[gelöst] Vector ist wesentlich langsamer als Array?
-
- std::array ist hier völlig fehl am Platz, weil die Grösse erst zur Laufzeit bekannt ist. Ausserdem ist es immer sinnlos, es mit new zu allozieren.
Das ist richtig. Ist nur der Vergleichbarkeit wegen drin, da array im Thread vorher schon mal erwähnt worden ist.
- flatMatrix wäre richtig (im Gegensatz zu flatMatrixRAT), aber das diese testest du nie
Doch, das wird getestet in benchFlatMatrix(), den Code mit der Row Adress Table habe ich auskommentiert, weil er in meiner Umgebung langsamer war, als das direkte Berechnen des Indexes. vector und array lösen das intern ja genau so.
- warum ein einfacher (nicht geschachtelter) std::vector<> langsamer sein sollte als ein dynamisches Array ist mir auch nicht klar. Warum es schneller sein sollte auch nicht.
Ich verstehe das auch nicht, insbesondere, wenn man in die Implementierung von vector rein schaut. Die Unterschiede liegen ja auch nur im Bereich zwischen 10% und 30%, je nach gewähltem elemType, wobei alleine die Messungenauigkeit bei verschiedenen Durchläufen schon bei 10% liegt.
Mein Fazit ist ja, dass die Laufzeitunterschiede nicht daher kommen, dass vector<> verwendet wird.
-
ogni42 schrieb:
Mein Fazit ist ja, dass die Laufzeitunterschiede nicht daher kommen, dass vector<> verwendet wird.
Du hast es nicht verstanden. vector<vector<vector<double>>> ist natürlich wesentlich langsamer, als vector<array<array<double, N>, N>>. Dieser Effekt wird stärker, je mehr du im Speicher herumspringst. Sprobier mal so eine Schleife:
for (int i = 0; i != sx; ++i) for (int j = 0; j != sy; ++j) for (int k = 0; k != sz; ++k) v[i][j][k] = v[k][j][i] = v[j][i][k] = std::rand();Hier bekommst du eine ~50%ige Laufzeitbeschleunigung für Speicher der Am Stück liegt. Wenn du öfter so zugreifst, dass die Elemente nebeneinander liegen, erhöht sich der Effekt noch.
Keine Ahnung was du da mit deinem C Zeugs beweisen willst, dass ein vector<double> nicht langsamer ist als manuelle Verwaltung sollte wohl jedem klar sein.
-
cooky451 schrieb:
Du hast es nicht verstanden.
Das ist möglich, aber nicht sehr wahrscheinlich

cooky451 schrieb:
vector<vector<vector<double>>> ist natürlich wesentlich langsamer, als vector<array<array<double, N>, N>>. Dieser Effekt wird stärker, je mehr du im Speicher herumspringst.
Nein, das stimmt so nicht. Du setzt nämlich voraus, dass bei vector der Speicher "natürlich" nicht zusammenhängend im Speicher liegt. Das ist aber z.B. bei der Standard Lib, die ich hier habe der Fall. Die Standard-Bibliothek verlangt das aber nicht von std::vector<> wohingegen std::array<> das zusichert.
-
ogni42 schrieb:
cooky451 schrieb:
Du hast es nicht verstanden.
Das ist möglich, aber nicht sehr wahrscheinlich
cooky451 schrieb:
vector<vector<vector<double>>> ist natürlich wesentlich langsamer, als vector<array<array<double, N>, N>>. Dieser Effekt wird stärker, je mehr du im Speicher herumspringst.
Nein, das stimmt so nicht. Du setzt nämlich voraus, dass bei vector der Speicher "natürlich" nicht zusammenhängend im Speicher liegt. Das ist aber z.B. bei der Standard Lib, die ich hier habe der Fall. Die Standard-Bibliothek verlangt das aber nicht von std::vector<> wohingegen std::array<> das zusichert.
Du hast es nicht verstanden und das ist sicher.
-
ogni42 schrieb:
Das ist aber z.B. bei der Standard Lib, die ich hier habe der Fall.
Okay, dann hast du eine ziemlich komische Lib. Hat die für vector<vector<T>> eine Spezialisierung oder wie funktioniert das?Hm.. wenn man mal drüber nachdenkt, dürfte so eine Implementierung eigentlich nicht funktionieren. Ich muss also annehmen, dass du hier Schwachfug verzfapst, bis du mir das Gegenteil zeigst.
-
Cooky, hier ist der Code mit dem ich jetzt noch mal getestet habe:
void benchAssignmentVector() { cout << "benchmarking vector and array..." << endl; const size_t sx = 256; const size_t sy = sx; const size_t sz = sx; vector<vector<vector<double>>> v; v.resize(sx); for (int i = 0; i < v.size(); i++) { v[i].resize(sy); for (int j = 0; j < v[i].size(); j++) { v[i][j].resize(sz); } } cout << "vector = \t"; double startTime = clock(); for (int i = 0; i != sx; ++i) for (int j = 0; j != sy; ++j) for (int k = 0; k != sz; ++k) v[i][j][k] = v[k][j][i] = v[j][i][k] = std::rand(); double expired = clock() - startTime; cout << "vector based = " << expired/CLOCKS_PER_SEC << endl << endl; vector<array<array<double, sz>, sy>> a; a.resize(sx); cout << "array = \t"; double startTime2 = clock(); for (int i = 0; i != sx; ++i) for (int j = 0; j != sy; ++j) for (int k = 0; k != sz; ++k) v[i][j][k] = v[k][j][i] = v[j][i][k] = std::rand(); double expired2 = clock() - startTime2; cout << "array based = " << expired/CLOCKS_PER_SEC << endl; }Heraus kommt:
benchmarking vector and array... vector = vector based = 1.4980000000 array = array based = 1.4980000000Und das ist die normale Standard Bibliothek von Visual Studio.
@Sepp: Mit ist schon klar, dass wenn die Daten fragmentiert im Speicher liegen, die Performance deutlich schlechter ist als wenn sie konsekutiv im Speicher liegen. Aber das war nicht die Aussage, sondern, dass vector<vector<vector<double>>> "natürlich" wesentlich langsamer ist, als vector<array<array<double, N>, N>>. Und das stimmt so nicht.
Oder hast Du was anderes gemeint?
-
ogni42 schrieb:
@Sepp: Mit ist schon klar, dass wenn die Daten fragmentiert im Speicher liegen, die Performance deutlich schlechter ist als wenn sie konsekutiv im Speicher liegen. Aber das war nicht die Aussage, sondern, dass vector<vector<vector<double>>> "natürlich" wesentlich langsamer ist, als vector<array<array<double, N>, N>>. Und das stimmt so nicht.
Oder hast Du was anderes gemeint?
Doch das habe ich schon gemeint. Aber wenn du denkst, das deine Standardbibliothek vector<vector<vector<double>>> am Stück im Speicher hat und somit gleich schnell wie vector<array<array<double, N>, N>> ist, dann hast du ganz sicher etwas nicht verstanden. Es ist nämlich unmöglich, dass alles am Stück liegt.
edit: Hah:
cout << "vector based = " << [b]expired[/b]/CLOCKS_PER_SEC << endl << endl; cout << "array based = " << [b]expired[/b]/CLOCKS_PER_SEC << endl;edit2: Und das heißt, du benutzt noch nicht einmal Compilerwarnungen, denn ich hoffe doch sehr, dass VS unbenutzte Variablen erkennnt.
-
Teste mal:
class Stopwatch { std::clock_t time_; public: Stopwatch() : time_(std::clock()) {} void reset() { time_ = std::clock(); } double time() { return (std::clock() - time_) / static_cast<double>(CLOCKS_PER_SEC); } }; int main() { const unsigned sx = 256, sy = 256, sz = 256; //DynamicArray<double> mem(sx, sy, sz); Stopwatch w; //for (int i = 0; i != sx; ++i) // for (int j = 0; j != sy; ++j) // for (int k = 0; k != sz; ++k) // mem(i, j, k) = mem(k, j, i) = mem(j, i, k) = std::rand(); //std::cout << "Time: " << w.time() << '\t' << mem(std::rand() % sx, std::rand() % sy, std::rand() % sz) << '\n'; std::vector<std::vector<std::vector<double>>> v(sx); for (int i = 0; i != sx; ++i) { v[i].resize(sy); for (int j = 0; j != sy; ++j) v[i][j].resize(sz); } w.reset(); for (int i = 0; i != sx; ++i) for (int j = 0; j != sy; ++j) for (int k = 0; k != sz; ++k) v[i][j][k] = v[k][j][i] = v[j][i][k] = std::rand(); std::cout << "Time: " << w.time() << '\t' << v[std::rand() % sx][std::rand() % sy][std::rand() % sz] << '\n'; std::vector<std::array<std::array<double, sz>, sy>> v2(sx); w.reset(); for (int i = 0; i != sx; ++i) for (int j = 0; j != sy; ++j) for (int k = 0; k != sz; ++k) v2[i][j][k] = v2[k][j][i] = v2[j][i][k] = std::rand(); std::cout << "Time: " << w.time() << '\t' << v2[std::rand() % sx][std::rand() % sy][std::rand() % sz] << '\n'; getchar(); }")
-
@sepp: Ja, das war falsch. Hatte ich übersehen.
Bei mir kommt auch nach Korrektur dennoch was sehr komisches raus:
benchmarking vector and array... vector = vector based = 1.5040000000 array = array based = 1.5160000000 Cookybench Time: 1.4310000000 27227.0000000000 Time: 0.7100000000 3797.0000000000Ich nehme mal an, dass ich irgendwo noch einen Fehler habe. Ich find's nur nicht.
EDIT: OK. Copy Paste Dummheit. Jetzt kommen dieselben Werte. (also auch die 50%)
-
ogni42 schrieb:
Nein, das stimmt so nicht. Du setzt nämlich voraus, dass bei vector der Speicher "natürlich" nicht zusammenhängend im Speicher liegt. Das ist aber z.B. bei der Standard Lib, die ich hier habe der Fall. Die Standard-Bibliothek verlangt das aber nicht von std::vector<> wohingegen std::array<> das zusichert.
1. bei std::vector sichert der Standard das seit C++03 zu.
2. std:.vector<std::vector<double> > kann nicht zusammenhängend im Speicher liegen.
denn was ist ein vereinfachter std::vector?
template<class T> class vector{ T* data; std::size_t size; };und was ist damit vereinfacht ein vector<vector<double> >?
class vector<vector<double>{ vector<double>* data; std::size_t size; }; =>Einsetzen von def std::vector<double> unformern und vereinfachen: class vector<vector<double>{ double** data; std::size_t* sizeI; std::size_t size; };wenn man dann einen vector mit 100 Elementen konstruiert (die jeweils wieder 100 elemente enthalten), dann steht da im constructor vereinfacht wieder folgendes:
double** data = new double[100]; for(std::size_t i = 0; i != 100; ++i) data[i]=new double[100];und das ist 100% kein zusammenhängender Speicher. Du hast es also wirklich nicht verstanden.
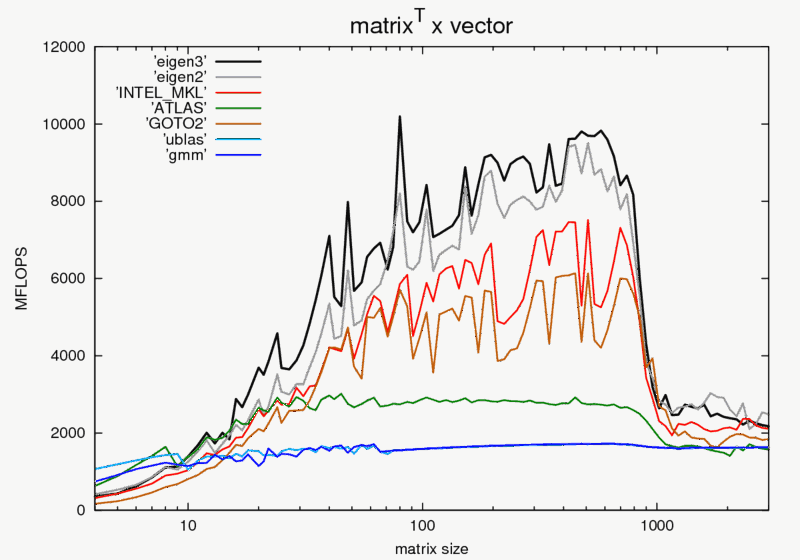
//edit ich psote nochmal das hier wichtigste Bild vom benchmark:
http://download.tuxfamily.org/eigen/btl-results-110323/atv.png
siehst du den performanceloss bei ca 800-1000? Das sind die einsetzen Cache-Misses, wenn der vector so groß ist, dass die CPU nicht mehr alle Daten sinnvoll gleichzeitig im Cache halten kann. Mit Fragmentiertem Speicher wie einem verschachtelten array hast du diese Misses direkt in der Struktur der Matrix eingebaut.
-
otze schrieb:
C/C++ Code:
double** data = new double[100];
for(std::size_t i = 0; i != 100; ++i)
data[i]=new double[100];Ich nehmen mal an, Du meinst
double** data = new double* [100]; for(std::size_t i = 0; i != 100; ++i) data[i]=new double[100];
-
ich habe einen Zeiger vergessen! mein ganzes Argument ist ungültig.
-
Keineswegs. Es ist vollkommen richtig.
Meine Aussage war ja, dass bei einem vector<> dessen Elemente zusammenhängend im Speicher liegen. Mehr nicht.
Aber ich lass das jetzt lieber. Wir reden sonst nur noch mehr aneinander vorbei
-
Da war noch etwas mehr:
Wo ist denn der Beleg, dass das Verschachteln von vector<> langsamer ist als ein C-Stil Feld?
beleg folgt aus Definition der verwendeten Elementtypen.
{kind=link}