100]; for(std::size_t i = 0; i != 100; ++i) data[i]=new double[100];
{kind=link}