[A] C++ hinter den Kulissen
-
*Hallo, der Artikel ist noch lange nicht fertig, aber ich poste ihn schonmal, falls mich jemand bei den bestehenden Dingen inhaltlich korrigieren oder einfach den Artikel testlesen will. Anspruch auf Vollständigkeit wird natürlich nicht erhoben, also nicht böse sein, falls Dinge wie Digraphen oder so etwas fehlen, viele Dinge sind allerdings auch schon als Notiz eingefügt. Der Artikel ist jetzt schon sehr lange, daher wird das vermutlich eine Serie. Die Menüstruktur passt vielleicht auch noch nicht ganz, aber das werde ich dann ggf. anpassen. Änderungen werde ich von Zeit zu Zeit direkt hier im Artikel vornehmen, da das sonst ein seeehr langer Thread werden würde.
P.S.: Die Style-Guides hier habe ich gesehen, die fetten nicht-nummerierten Zwischenüberschriften werden evtl. noch in h3-Überschriften abgewandelt
EDIT: Ich habe jetzt Fragen mit (??? <Frage>) markiert, wenn die jemand zufällig beantworten kann, wäre das nett.*
C++ hinter den Kulissen
Viele Ein- und auch manche Umsteiger fragen sich sicherlich, was mit ihren C++-Dateien passiert. Was ist eine Library? Wie benutzt man Headerdateien? Was bedeutet "undefined reference"? Dieser Artikel versucht, Fragen zum Compiler und seinen "Assistenten" (auch am Beispiel der Gnu Compiler Collection (GCC)) aufzuklären.
Inhaltsverzeichnis:
-
1 Der Präprozessor
-
1.1 Was macht der Präprozessor?
-
1.2 Mögliche Fehlerquellen
-
1.3 Richtlinien für die Verwendung des Präprozessors
-
2 Der Compiler
-
2.1 Was macht der Compiler?
-
2.2 Was der Compiler weiß und was er nicht weiß
-
2.3 Mögliche Fehlerquellen
-
3 Der Assembler
-
4 Der Linker
-
4.1 Was macht der Linker?
-
4.2 Optimierungsmöglichkeiten
-
4.3 Mögliche Fehlerquellen
-
5 Der Archiver
-
5.1 Was macht der Archiver?
-
5.2 Mögliche Fehlerquellen
-
6 Dynamische Bibliotheken
-
6.1 Worin besteht der Unterschied zu statischen Bibliotheken?
-
6.2 Mögliche Fehlerquellen
Der C++-Standard teilt den Übersetzungsprozess in 8 Phasen auf:
1. Phase: Trigraph-Ersetzung (Präprozessor)
2. Phase: Zeilenzusammensetzung bei Zeilen mit einem Backslash (\) am Ende (Präprozessor)
3. Phase: Token-Zerlegung (Präprozessor, Erklärung siehe Compiler)
4. Phase: Auswertung von Präprozessordirektiven (Präprozessor)
5. Phase: Ersetzung von Escapesequenzen (Compiler)
6. Phase: Zusammensetzen von Stringliteralen (Compiler)
7. Phase: Übersetzung in Objektdateien (Compiler)
8. Phase: Konvertierung in ein Programm oder eine dynamische Library (Linker)In der Praxis sieht die Aufteilung der Dateiverarbeitung durch Compilersuite und Betriebssystem etwa so aus:
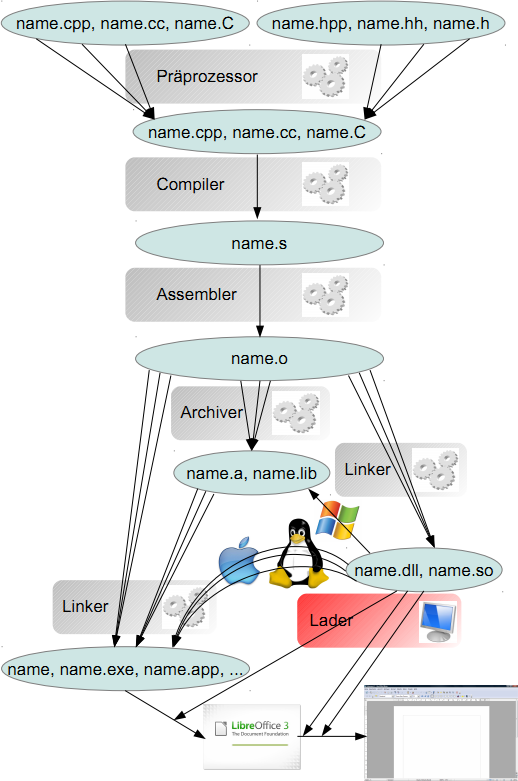
Die dargestellten Prozesse werden über den Artikel hinweg genauer erklärt. Für den Moment genügt es, zu wissen, dass der Weg für einfache Programme (mit den Windows-Dateiendungen) so lautet:
*.cpp/*.hpp Präprozessor, Compiler, Assembler *.o Linker *.exe Ausführung1 Der Präprozessor
Der Präprozessor ist üblicherweise das erste Programm, das den Programmcode verarbeitet. Beim GCC heißt der Präprozessor cpp. Er wird allerdings direkt vom Compiler aufgerufen.
1.1 Was macht der Präprozessor?
Der Präprozessor ist im Grunde genommen ein Textersetzungswerkzeug. Er verändert im Gegensatz zu einem normalen Texteditor mit einem Suchen-und-Ersetzen-Dialog allerdings keine Daten direkt in der Datei, sondern erstellt aufgrund von Anweisungen innerhalb des Codes eine neue Datei. Das Prä im Präprozessor deutet schon darauf hin, dass der Präprozessor nur eine Vorverarbeitung ist und man (theoretisch) auch ohne den Präprozessor auskommen könnte. Der Präprozessor ist in C++ der gleiche wie in C (lediglich in C99 gibt es einen überarbeiteten Präprozessor). Er ermöglicht einerseits eine Aufteilung von Programmen, Abnahme von Schreibarbeit, Plattformverwaltung und manchmal Dinge, die ohne Textersetzung nicht möglich sind. Andererseits ist er "dumm" und ermöglicht seltsame Fehler. In neueren Sprachen gibt es deshalb keinen Präprozessor, sondern stattdessen eine moderne Modulverwaltung, was ein Kritikpunkt an C++ ist. In C++ muss und sollte der Präprozessor durch Templates usw. jedoch nicht so häufig verwendet werden, wie das in vielen C-Programmen (vor allem viele Mikrocontroller-Steuerungen) der Fall ist.
Beim GCC kann durch den Aufrufg++ -E file.cpp -o output.cppdie Datei file.cpp vom Präprozessor verarbeitet und das Resultat in output.cpp gespeichert. Beim normalen Compileraufruf wird allerdings entweder gar keine Outputdatei erstellt oder diese gleich wieder gelöscht.Nun zu den grundlegenden konkreten Aufgaben des Präprozessors:
Trigraphen
Das erste, was die meisten Präprozessoren machen, ist die Ersetzung von speziellen Zeichen für exotische/kleine Tastaturen, die bestimmte Sonderzeichen nicht enthalten. Da dies inzwischen sehr selten geworden ist, muss man Trigraph-Unterstützung beim GCC und MSVC aber erst aktivieren (beim GCC mit der Option-trigraphs). In C99 gibt es für einige dieser Zeichen auch Digraphen, also Zwei-Zeichen-Sequenzen.Es gibt folgende Trigraphen:
---------------------------------------------------------------------------- | Trigraph | Ersetzung | Trigraph | Ersetzung | Trigraph | Ersetzung | ---------------------------------------------------------------------------- | ??= | # | ??( | [ | ??< | { | | ??/ | \ | ??) | ] | ??> | } | | ??’ | ˆ | ??! | | | ??- | ˜ | ----------------------------------------------------------------------------Da Trigraphen vor dem Scanner ersetzt werden, werden sie auch in Strings ersetzt. Wie man trotzdem Trigraphen in Strings darstellen kann, wird unter 1.2 erklärt.
Kommentare
Der Präprozessor entfernt Kommentare, also//einzeiliger Kommentar
und `/*mehrzeiliger
Kommentar
*/
. Mehr zu Kommentaren siehe#define`Neben dem Entfernen Kommentaren bearbeitet der Präprozessor Anweisungen, die in einer Zeile stehen und mit # beginnen. Einrückung durch Leerzeichen ist dabei erlaubt.
#include
Die Anweisung#include <File>oder#include "File"veranlasst den Präprozessor, den gesamten Inhalt der Datei 'File' an dieser Stelle in den Code einzufügen. Zwar ist nicht vorgegeben, was <> und "" anzeigen (und ob sie sich in ihrer Bedeutung überhaupt unterscheiden), dennoch gibt es Regeln, die oft verwendet werden: Spitze Klammern veranlassen den Präprozessor, die Datei File unter vorgegebenen Headerdateien und in einem oder mehreren optional angegebenen Suchpfaden zu suchen (die Suchpfade werden beim Compileraufruf angegeben, beim GCC mit-I Pfad/zur/Datei. In Anführungszeichen wird die Datei hingegen im Verzeichnis der aktuellen Code-Datei und in den Suchpfaden gesucht.
Statt einem Dateinamen kann auch ein relativer Pfad angegeben werden. Beispielsweise würde in eine Datei C:\Programme\test.cpp mit der Anweisung#include "Verwaltung/Versionsmanagement.hpp"(ja, es ist ein /, kein \) der Inhalt der Datei C:\Programme\Verwaltung\Versionsmanagement.hpp eingefügt werden.
Üblicherweise fügt man mit#includeHeader-Dateien ein (*.h, *.hpp), C++-Code-Dateien müssen und sollten im Normalfall nicht inkludiert werden. Bei Template-Klassen inkludiert man manchmal eine *.impl-Datei im Header, um die Implementierung auszulagern. (Mehr dazu unten)
Auf die inkludierte Datei werden vor dem Weiterverarbeiten des Inhalts die ersten 3 Übersetzungsphasen angewandt.#define
#define SUCHE ERSETZE //jedes Vorkommen von SUCHE unterhalb dieser Anweisung wird durch ERSETZE ersetzt //Anmerkung: SUCHE ist immer das 1. Wort (ohne Leerzeichen), während ERSETZE aus beliebig vielen Wörtern bestehen kann //ERSETZE kann auch aus gar nichts bestehen, dann wird SUCHE einfach durch nichts ersetzt SUCHE ERSETZE SUCHEERSETZE //hier kommt ERSETZE ERSETZE SUCHEERSETZE heraus //SUCHEERSETZE wird als ein Wort betrachtet (siehe auch 2.1 unter Scanner) und wird nicht ersetzt#defineist also der Ersetzungsbefehl im Präprozessor. Er kann auch Werte übergeben bekommen, die er in die Ersetzung mit einbauen kann. Beispiel:#define Ausgabe(string) std::cout << "Ausgabe(" << string << ")\n" //Der Parameter hat keinen Typ, er besteht lediglich aus Text int main() { Ausgabe("Hallo Welt!"); //Generierter Code: std::cout << "Ausgabe(" << "Hallo Welt!" << ")\n"; Ausgabe(5); //funktioniert auch, da der Parameter des Makros Ausgabe keinen Typ hat }Unbedingt sollte darauf hingewiesen werden, dass dieses Beispiel in normalem Code so nicht auftauchen sollte, da
- Ausgabe als Funktion geschrieben werden könnte und dann viele Probleme mit dem Makro nicht auftreten würden
- Ausgabe() irgendwo anders als Funktion deklariert/definiert werden könnte und dann plötzlich statt
void Ausgabe(std::string str);im Codevoid std::cout << "Ausgabe(" << std::string str << ")\n";stünde, was zu einer vermutlich völlig unverständlichen Fehlermeldung führen würde. - viele Programmierer erwarten, dass Ausgabe() eine Funktion ist, schon allein, weil man Makronamen üblicherweise in Großbuchstaben schreibt
Ebenfalls werden Makros oft als Konstanten missbraucht:
//schlechter Code: #define size 1024 //Arraygröße als Makro, kleingeschrieben! int main() { int werte[size]; //die Größe des Arrays muss dem Compiler bekannt sein, der Präprozessor ersetzt size durch 1024 //... mache irgendwas int size = laenge_x * laenge_y; //der Präprozessor generiert int 1024 = laenge_x * laenge_y; //error: expected unqualified-id before numeric constant } //besserer Code: const int size = 1024; //size könnte hier auch values_size oder so ähnlich genannt werden //in Headerdateien sollte folgendes verwendet werden (siehe weiter unten): //static const int size = 1024; //oder noch besser: ein anonymer namespace (siehe weiter unten): /* namespace { const int size = 1024; } */ int main() { int werte[size]; //hier könnte man in C++0x std::array<int, size> werte verwenden //... mache irgendwas int size = laenge_x * laenge_y; //warning: declaration of 'size' shadows a global declaration //mit std::cout << size wird hier die untere Variable ausgegeben, während std::cout << ::size die Konstante ausgibt }TODO: ist static const in Headerdateien wirklich notwendig, oder besteht in C++ automatisches static bei globalen const-Variablen?
Manch einer könnte auch auf die Idee kommen, Dinge durch Kommentare zu ersetzen, was allerdings fehlschlägt, weil der Präprozessor alle Kommentare entfernt, bevor er mit der Ersetzung beginnt:
#define COMMENT // COMMENT Dies ist kein Kommentar, weil COMMENT durch gar nichts ersetzt wird, auch nicht durch "//"Nützlich sind bei Ersetzung mit Parametern auch folgende Möglichkeiten des Präprozessors:
1. Text-zu-String-Operator:
#define TOSTRING(text) #text #define DEBUG(var) std::cout << #var << var << "\n" int main() { std::cout << TOSTRING(Dies ist ein langer Text, der durch Zeilenumbrüche weniger Scrollen benötigt, um gelesen werden zu können); }Wird # vor einen Parameternamen gesetzt, so wird der Text im Parameter in einen String umgewandelt, d.h.
Textwird zu"Text",Verschiedene Sprachen erfordern verschiedene Apostrophen: <<Französisch>>, "Deutsch", 'Englisch'wird Escape-gerecht zu"Verschiedene Sprachen erfordern verschiedene Apostrophen: <<Französisch>>, \"Deutsch\", 'Englisch'". Allerdings werden Tabulatoren, Zeilenumbrüche und mehrfache Leerzeichen immer zu einem Leerzeichen zusammengefasst.Nützlich ist hier auch das Feature des Compilers, dass mehrere Zeichenkettenliterale nebeneinander automatisch verknüpft werden.
Das bedeutet, dass"a" "b" "c"das Gleiche ist wie"abc". Damit ist es möglich,"präfix" #var "postfix"zu schreiben, was wesentlich einfacher und häufiger anwendbar ist als(std::string("präfix") + #var + "postfix").2. Verknüpfungs-Operator:
//nutzloses Beispiel #define COMPARE_EQUAL(a) a= //COMPARE_EQUAL(<) soll zu <= werden, COMPARE_EQUAL(>) zu >= und COMPARE_EQUAL(!) zu != int main() { int a, b; std::cin >> a >> b; if(a COMPARE_EQUAL(!) b) //error: expected ')' before '!' token (COMPARE_EQUAL(!) wurde zu ! = und nicht zu !=) //machwas } //so funktioniert es #define COMPARE_EQUAL(a) a##= //##fügt die beiden außenstehenden Dinge direkt zusammen int main() { int a, b; std::cin >> a >> b; if(a COMPARE_EQUAL(!) b) //funktioniert //machwas }In bestimmten Fällen kann so etwas nützlich sein: (wird auch manchmal bei Windows-Anwendungen und früher bei wxWidgets verwendet)
//hier verwende ich als Makronamen ENCODING, im Normalfall verwendet man aufgrund der häufigen Verwendung kurze Namen wie _, _T oder wxT usw. //bei Verwendung von ASCII-Strings #define ENCODING(string) string //bei Verwendung von Unicode-Strings (z.B. u8"Stringinhalt" für UTF-8) muss man nun nur noch das Makro ändern #define ENCODING(string) u8##string3. Variable Parameteranzahl
#define DECLARE_ARRAY(content_type, name, ...) content_type name[] = {__VA_ARGS__}... sind die variablen Parameter (die in eigentlich aus mindestens einem Parameter bestehen müssen, aber Compiler erlauben auch häufig 0, womit man dann in obigem Fall
DECLARE_ARRAY(int, empty_array)schreiben könnte) Da ... ja keinen Namen besitzt, wird es stattdessen durch __VA_ARGS__ angesprochen. Ein weiterer Anwendungsfall wird unter 1.5 gezeigt.
Allerdings gibt es Variable Makro-Parameter offiziell erst in C++11.Wer sich für die Möglichkeiten von Makros interessiert, kann auch einmal im Internet z.B. nach BOOST_BINARY() suchen oder sich folgenden Beitrag ansehen:
http://www.c-plusplus.net/forum/p2120677#2120677\ am Zeilenende
Steht in einem String am Zeilenende ein \ als letztes Zeichen, so wird dieser in der nächsten Zeile fortgesetzt. Der Präprozessor macht aus diesem Mehrzeilen-String einen einzeiligen String. Beispiel: Eine Datei test.cppint main() { const char *str = "asdf\ ghij"; }wird vom gcc-Präprozessor zu
# 1 "test.cpp" # 1 "<built-in>" # 1 "<command-line>" # 1 "test.cpp" int main() { const char *str = "asdf ghij"; }verarbeitet. Bemerkenswert ist hier einerseits, dass der Zeilenumbruch entfernt wird, die Leerzeichen aber erhalten bleiben. Andererseits fällt auf, dass der Präprozessor in der ursprünglich durch den zweiten Teil des Strings belegten Zeile eine Leerzeile gelassen hat, damit die Zeilennummern weiterhin mit den ursprünglichen Zeilennummern übereinstimmen. Warum hier spezielle Anweisungen wie
# 1 "String"auftauchen, wird weiter unten unter "Kommunikation Präprozessor-Compiler" erklärt.
Der Backslash am Zeilenende bedeutet aber nicht nur in Strings so viel wie "Halt, die Anweisung geht in der nächsten Zeile weiter", sondern auch in Präprozessoranweisungen, die mit # anfangen. Gerne davon Gebrauch gemacht wird vor allem bei längeren Ersetzungen, wie auch in Beispielen u.a. unter 1.5.
Ebenfalls gebraucht werden kann \ auch am Ende von einzeiligen Kommentaren, um den Kommentar auf die nächste Zeile auszudehnen, es funktioniert aber auch an anderen Stellen://Dies ist ein \ zweizeiliger Kommentar /\ * Dies ist ein mehrzeiliger Kommentar *\ /#undef
[c]#undef Makroname[/c] ist ein ganz einfacher Befehl, der die Definierung des Makros Makroname ab dieser Zeile rückgängig macht, sodass es nach dieser Zeile nicht mehr ersetzt wird. Dabei werden Makros mit und ohne Parameter uniform behandelt.#if, #else, #elif und #endif
#ifdrückt eine Bedingung aus. Der Code, der zwischen der Bedingung und dem dazugehörigen#else,#elifoder#endifsteht, wird nur in den vom Präprozessor generierten Zielquelltext eingefügt, wenn die Bedingung wahr ist. Alle Makros in der Bedingung wurde vor der Auswertung ersetzt. In der Bedingung darf nur mit bekannten Ganzzahlen operiert werden. Ausnahme bildet der Ausdruckdefined(Makroname), der zu 1 wird, falls der Makroname vorher definiert wurde, andernfalls zu 0.
Beispiel:#define NUMBER 2 int main() { #if NUMBER * 2 == 4 //Stimmt std::cout << "Hello\n"; #endif #if NUMBER < 2 //Stimmt nicht std::cout << "World\n"; #endif }Dieser Code gibt
Helloaus.
Das
std::cout << "World\n";bekommt der Compiler nie zu Gesicht.#elseist optional und leitet den Code ein, der in den Zielcode eingefügt werden soll, falls die Bedingung falsch ist.
Da man für ein Präprozessor-#if im Gegensatz zur "normalen" if-Bedingung im Code keine geschweiften Klammern ({}) benutzen kann, um zu zeigen, wo der zum #if zugehörige Code endet, markiert man das Ende eines #if-Blocks entweder mit#else,#elifoder#endif. Ein #elif-Block(siehe unten) endet dementsprechend bei#elseoder#endif, ein #else-Block immer beim zugehörigen#endif.Man kann Bedingungen auch verschachteln, oftmals kann man sich das allerdings auch durch den Gebrauch der "Hilfsdirektive" (so nenne ich das, weil man sie eigentlich vollständig ersetzen könnte)
#elifersparen. Folgende zwei Codeabschnitte sind gleichbedeutend:Code 1:
#if A //Code A #elif B //Code B #elif C //Code C #else //Code D #endifCode 2:
#if A //Code A #else #if B //Code B #else #if C //Code C #else //Code D #endif #endif #endifEinrückungen sind dem Präprozessor ebenso egal wie die Tatsache, ob Direktiven (also die Anweisungen mit dem
") in Funktionen, Klassen oder sonstigem auftreten (Ausnahme: siehe #pragma).
in Funktionen, Klassen oder sonstigem auftreten (Ausnahme: siehe #pragma).#ifdef, #ifndef
#ifdefund#ifndefsind ähnlich wie#elifeine Art "Hilfsmakro". Die folgenden Präprozessordirektiven sind gleichbedeutend://1. Möglichkeit: #ifdef __linux__ //wenn dieses Makro definiert wurde, wird das Programm normalerweise für Linux kompiliert, siehe unten bei Umgebungs-Makros //irgendwelcher Linux-spezifischer Code #endif //2. Möglichkeit: #if defined(__linux__) //irgendwelcher Linux-spezifischer Code #endifEntsprechend ist
#ifndef MAKROäquivalent zu#if !defined(MAKRO).#error
#pragma
#pragma pack
-> kontext-sensitiv, siehe Verweis bei #elif, genau wie OpenMP
#pragma hdrstop
#pragma once
OpenMP
Warnungen an-/ausschalten
Andere Direktiven
#linemanchmal #warning
__FILE__, __LINE__, __DATE__, __TIME__
Andere vordefinierte Makros
__STDC__, __cplusplus, __STDC_VERSION__
Umgebungs-Makros
http://predef.sourceforge.net/preos.html
Kommunikation Präprozessor - Compiler
Zeilen-/Spalten-/DateihinweiseReservierung von __xxxxx__
Es fehlt noch: UB bei Definierung von Schlüsselwörtern (#define private public)
1.2 Mögliche Fehlerquellen
Makro-Name wird nicht ersetzt, bevor er verarbeitet wird
Angenommen, ein Programmierer will das Verzeichnis, mit dem ein Programm standardmäßig arbeitet, auslesen, so wird er vielleicht folgenden Code schreiben:#if defined(_HOST_OS_WINDOWS_) #include <direct.h> #define WORKING_DIRECTORY_FUNCTION _getcwd #else #include <unistd.h> #define WORKING_DIRECTORY_FUNCTION getcwd #endif //defined(_HOST_OS_XXX_)Die Variable _HOST_OS_WINDOWS_ definiert er dabei, falls die Datei unter Windows übersetzt wird (siehe auch Umgebungs-Makros unter 1.1). Das Problem, das hierdurch gelöst wird, ist, dass die Funktionen unter Windows und Linux/Unix zwar ähnlich funktionieren, jedoch unterschiedlich heißen und in unterschiedlichen Headern deklariert sind. Das Problem wäre in den meisten Fällen besser mit einer inline-Funktion etwa wie im folgenden Beispiel unten zu lösen, doch zwecks Demonstrationszwecken wird hier ein Makro verwendet.
//Bessere Lösung #if defined(_HOST_OS_WINDOWS_) #include <direct.h> inline char *WORKING_DIRECTORY_FUNCTION(char *buffer, int maxlen) //hier sollte man den Namen eher klein schreiben { return _getcwd(buffer, maxlen); } #else #include <unistd.h> inline char *WORKING_DIRECTORY_FUNCTION(char *buffer, int maxlen) { return getcwd(buffer, maxlen); } #endif //defined(_HOST_OS_XXX_)Aber um zum Problem zurückzukehren: Unser Beispiel-Programmierer bezieht sich in seinem Programm auf ein Makro _DEBUG_, das er definiert, falls sein Programm spinnt, um nachvollziehen zu können, was passiert.
#include <iostream> #if defined(_DEBUG_) #define ASSIGN(left, right) \ left = right; \ std::cout << #left " = " #right "; " #left ": " << left << "\n" #else #define ASSIGN(left, right) \ left = right #endif //_DEBUG_Was passiert also hier? Falls _DEBUG_ irgendwo vor diesem Code per
#definedefiniert wurde, wird bei jeder Verwendung des Makros zusätzlich zur Zuweisung von right an left auch der Code dieser Zuweisung und der Wert von right (der danach ja in left steht) ausgegeben. Unser (zugegebenermaßen nicht gerade das ++ nach dem C vedienende) Programmierer verwendet die angegebenen Makros in folgendem Code.int main() { char buffer[FILENAME_MAX]; //wird in <cstdio> definiert char *result = NULL; //vorbildliche NULL-Initialisierung von Zeigern //dafür wäre es eigentlich geschickt, eine Funktion std::string GetWorkingDirectory() zu schreiben, die uns diesen Aufwand erspart ASSIGN(result, WORKING_DIRECTORY_FUNCTION(buffer, FILENAME_MAX)); //statt FILENAME_MAX könnte man hier auch sizeof(buffer) / sizeof(buffer[0]) verwenden, weil die Größe von buffer hier bekannt ist. }Der Programmierer ist stolz auf sich, denn schon mit weniger großem Aufwand (ASSIGN() statt = zu verwenden und einmal _DEBUG_ zu definieren) kann er sich alle Zuweisungen in seinem Programm protokollieren lassen. Würde er zusätzlich Templates in sein Makro einbauen (die C++11-Lösung müsste dabei allerdings von der Lösung für ältere C++-Sprachstandards differieren), könnte er ASSIGN() sogar eine Rückgabe verleihen, die er dann in einem größeren Ausdruck weiterverwenden könnte oder statt ASSIGN() ein Makro OUT() entwerfen, das keine Zuweisung benötigt (im obigen Bespiel könnte er dann
result = OUT(WORKING_DIRECTORY_FUNCTION(buffer, FILENAME_MAX));schreiben).
Die Überraschung folgt auf dem Fuße: Ist _DEBUG_ im Beispiel oben definiert, das aktuelle Arbeitsverzeichnis lautet C:\Entwicklung\Test (was auch andeutet, dass hier die Windows-Funktion _getcwd() verwendet wird) und FILENAME_MAX ist 512, erwartet sich der Programmierer folgende Ausgabe:result = _getcwd(buffer, 512); result: C:\Entwicklung\TestDie Ausgabe sieht aber folgendermaßen aus:
result = WORKING_DIRECTORY_FUNCTION(buffer, FILENAME_MAX); result: C:\Entwicklung\TestWarum ist das so? Der Präprozessor hat zuerst den Parameter "right" des Makros ASSIGN() in einen String umgewandelt, bevor er alle Vorkommen von WORKING_DIRECTORY_FUNCTION und FILENAME_MAX durch ihre Ersetzungen ersetzt hat. Bei der Zuweisung hingegen wurde mit right nichts gemacht, daher konnten die Makonamen, die darin enthalten waren, anschließend ersetzt werden. Makronamen in Strings werden hingegen ja nicht ersetzt (das wäre wirklich schlimm).
Angenommen, der Programmierer bemerkt den Fehler. Was kann er tun, damit zuerst WORKING_DIRECTORY_FUNCTION und FILENAME_MAX ersetzt werden und danach right in einen String umgewandelt wird?
Die Lösung ist verblüffend einfach und seltsam zugleich:#if defined(_DEBUG_) #define ASSIGN(left, right) ASSIGN_HELPER(left, right) #define ASSIGN_HELPER(left, right) \ left = right; \ std::cout << #left " = " #right "; " #left ": " << left << "\n" #else #define ASSIGN(left, right) \ left = right #endif //_DEBUG_Statt dass ASSIGN gleich selbst den Code generiert, ruft es ein zweites Makro auf, das genau das tut, was ASSIGN() im vorherigen Beispiel tat. Und so funktioniert das Ganze dann plötzlich, obwohl es völlig unlogisch erscheint. Wer ein noch verzwickteres Problem hat und sich sowohl wirklich weder anders besser oder durch Probieren lösen lässt, der sollte im Internet die genauen Regeln für den Präprozessor anschauen.
Bei diesem Beispiel mag man sich denken, dass das unerwartete Ergebnis ja dem Code, den der Programmierer sieht, entspricht und deshalb eventuell sogar besser wäre als das, was eigentlich zu erwarten gewesen wäre. In anderen Beispielen jedoch kann das einen Compilerfehler auslösen:
//Ein Beispiel-Mikroprozessor-Programm. Irgendwo wurden vom Compiler (z.B. in einer Datei <avrio.h>) die folgenden vier Ports definiert: #define PORT0 *((unsigned char *)0x20) #define PORT1 *((unsigned char *)0x24) #define PORT2 *((unsigned char *)0x28) #define PORT3 *((unsigned char *)0x2C) //Damit kann man z.B. PORT0 = 0xFF schreiben. Da 0xFF in Binärdarstellung 11111111 entspricht sind alle 8 Ports auf 1 geschaltet (z.B. 5V) //nun definiert sich der Programmierer ein Makro mit dem Wert des Ports, das er in seiner aktuellen Hardware-Konfiguration als Ausgabepin verwendet //eine Konstante wäre in diesem Fall nicht brauchbar, dazu müsste es z.B. einen port-Pointer geben, der sich über port[number] ansprechen ließe #define OUTPUT_PORT_NUMBER 3 //Damit er OUTPUT_PIN_NUMBER für einen Pin verwenden kann, macht er folgendes: #define PORT(number) PORT##number //Nun schreibt er ein Testprogramm: int main() { PORT(OUTPUT_PORT_NUMBER) = 0xFF; //Hier wird eine Fehlermeldung ausgegeben, z.B. "Nichtdeklarierter Bezeichner 'PORTOUTPUT_PORT_NUMBER'" }Und wieder wäre der Fehler durch
#define PORT(number) PORT_HELPER(number) #define PORT_HELPER(number) PORT##numbervermeidbar gewesen.
Operator-Rangfolge
Das Problem der Operator-Rangfolge ist wohl eines der bekanntesten Probleme beim Präprozessor. Zum Glück ist es meistens einfach zu beseitigen. Nehmen wir folgendes viel zitiertes Beispielmakro:#include <iostream> #define max(a,b) a > b ? a : b int main() { int a = 19; //binär: 10011 int result = max(a & 0xF, 7); }Der Programmierer erwartet hier folgendes: a & 0xF sind die letzten 4 Bits aus a, d.h. 0011 = 3 im Dezimalsystem. 3 ist kleiner als 7, demnach wird sollte 7 ausgegeben werden. Was hier tatsächlich passiert, ist folgendes: Der Code, der sich durch das Makro ergibt, ist folgender:
int main() { int a = 19; //binär: 10011 int result = a & 0xF > 7 ? a & 0xF : 7; }Wenn man die Auswertungsreihenfolge verdeutlicht, dann steht hier nicht etwa
(a & 0xF) > 7, sonderna & (0xF > 7), was wiederum zua & true == a & 1 == 1führt, weswegena & 0xF, was ja bekanntlich 3 ist, zurückgegeben und eben nicht die 7, die eine max()-Funktion eigentlich zurückgeben könnte. Die max()-Funktion ist allerdings gar keine Funktion, was uns zum nächsten unten beschriebenen Problem führt. Dieses Problem hingegen kann wie viele Probleme des gleichen Typs gelöst werden, indem man möglichst viele Klammern (vor allem um die Parameter) setzt:#define max(a,b) ((a) > (b) ? (a) : (b))Genauer gesagt sollte man um alle Parameter Klammern setzen und dann noch einmal um den ganzen Ausdruck herum. Versucht man jetzt hingegen beispielsweise, das Makro mit dem ##-Operator zu verknüpfen, so muss man sich natürlich im Klaren sein, dass die Klammern den Effekt der verknüpften Zeichenfolge völlig verändern kann. Demzufolge sollte man natürlich auch nur bei der Benutzung von Operatoren Klammern setzen.
Mehrfache Auswertung von Parametern
Für dieses Problem ist das obige max()-Makro ein Paradebeispiel.
Angenommen, der Benutzer dieses Makros schreibt folgenden Code:#include <iostream> int main() { int a = 5; std::cout << max(++a, 8) << "\n"; std::cout << a << "\n"; }Nachdem a zuerst um 1 erhöht und dann mit 8 verglichen wird, lautet die Ausgabe wie folgt:
8 6Dieser Code funktioniert auch wie erwartet. Verändert man jedoch nur ein Zeichen des Codes, ergibt sich ein völlig anderes Verhalten:
#include <iostream> int main() { int a = 5; std::cout << max(++a, 3) << "\n"; //die Vergleichszahl ist jetzt kleiner als ++a std::cout << a << "\n"; }Ausgabe:
7 7Warum hat a nicht nachher den Wert 6? Es wurde doch nur einmal inkrementiert...
Falsch. Das Makro benutzt ++a zweimal in seinem Code (
((++a) > (3) ? (++a) : (3))). Das ++a im Vergleich wird immer ausgeführt, das andere hingegen nur, wenn der Vergleich true ergibt, was im zweiten Beispiel der Fall war. Die Lösung hierbei ist, den Makros nicht so viel zuzumuten. Schließlich kann man sich eine inline-Funktion schreiben, die genau die erwünschte Wirkung hat:template<typename T> inline T max(T const &first, T const &second) { return first > second ? first : second; }Kommas in Parametern
Dieses Problem ist zwar nicht unbedingt häufig, aber erst auf den zweiten Blick verständlich.
Wir nehmen noch einmal ein Makro von oben:#define ASSIGN(left, right) \ left = right; \ std::cout << #left " = " #right "; " #left ": " << left << "\n"Nun schreibt ein Programmierer folgenden Code unter Verwendung des Makros:
#include <map> int main() { std::map<std::string, int> first, second; second["begin"] = 1; second["end"] = 2; ASSIGN(first, std::map<std::string, int>(second.begin(), second.end())); }Nun erscheint beim GCC folgender Fehler in Zeile 8:
error: macro "ASSIGN" passed 3 arguments, but takes just 2Der Grund dafür ist, dass der Präprozessor dumm ist. Er kennt keine Templates und < und > sind für ihn nur Vergleichsoperatoren. (), {} und [] haben immer eine klammernde Bedeutung, <> dagegen nur bei Templates. Und da der Präprozessor nicht die ganze Bedeutung des Codes erfassen kann (zum einen aus Zeitgründen, zum anderen, weil die Bedeutung selbst noch durch Makros verändert werden kann), landen bei ihm 3 Parameter:
first,std::map<std::stringundint>(second.begin(), second.end());
Da die Parameterzahl fürrightim Makro ASSIGN() von 1 bis Unendlich variieren könnte, nehmen wir eine variable Argumentliste, um den Fehler zu verhindern:#define ASSIGN(left, ...) \ left = __VA_ARGS__; \ std::cout << #left " = " #__VA_ARGS__ "; " #left ": " << left << "\n"Das ist nicht schön, tut aber seinen Zweck. Allerdings funktioniert dies selbstverständlich nur für den letzten Parameter. Zwei Template-Namen, die Kommas enthalten, können so nicht übergeben werden.
Mehrere Anweisungen in einem Makro können if() durcheinanderbringen
Unerwartete Ersetzung von Trigraphen
Da Trigraphen auch in Stringliteralen ersetzt werden, kann man Stringliteralverknüpfung oder Escaping verwenden, um das Problem zu umgehen:#include <iostream> int main { std::cout << "Was geht hier vor??!\n"; std::cout << "Was geht hier vor\?\?!\n"; std::cout << "Was geht hier vor?" "?!\n"; }Ausgabe:
Was geht hier vor| Was geht hier vor??! Was geht hier vor??!Außerdem kann folgendes zu unerwartetem Verhalten führen:
//Was passiert hier????/ std::cout << "Hello World\n";Antwort: nichts. ??/ ist ein Trigraph, der zu \ ersetzt wird, was den Kommentar auf die nächste Zeile ausdehnt und somit ist die Ausgabeanweisung im Kommentar.
Code in einem #if-Block kann falsch sein und trotzdem kompilieren, solange die Bedingung falsch ist
1.3 Richtlinien für die Verwendung des Präprozessors
+includes
+Include-Guards
+bedingte Kompilierung (auch durch Makefiles etc. teilweise ersetzbar)
+-Debugging
+-X-Makros (http://drdobbs.com/cpp/184401387)
+-"Super-Makros" -> http://wanderinghorse.net/computing/papers/supermacros_cpp.html
-Konstanten statt const-Werten
-Typ-Definitionen statt typedef (define und typedef - umgekehrte Reihenfolge: #define b a <-> typedef a b)-define-guards (ifndef x define x endif)
-keine Rekursion möglich
-man kann keine Adresse nehmen
-man kann schlechter Debuggen
-Was man mit Makros nicht machen kann (s. http://gotw.ca/gotw/077.htm)
(vielleicht auch zu 1.1)variadic macros offiziell nur in C++11 und C99
Funktionen und Aufrufvarianten (-> extern "C", stdcall, fastcall, thiscall, ...)
Für das Verständnis der Umsetzung vieler C++-Features ist grundlegendes Wissen über den Aufbau von Computern und Assembler wichtig.
Ein Computer besteht aus verschiedenen Komponenten: Prozessor, RAM (Arbeitsspeicher), Festplatte, Mainboard, Grafikkarte (optional), Netzwerkkarte, Soundkarte (optional), Lüfter (optional), Netzteil, Bildschirm (optional z.B. bei Servern). (??? Stimmt das?)
Mit Programmiersprachen werden normalerweise nur Prozessor und Arbeitsspeicher direkt angesprochen. Der Rest, den aus Sicht des Durchschnittsprogrammierers irgendwelche zur Verfügung gestellten Funktionen ansprechen, birgt oftmals ein "Geheimnis" für Programmierer. Grundsätzlich werden die meisten anderen Teile vom Betriebssystem angesprochen, das wiederrum Treiber verwendet, die auf hardwarespezifische Kommunikation via Assembler setzen. Hierbei geht es um ganz hardwarenahe Dinge wie etwa Basis-Ein-/Ausschalten von Ausgängen und Auslesen von Eingängen. (??? Stimmt das so?)
(Von-Neumann-Rechner?)
Der Prozessor (CPU = Central Processing Unit) besteht aus einem oder mehreren Kernen, die gleichzeitig Programme oder -teile ausführen. Jeder Kern hat erst einmal Register, auf die von Assembler aus direkt zugegriffen werden kann. Register sind je nach Prozessor unterschiedlich groß, inzwischen meist 32 oder 64 Bit. Es gibt üblicherweise ca. 10-20 davon (??? Sind es immer die gleichen?), sodass man sehr sparsam damit umgehen muss. In "normalen" Programmiersprachen wird der Zugriff auf die Register automatisch geregelt. Der Zugriff auf Register funktioniert unglaublich schnell, da der Platz aber nur sehr klein ist, gibt es eine ganze Speicherhierarchie, die ein unterschiedliches Verhältnis von Schnelligkeit und Speicherplatz(-kosten) bieten. Von schnell/wenig Speicherplatz nach langsam/viel Speicherplatz aufgelistet sehen diese Speicherarten so aus:Register L1-Cache L2-Cache L3-Cache RAM SSD Festplatte Web-SpeicherDie 3 Cache-Arten liegen ebenfalls im Prozessor und werden automatisch für Variablen aus dem RAM verwaltet, die oft benutzt werden. Die, die ganz klein sind und sehr oft benutzt werden, werden eventuell vom Compiler in ein Register "verschoben". Will man nun aber z.B. von einem anderen Kern aus (ein paralleler Thread oder ein anderes Programm) auf diese "verschobenen" Variablen zugreifen, wird das nicht funktionieren. (??? nur die im Register oder auch die im Cache?) Deshalb macht man solche Variablen "volatile" (engl. volatile = flüchtig, sprunghaft, ...). Variablen, die als
volatilemarkiert wurden (z.B. mit der Deklarationvolatile int shared_var;), dürfen vom Compiler nicht in ein Register optimiert werden.
Es gibt auf einem durchschnittlichen Prozessor grob 10-20 Register, an deren Größe oft die Größe einesints angepasst wird. Für die meisten Register gibt es Konventionen, manche Register werden so gut wie immer gleich benutzt, manche Register oft für bestimmte Fälle und viele Register je nach Bedarf. Beispielsweise gibt es ein Register, in dem die Adresse der als nächstes zu verarbeitenden Anweisung gespeichert ist.Weil der Speicher in Bytes unterteilt wird und Zeiger auch nur einzelne Bytes adressieren können, müssen
bool-Variablen auch 1 Byte groß sein, obwohl sie nur 2 Zustände haben können. Oftmals werden statt Containern mit vielenbool-Variablen 8 Werte in 1 Byte gepackt. Das ist z. B. beistd::vector<bool>der Fall. Dadurch entfällt aber auch die Möglichkeit, Referenzen oder Pointer auf die Werte zu speichern. Instd::vector<bool>wird dies durch spezielle Proxy-Typen umgangen. Dennoch bezeichnen manchestd::vector<bool>gar nicht erst als Container.Stack/Heap
->Implementierung als Stack nicht vorgeschrieben, "automatischer Speicher"
Speicher wird in C++ üblicherweise in Stack(dt. Stapel) und Heap(dt. Halde) aufgeteilt. "Üblicherweise" deswegen, weil vom Standard hierzu wenig vorgeschrieben wird. Ich werde aber im Folgenden davon ausgehen, dass die entsprechenden Compiler Stack und Heap verwenden (ich kenne hierzu auch kein Gegenbeispiel). Ein Stack wird auch als LIFO gekennzeichnet, was "Last in first out" oder in etwa "Das letzte eingegangene Element geht als erstes wieder heraus" entspricht. Der Name "Stapel" passt dazu, da man üblicherweise oben etwas darauflegt und die Elemente auch oben wieder herunternimmt.
In C++ liegen alle lokalen Variablen auf dem Stack. Beispiel:int main() { int a = 5; for(int i = 0; i < 10; ++i) { int b = a * i; } }Der Stack könnte (ohne Compileroptimierungen) in Zeile 3 so aussehen:
aIn Zeile 4 kommt die Variable
ihinzu und wird oben auf den Stapel gelegt:i aDanach kommt in einem extra Block die Variable b hinzu:
b i aMit dem Ende des inneren
for()-Blocks in Zeile 8 wird b zerstört, daraufhin schrumpft der Stapel wieder und anschließend werden i und a (in dieser Reihenfolge) zerstört und vom Stapel genommen.
Dabei sind die Bezeichnungen "zerstört" und "vom Stapel genommen" allerdings mit Vorsicht zu genießen.ints haben keinen Destruktor und folglich gibt es nichts zu zerstören. Auch ändert sich die Größe des Stacks nicht. Dem Programm wird zu Beginn ein bestimmter Speicherblock zugewiesen (auf Desktop-Betriebssystemen vielleicht 1 MB) und ein Zeiger, der vom Compiler automatisch verwaltet wird, zeigt immer auf das Ende des benutzten Stackbereiches. (Hinweis: Es ist gut möglich, dass der Stack umgekehrt verwendet wird, d.h. hohe Speicheradressen = unten im Stapel und niedrige Speicheradressen = oben im Stapel. Dies wird allerdings hier vernachlässigt)
Nehmen wir jetzt folgenden Code:int main() { int a = 5; if(a > 2) { int b = 7; } if(a < 42) { int c; //Ups, uninitialisiert (c wurde kein Wert zugewiesen) } }Ein Möglicher Programmstack (diesmal mit Werten statt Variablennamen) könnte so aussehen:
Zeile 3:
... uninitialized (irgendein Wert) uninitialized (irgendein Wert) uninitialized (irgendein Wert) uninitialized (irgendein Wert) uninitialized (irgendein Wert) 5 <-- Stack-Pointer zeigt hierhinZeile 6:
... uninitialized (irgendein Wert) uninitialized (irgendein Wert) uninitialized (irgendein Wert) uninitialized (irgendein Wert) 7 <-- Stack-Pointer zeigt hierhin 5Zeile 8:
... uninitialized (irgendein Wert) uninitialized (irgendein Wert) uninitialized (irgendein Wert) uninitialized (irgendein Wert) 7 (Warum sollte der Compiler diesen Wert ändern? Es wäre nur unnötiger Aufwand, denn 7 ist auch "irgendein Wert" = uninitialized) 5 <-- Stack-Pointer zeigt hierhinZeile 11:
... uninitialized (irgendein Wert) uninitialized (irgendein Wert) uninitialized (irgendein Wert) uninitialized (irgendein Wert) 7 <-- Stack-Pointer zeigt hierhin (c hat den Wert von b vorher, da c nichts zugewiesen wurde) 5Natürlich kann und sollte man sich nicht darauf verlassen (warum auch?). Ein ähnliches Beispiel (mit zusätzlichen Optimierungs-Verhinderungen und Ausgaben) zeigt, dass sich das Ganze beim GCC so verhält. (zumindest auf diesem Computer mit dieser MinGW-Version um diese Uhrzeit mit diesem Betriebssystem und dieser Speicherauslastung, denn garantiert ist ja nichts)
Etwas komplizierter wird die Stackverwaltung bei Funktionsaufrufen.
-> http://www.angelcode.com/dev/callconv/callconv.html
-> http://msdn.microsoft.com/en-us/library/zkwh89ks(v=VS.71).aspx (varargs)
Es gibt verschiedene Aufrufkonventionen für Funktionen, die sich z.B. darin unterscheiden, wie etwas zurückgegeben wird, wie die Argumente auf den Stack gelegt werden und wer den Stack wieder aufräumt. Ich werde das im Folgenden noch genauer erklären. Nehmen wir folgendes Beispiel:#include <iostream> int func(int a, int b) { return a + b; } int main() { int a = 5; return func(a, 7); //gibt 12 zurück }In wenig optimiertem Maschinen-Pseudocode könnte dieses Programm etwa so aussehen:
(Hinweis: das Legen auf den Stack/Laden vom Stack mit dem Stack-Pointer ist natürlich mit einer entsprechenden Erhöhung/Erniedrigung des Stack-Pointers verbunden)Funktion "_func": Lege den alten Base-Pointer-Wert auf den Stack Lege die Stack-Adresse des alten Base-Pointer-Werts in den neuen Base-Pointer Lade die beiden Werte, die vor der Adresse stehen, auf die der Base-Pointer zeigt, in eax bzw. ebx. Jetzt liegt also der Wert von a in eax und 7 in ebx. Addiere ebx zu eax (eax += ebx) Da der Rückgabewert ein int ist, muss er per Konvention in eax zurückgegeben werden. Da unser Resultat ebenfalls in eax liegt, muss nichts mehr verschoben werden. Lade den alten Base-Pointer-Wert wieder von der Adresse, auf die der Base-Pointer jetzt zeigt, und speichere ihn im Base-Pointer ab (damit die aufrufende Funktion wieder ihren alten Base-Pointer-Wert hat) Springe zu dem Code, auf den *(Stackpointer - sizeof(Pointer in den Code)) verweist (Genauer gesagt, lege die Rücksprungadresse in das Register mit dem "instruction pointer", also dorthin, wo der Prozessor den Ort des nächsten Befehls ausliest (normalerweise wird es einfach immer erhöht)) Funktion "_main": (also die main()-Funktion) Lege 5 auf den Stack Lade den Wert von a in das Register eax Lege 7, dann den Wert des Registers eax (umgekehrte Parameterreihenfolge) und dann die Adresse der nächsten Codezeile (für den Rücksprung der Funktion) auf den Stack Springe zum Funktionscode mit Namen "_func" Ziehe sizeof(Pointer auf Code) + sizeof(a) + sizeof(7) wieder vom Stack-Pointer ab Gebe den Wert von eax zurück (Programmrückgabe aus der Main-Funktion ist etwas spezielles) (??? Ist das wirklich was spezielles oder liest das Betriebssystem auch einfach eax aus?) Verlasse das Programm(??? Stimmt das so?)
Nun ist hier mehr oder weniger auffällig, dass der Rückgabewert der Funktion in einem Register zurückgegeben wird. Da nicht alle Rückgabevariablen in Register passen, werden Objekte üblicherweise ab einer Größe von über 8 Bytes (mehr als 2 Register) in einen Bereich gespeichert, den die aufrufende Funktion vorher reserviert hat. Dieser wird der aufgerufenen Funktion per verstecktem Zeiger mitgeteilt. Im Zusammenhang mit copy elision (siehe unten) können Funktionsrückgaben daher oft effizienter geschehen, als dies auf den ersten Blick zu vermuten wäre.
Eine logische Vorgabe für die Bennung von Funktionen in Assemblercode ist, dass zwei Funktionen nicht den gleichen Namen haben dürfen. Trotzdem ist dies in C++ nicht der Fall. Funktionen können nämlich überladen werden. Wenn mehrere gleichnamige Funktionen unterschiedliche Parameteranzahlen oder -typen besitzen, kann der Compiler oftmals beim Aufruf entscheiden, welche der Funktionen aufgerufen werden soll. Nur wenn es mehrere Funktionen gibt, die gleich gut oder schlecht passen, ist der Aufruf mehrdeutig (engl. ambiguous). In diesem Fall wird eine Fehlermeldung ausgegeben.
Beispiel:
void f(int x){} void f(double x){} void g(long x){} void g(double x){} void g(double x, double y){} int main() { f(5); //ruft f(int) auf f(5.0); //ruft f(double) auf g(5); //Fehler: Der Compiler kann sich nicht entscheiden, ob der int-Wert 5 nun zu einem long oder einem double konvertiert werden soll g(7, 10.0); //eindeutig wegen Parameteranzahl, kein Fehler }Um die verschiedenen gleichnamigen Funktionen im Assemblercode auseinanderhalten zu können, kann der Compiler z.B. Informationen über die Parametertypen an die C++-Funktionsnamen hängen. Aus der den beiden Funktionen könnten die Funktionen
f_intundf_doublegeneriert werden. Natürlich muss der Compiler darauf achten, dass es nicht zu Namensproblemen kommt, falls der Benutzer eine Funktionf_intin seinem Code verwendet. Der Compiler könnte dazu z.B. Escaping verwenden, also das Verfahren, das auch bei Strings benutzt wird, um"im String selbst verwenden zu können. Zum Beispiel könnten die Funktionen dann im Assemblercodef_Zintundf_Zdoubleheißen und eine Funktionf_Zintim Code dannf_ZZint(wenn der Compiler dasZwie das\in Strings verwendet).Die Tatsache, dass im Maschinencode keine explizite Typisierung existiert (höchstens Vorgaben für die Größe von Variablen für bestimmte Operationen), macht es dem Compiler leicht, Code für zusammengesetzte Datenstrukturen zu generieren. Er muss lediglich die verschiedenen Variablen einer Datenstruktur im Speicher hintereinanderhängen. Dabei kann es allerdings zu Padding/Alignment kommen: Da der Zugriff auf Variablen im RAM, deren Adresse ein Vielfaches von 4 ist, oft schneller ist, ist es dem Compiler freigestellt, Lücken zwischen den einzelnen Variablen zu lassen, um sie effizienter auszurichten. Dies kann jedoch zu Problemen mit Speicherplatz (bei Benutzung sehr vieler Objekte der Struktur) und zwischen dem Code verschiedener Compiler führen, weswegen viele Compiler die Präprozessordirektive
#pragma packanbieten, die das Einfügen von Lücken in Datenstrukturen verbietet.Auch Klassen sind in ihrer Umsetzung den Datenstrukturen aus C ähnlich. Lediglich bei der Verwendung virtueller Funktionen und der Vererbung kommen neue Mechanismen hinzu.
Nehmen wir folgenden Code:class IntPair { public: int a; int b; void ABMultN(int n) { a *= n; b *= n; } int Add() const { return a + b; } }; int main() { IntPair i; i.a = 5; i.b = 7; ABMultN(2); return i.Add(); //gibt 24 zurück }Der generierte Code könnte in etwa dem folgenden C-Code entsprechen:
struct IntPair { int a; int b; }; void IntPair_ABMultN(IntPair * const this, int n) { this->a *= n; this->b *= n; } int IntPair_Add(const IntPair * const this) { return this->a + this->b; } int main() { IntPair i; i.a = 5; i.b = 7; IntPair_ABMultN(&i, 2); return IntPair_Add(&i); //gibt 24 zurück }Anfänger-Info:
Das const vor IntPair bedeutet, dass das IntPair, auf das der Zeiger zeigt, für die Funktion unveränderich ist.
Das const nach * bedeutet, dass die im Pointer gespeicherte Adresse nicht verändert werden kann (alsothis = &other;nicht funktioniert).
*Die Verwendung von Funktionen hat also fürs Erste keinen Einfluss auf die Größe des Objekt. Trotzdem muss die Größe einer Klasse nicht der Summe der Größen ihrer Member entsprechen. Der Compiler kann sogenanntes Alignment oder Padding vornehmen, d.h. er fügt Lücken zwischen den einzelnen Membern ein. Das liegt daran, dass bei vielen Computern auf Adressen, die Vielfache von 4 sind, schneller zugegriffen werden kann. Also kann ein Objekt, das 4 chars enthält, 16 Bytes groß sein, damit jeder char an einer Adresse liegt, die ohne Rest durch 4 teilbar ist. Problematisch wird das bei hohen Speicheranforderungen oder bei der Kommunikation zwischen Programmen, die von unterschiedlichen Compilern kompiliert wurden und demnach ein gleiches Speicherlayout ihrer Klassen benötigen. In gewissen Fällen kann es hilfreich sein, gleiche Daten in einem Array zusammenzufassen (bei Arrays ist kein Padding erlaubt). Ansonsten verwendet man compilerspezifische Befehle, die das Padding unterbinden. Beispielsweise wird hier von manchen Compilerherstellern der Befehl #pragma pack angeboten. Genauere Informationen dazu gibt es im Internet.
Auch eine "leere" Klasse ohne Variablen muss zudem immer eine Größe von mindestens 1 Byte besitzen.Eine Sache, die C++-Klassen einen entscheidenden Vorteil vor C-Strukturen verleihen, sind Konstruktoren und Destruktoren.
Ein Konstruktor wird bei der Erstellung eines Objektes ausgeführt, während ein Destruktor ausgeführt wird, wenn die Lebensdauer des Objektes zu Ende ist.
Beispiel:#include <iostream> class Test { Test() // Konstruktor { std::cout << "Konstruktor\n"; } ~Test() // Destruktor { std::cout << "Destruktor\n"; } void print() { std::cout << "Test\n"; } }; int main() { Test test; // Konstruktor wird aufgerufen std::cout << "main()\n"; } // Destruktor wird aufgerufenDie Ausgabe lautet nun:
Konstruktor main() DestruktorEs gibt folgende Möglichkeiten, ein Objekt zu erstellen und wieder zu löschen:
// In einem Scope/Gültigkeitsbereich, der durch { und } begonnen / beendet wird, // werden am Ende alle lokalen Variablen zerstört, d.h. der Destruktor wird aufgerufen. // { und } ohne if, for oder Ähnliches kommen selten vor, sind aber durchaus erlaubt. void VariableImScope() { { { } { Test test; // Konstruktor wird aufgerufen // Tue irgendwas } // Destruktor wird aufgerufen { } } } void TemporaereVariable() { // Durch Test() wird ein Objekt vom Typ Test erstellt, // dann wird print() darauf aufgerufen // und dann wird das Objekt wieder zerstört Test().print(); /* Ausgabe: Konstruktor Test Destruktor */ } void DynamischeVariable { // Ein neues Objekt vom Typ Test wird auf dem Heap erstellt und der Konstruktor wird aufgerufen // Die Adresse des Objektes wird in test_ptr geschrieben Test *test_ptr = new Test(); // Tue irgendwas // Destruktor wird aufgerufen, ohne das delete würde der Destruktor nie aufgerufen werden delete test_ptr; } void DynamischesArray { // 5 Objekte vom Typ Test werden auf dem Heap erstellt und die Konstruktoren aller Elemente werden aufgerufen // Die Adresse des ersten Objektes wird in test_ptr geschrieben Test *test_ptr = new Test[5]; // Tue irgendwas // Destruktoren aller Elemente werden aufgerufen // Ohne das delete[] würden die Destruktoren nicht aufgerufen werden // Es muss delete[] und nicht delete verwendet werden delete[] test_ptr; } struct TestHolder { Test test; }; void Member() { // der Konstruktor von TestHolder wird aufgerufen, dieser ruft automatisch den Konstruktor von Test auf TestHolder holder; // Tue irgendwas } //holder wird zerstört, im Destruktor von holder wird der Destruktor von holder.test aufgerufen // Es wird eine globale Variable erstellt // Noch vor dem Aufruf von main() wird der Konstruktor von global_test aufgerufen. // Der Destruktor wird nach dem Beenden von main() aufgerufen. // Gleiches gilt für statische Klassenvariablen und globale Variablen in namespaces (??? Stimmt hoffentlich?!) // ACHTUNG: Es ist im allgemeinen nicht gut, globale Variablen zu verwenden (mehr dazu siehe unten) Test global_test; void StatischeFunktionsvariable() { // test wird erst beim ersten Aufruf der Funktion erstellt // der Destruktor wird nach dem Beenden von main() aufgerufen static Test test; } void BitteNichtNachmachen() { // ACHTUNG: Bitte nicht nachmachen // Auf diese Weise erreicht man ziemlich genau das Gleiche wie mit new und delete, nur deutlich fehleranfälliger // Speicher für ein Objekt vom Typ Test auf dem Heap anfordern Test *test_ptr = (Test *)operator new(sizeof(test)); // Mit "placement new" an dieser Speicherstelle den Konstruktor von Test aufrufen new(test_ptr) Test(); // Tue irgendwas // Den Destruktor aufrufen test_ptr->~Test(); // Den Speicher wieder freigeben operator delete(test_ptr); }Aufruf von Destruktoren in der umgekehrten Erstellungsreihenfolge (begründendes Beispiel)
Ein Konstruktor ist eine Art Funktion, die automatisch bei der Erstellung eines Objekts ausgeführt wird. Dabei besitzt ein Konstruktor wie ein Destruktor keinen Rückgabetyp, im Gegensatz zum Destruktor ist der Konstruktor aber keine Funktion, die auf ein bestehendes Objekt aufgerufen werden kann, da er selbst das Objekt erstellt. Demnach hat er auch keine Funktionsadresse. Zudem haben Konstruktoren eine Initialisierungsliste, in der Membervariablen mit Startwerten belegt werden können. Die Membervariablen müssen aber immer in der Reihenfolge ihrer Deklaration in der Klasse initialisiert werden (sind sie in der Initialisierungsliste anders herum, macht es der Compiler trotzdem in dieser Reihenfolge. Das kann zum Problem werden, wenn einige Membervariablen mithilfe der Werte anderer Membervariablen initialisiert werden (obwohl diese je nach Reihenfolge möglicherweise noch gar nicht initialisiert sind). Denn der Compiler muss gewährleisten, dass die Objekte im Destruktor umgekehrt zu ihrer Erstellungsreihenfolge wieder zerstört werden.
Konstruktion bei globalen Variablen (Problem mit std::cout/std::cin)
throw in Konstruktoren
try-catch-Blöcke auf Funktionsebene
Funktionspointer
Klassen
virtuelle Vererbung
virtuelle Funktionen -> http://www.c-plusplus.net/forum/300063Die Umsetzung von virtuellen Funktionen ist etwas schwieriger. Hierzu braucht man eine Tabelle von Funktionspointern für die jeweilige Klasse, die sich je nach Typ des Objekts unterscheidet.
Test.h
//Test.h class Base { public: virtual ~Base(){} virtual void foo(); }; class Derived : public Base { public: virtual ~Derived(){} virtual void foo(); };Test.cpp
#include "Test.h" #include <iostream> void Base::foo() { std::cout << "Base\n"; } void Derived::foo() { std::cout << "Derived\n"; }main.cpp
#include "Test.h" int main() { Base b; Derived d; Base *b_ptr = &b, *d_ptr = &d; b_ptr->foo(); //gibt "Base\n" aus d_ptr->foo(); //gibt "Derived\n" aus }Der Compiler behandelt diese Dateien in etwa wie die folgenden C-Dateien:
(die iostreams habe ich der Einfachheit halber nicht durch printf ersetzt)Test.h
typedef void (*basic_function_pointer_type)(); struct Base { basic_function_pointer_type *vtable_for_Base; }; void Base_construct(Base * const ptr); void Base_destruct(Base * const ptr); void Base_foo(Base * const this_ptr); struct Derived { basic_function_pointer_type *vtable_for_Base; }; void Derived_construct(Derived * const ptr); void Derived_destruct(Base * const ptr); void Derived_foo(Base * const this_ptr);Test.cpp
#include "Test.h" #include <iostream> // Die Ausgabe lasse ich jetzt mal in C++ basic_function_pointer_type Base_vtable_for_Base[] = {(basic_function_pointer_type)&Base_destruct, (basic_function_pointer_type)&Base_foo}; basic_function_pointer_type Derived_vtable_for_Derived[] = {(basic_function_pointer_type)&Derived_destruct, (basic_function_pointer_type)&Derived_foo}; void Base_construct(Base * const ptr) { ptr->vtable_for_Base = Base_vtable_for_Base; } void Base_destruct(Base * const ptr) { //Tue die Arbeit von Base } void Base_foo(Base * const this_ptr) { Base * const this = this_ptr; std::cout << "Base\n"; } void Derived_construct(Derived * const ptr) { Base_construct((Base*) ptr); ptr->vtable_for_Base = Derived_vtable_for_Base; } void Derived_destruct(Base * const ptr) { Base_destruct(ptr); //Tue die Arbeit von Derived } void Derived_foo(Base * const this_ptr) { Derived * const this = (Derived*)this_ptr; std::cout << "Derived\n"; }main.cpp
#include "Test.h" int main() { Base b; Base_construct(&b); Derived d; Derived_construct(&d); Base *b_ptr = &b, *d_ptr = (Base*)&d; typedef void (*foo_function_type)(Base * const); //Funktionstyp der Funktionen Base/Derived + _ + foo/destruct (*((foo_function_type)(b_ptr->vtable_for_Base[1])))(b_ptr); //gibt "Base\n" aus (*((foo_function_type)(d_ptr->vtable_for_Base[1])))(d_ptr); //gibt "Derived\n" aus Derived_destruct((Base*)&d); Base_destruct(&b); }Natürlich kann der Compiler hier ein gleiches Layout der Klassen Derived und Base garantieren, ein C-Programmierer hingegen nicht (siehe z.B. Padding/Alignment).
Eine wichtige Einschränkung, die sich durch die Funktionstabelle ergibt, ist die Tatsache, dass bei einem Aufruf einer virtuellen Funktion in einem Konstruktor nicht unbedingt die richtige Funktionsversion aufgerufen wird. Nehmen wir an, wir hätten wieder die Klassen
Base und Derived, wobei im Konstruktor von Base die virtuelle Funktionfunc()aufgerufen wird. Nun hat der Konstruktor von Derived folgende Aufgaben:
-vtable-Pointer initialisieren
-Basisklassenkonstruktor aufrufen (entfällt bei Base, aber wir könnten ja genausogut Base von einer anderen Klasse erben lassen)Somit gibt es 2 Möglichkeiten, wann der vtable-Pointer initialisiert werden kann:
-vor dem Aufruf des Basisklassenkonstruktors: Dann wird der vtable-Pointer zuerst im Derived-Konstruktor auf die Funktionstabelle von Derived gesetzt und anschließend im Basisklassenkonstruktor auf die Funktionstabelle von Base. Die Initialisierung wäre also falsch.
-nach dem Aufruf des Basisklassenkonstruktors: Im Basisklassenkonstruktor ist der vtable-Pointer noch auf die Base-Funktionstabelle gesetzt und der Aufruf von func() trotzdem falsch.Es gibt durchaus andere Möglichkeiten, den vtable-Pointer richtig zu initialisieren. Zum Beispiel könnte der Compiler bei einem Konstruktoraufruf den vtable-Pointer als (versteckten) Parameter übergeben. Dann wäre beim Aufruf von func() in Base zwar der vtable-Pointer richtig gesetzt, aber die Variablen von Derived wären noch gar nicht initialisiert. Letztendlich würden virtuelle Funktionen in Konstruktoren also auf das gleiche Problem herauslaufen wie die Initialisierungsreihenfolge globaler Variablen (siehe unten ???).
Initialisierungsreihenfolge globaler Variablen
Pointer-Konvertierungen: Derived* -> void* -> Base*
inline, static und namespace{} -> HeaderÜberladung
Durch Überladung kann man in C++ mehreren Funktionen den gleichen Namen geben. Damit der Compiler dennoch weiß, welche Funktion im konkreten Fall aufgerufen werden muss,
Templates
Überladung->Argument matching: http://gotw.ca/gotw/049.htm
http://gotw.ca/gotw/030.htm
-> Koenig Lookup -> http://gotw.ca/publications/mill02.htm
-> Operator für eine Klasse in einem namespace muss auch im namespace deklariert worden sein für z.B. std::less?Lambda-Funktionen (ab C++11)
Referenzen
Rvalue-Referenzen
->Overload Resolution: https://blogs.msdn.com/b/vcblog/archive/2009/02/03/rvalue-references-c-0x-features-in-vc10-part-2.aspxUndefined Reference/nicht aufgelöstes externes Symbol
Wie funktionieren Files/Bildschirmansteuerung/...
g++ = gcc + C++-Libraries
Optimierungen:
inline
"tote" Variablen/Bedingungen eliminieren
RVO/NRVO http://stupefydeveloper.blogspot.com/2008/10/c-rvo-and-nrvo.htmlPODs und nicht-PODs
Padding/Alignment
Leere Klassen müssen mindestens 1 Byte groß sein -> 2 Objekte haben nie die gleiche Adresse -> bei leeren Basisklassen kann das wieder wegfallen (Empty Base Class Optimization)
Exceptions
Konstruktoren (failure, Exceptions, function-try-block, ...)
Defaultwerte
volatile
new/delete
typename
mehrdimensionale C-Arrays
variable Argumentlisten in C (mit cdecl-Aufrufkonvention)http://gotw.ca/gotw/011.htm
-> Pointer in String-LiteraleRTTI
vector<bool>
Debugging-Symbole
Reihenfolge von Abhängigkeiten in Archiven (Wichtigkeit der richtigen Linkreihenfolge von Archiven)
TODO: Digraph-Support in C++ nochmal überprüfen (wg. Beispiel mit std::vector<::std::string> in C++)
floating-Point-Zahlen
rebase für DLLs?
ABI (Application Binary Interface) in C und C++
reservierte Symbole: http://www.c-plusplus.net/forum/p2123094#2123094
http://www.c-plusplus.net/forum/293147
switch: http://www.codeproject.com/KB/cpp/switch.aspx
http://www.slideshare.net/olvemaudal/deep-c
If a class is defined in a header file and has a v-table (either it has virtual methods or it derives from classes with virtual methods), it must always have at least one out-of-line virtual
-
-
Sehr interessant bisher, freue mich darauf den bald vollständig lesen zu dürfen
")
-
Ich habe jetzt nur Kapitel 0 (also Inhaltsverzeichnis und Übersichtsgrafik) gelesen, keine Zeit im Moment für mehr. Kleinigkeit gefunden: Ist der traditionelle Name für compilierte, aber nicht assemblierte, Dateien nicht name.s? Ist zumindest bei sämtlichen in Linux verbreiteten Compilern so. Sollte man vielleicht noch zusätzlich aufführen, falls dies auf anderen Plattformen .asm heißt.
-
SeppJ schrieb:
Ich habe jetzt nur Kapitel 0 (also Inhaltsverzeichnis und Übersichtsgrafik) gelesen, keine Zeit im Moment für mehr. Kleinigkeit gefunden: Ist der traditionelle Name für compilierte, aber nicht assemblierte, Dateien nicht name.s? Ist zumindest bei sämtlichen in Linux verbreiteten Compilern so. Sollte man vielleicht noch zusätzlich aufführen, falls dies auf anderen Plattformen .asm heißt.
Danke, zu wenig nachgedacht
")
-
*push* Kleines Update im oberen Beitrag und Fragen mit (??? <Frage>) markiert (steht auch in der Einleitung)
-
Ich denke du solltest das aufsplitten und wenn du das nicht willst, dann auf jeden Fall kompakter schreiben, denn so wird das kaum jemand lesen. War ein Fehler damals, dass manche Artikel so lang waren. Das schreckt einfach schon beim Lesen ab. Sowohl für Leute die es Korrekturlesen sollen, als auch die eigentliche Zielgruppe am Ende
-
GPC schrieb:
Ich denke du solltest das aufsplitten und wenn du das nicht willst, dann auf jeden Fall kompakter schreiben, denn so wird das kaum jemand lesen.
Das sehe ich nicht so.
-
volkard schrieb:
GPC schrieb:
Ich denke du solltest das aufsplitten und wenn du das nicht willst, dann auf jeden Fall kompakter schreiben, denn so wird das kaum jemand lesen.
Das sehe ich nicht so.
Sondern (argumentativ)?
Ich denke, man könnte das schon aufsplitten (bei der Länge, die das noch bekommen soll) und versuchen, vor allem den ersten Teil nicht so lang und dafür interessant zu machen (vielleicht auch eine Übersicht), damit die Leute- den Sinn der Ausführlichkeit verstehen
- Interesse bekommen
- bei Interesse an bestimmten Themen den Artikel nicht ganz lesen müssen
Ich werde den Artikel aber voraussichtlich erst relativ spät bei klarer Strukturierung aufsplitten, mit den Korrekturlesern habe ich nicht so viel Mitleid, wenn sie meinen, den ganzen Artikel lesen zu müssen und sich davon abschrecken lassen.

-
wxSkip schrieb:
volkard schrieb:
Das sehe ich nicht so.
Sondern (argumentativ)?
ICH kann mich nicht in einen Leser hinenversetzen, der so denkt.
-
volkard schrieb:
wxSkip schrieb:
volkard schrieb:
Das sehe ich nicht so.
Sondern (argumentativ)?
ICH kann mich nicht in einen Leser hinenversetzen, der so denkt.
Dann denk mal an einen von diesen Schülern/Elektrotechnikstudenten/..., die meinen, C++ lernen zu müssen, aber es eigentlich gar nicht wollen, und halt ihnen 2 Bücher hin: "C++ in 21 Tagen" und "C++ Primer". Was glaubst du, werden sie nehmen?
-
Ok, wenn Du bewußt entscheidest, daß es für die Zielgruppe besser ist, will ich nichts gesagt haben.
-
volkard schrieb:
Ok, wenn Du bewußt entscheidest, daß es für die Zielgruppe besser ist, will ich nichts gesagt haben.
Das ist doch okay, wenn du etwas sagst. Ich muss das dann später schauen. Jedenfalls habe ich es jetzt mindestens einem Recht gemacht, egal wie ich es mache. Aber ich nehme an, wenn der Compilerbau-Artikel 1600 Zeilen hat, dieser hier schon 800 und am Ende vielleicht 3000 oder 5000 ist dir eine Aufsplittung auch nicht unrecht.
-
Update: Assembler-Funktionsaufruf-Pseudocode berichtigt (hoffe ich jedenfalls).
-
Update: Einige neue Beispielcodes und Erläuterungen zu Klassen am Ende des Artikels.